基于广义神经网络的网络入侵检测Matlab代码
1.案例背景
1.1 FCM 聚类算法
聚类方法是数据挖掘中经常使用的方法,它将物理的或抽象的对象分为几个种群,每个种群内部个体间具有较高的相似性,不同群体内部间个体相似性较低。模糊c均值聚类算法(Fuzzy C- Mean, FCM)是用隶属度确定每个元素属于某个类别程度的一种聚类算法,FCM算法把n个数据向量xk,分为c个模糊类,并求每类的聚类中心,从而使模糊目标函数最小,模糊聚类目标函数为

FCM聚类算法迭代过程如下:
步骤1:给定类别数c,模糊权重指数m。步骤2:初始聚类中心v。
步骤3:根据式(34-2)计算模糊隶属度矩阵u。
步骤4:根据式(34-3)计算每类中心v。
步骤5:根据式(34-1)计算模糊聚类目标值,判断是否满足结束条件,满足则算法终止,否则返回步骤3。
FCM算法最终得到了模糊隶属度矩阵u,个体根据隶属度矩阵每列最大元素位置判断个体所属类别。
1.2 广义神经网络
1.3 网络入侵检测
常规的入侵检测方法可以按检测对象、检测方法和实时性等方面进行分类。其中,按检测对象可以分为基于主机的入侵检测系统、基于网络的入侵检测系统和混合型人侵检测系统;按检测方法可以分为误用检测和异常检测;按定时性可以分为定时系统和实时系统。近年来,研究人员又提出了一些新的人侵检测方法,比如基于归纳学习的入侵检测方法、基于数据挖掘的人侵检测方法、基于神经网络的人侵检测方法、基于免疫机理的入侵检测方法和基于代理的入侵检测方法等。其中,基于数据挖掘的入侵检测方法是采用数据挖掘中的关联分析,序列模式分析、分类分析或聚类分析来处理数据,从中抽取大量隐藏安全信息,抽象出用于判断和比较的模型,然后利用模式识别入侵行为。
2.模型建立

算法流程中各个模块的作用如下:
模糊聚类模块用模糊聚类算法把人侵数据分为n类,并得到每类的聚类中心和个体模糊隶属度矩阵u。
网络训练初始数据选择模块根据模糊聚类的结果选择最靠近每类中心的样本作为广义神经网络聚类训练样本。首先求每类的类内均值![]() (i=1,2…,n),然后求解每类中所有样本X到中心值
(i=1,2…,n),然后求解每类中所有样本X到中心值![]() (i=1,2,…,n)的距离矩阵
(i=1,2,…,n)的距离矩阵![]() (i=1,2,…,n),从距离矩阵
(i=1,2,…,n),从距离矩阵![]() (i=1,2,…,n)中选择距离最小的m个样本作为一组,设定其对应的网络输出为i。这样就得到了nXm组训练数据,其输入数据为网络人侵特征数据,输出数据为该人侵行为所属入侵类别。
(i=1,2,…,n)中选择距离最小的m个样本作为一组,设定其对应的网络输出为i。这样就得到了nXm组训练数据,其输入数据为网络人侵特征数据,输出数据为该人侵行为所属入侵类别。
广义神经网络训练模块用训练数据训练广义神经网络。
广义神经网络预测模块用训练好的网络预测所有输入样本数据X的输出序列Y。
网络训练数据选择模块根据预测输出把入侵数据重新分为n类,并从中找出最靠近每类中心值的样本作为训练样本。首先按照网络预测输出序列Y把样本数据X分为n类,然后求出每类内所有样本平均值![]() (i=1,2,…,n),求解出所有样本X到中心值
(i=1,2,…,n),求解出所有样本X到中心值![]() (i=l,2,…,n)的距离矩阵
(i=l,2,…,n)的距离矩阵![]() (i=1,2,…,n),从距离矩阵
(i=1,2,…,n),从距离矩阵![]() (i=1,2,…,n)选择距离最小的m个样本作为一组,设定其对应的网络输出为i。这样再次得到了n×m组网络训练数据,其输人数据为网络入侵提取数据,输出数据为该个体所属入侵类别。
(i=1,2,…,n)选择距离最小的m个样本作为一组,设定其对应的网络输出为i。这样再次得到了n×m组网络训练数据,其输人数据为网络入侵提取数据,输出数据为该个体所属入侵类别。
本案例的数据来自5种网络入侵数据,算法的目的是能够对这5种人侵数据进行有效聚类。
3.编程实现
根据FCM聚类算法和广义神经网络原理,在MATLAB中编程实现基于神经网络的聚类算法,用神经网络对5种网络入侵数据进行聚类,以达到分类5种网络入侵数据的目的。
本案例中使用了模糊聚类函数fcm()、广义神经网络训练函数newgrnn()和预测函数sim(),这3个函数的介绍如下。
1. fcm:模糊聚类函数
函数功能:对数据进行模糊聚类。
函数形式:[CENTER,U,OBJ_FCN] = fcm(DATA,N_CLUSTER)
其中,DATA指待聚类数据;N_CLUSTER 指聚类类别数目;CENTER 指聚类中心;U指样本隶属度矩阵;OBJ_FCN指聚类目标函数值。
2. newgrnn:广义神经网络训练函数
函数功能:用训练数据训练广义神经网络。
函数形式:net = newgrnn(P,T,SPREAD)
其中,P指训练输人数据;T指训练输出数据;SPREAD指网络节点密度;net 指训练好的广义神经网络。
3.sim:广义神经网络预测函数
函数功能:用训练好的广义神经网络预测输出。
函数形式:Y= sim(net,P)
其中,net 指训练好的网络;P指网络输人;Y指预测输出。
完整Matlab代码如下:
%% 该代码为基于FCM-GRNN的聚类算法
%% 清空环境文件
clear all;
clc;
%% 提取攻击数据
%攻击样本数据
load netattack;
P1=netattack;
T1=P1(:,39)';
P1(:,39)=[];
%数据大小
[R1,C1]=size(P1);
csum=20; %提取训练数据多少
%% 模糊聚类
data=P1;
[center,U,obj_fcn] = fcm(data,5);
for i=1:R1
[value,idx]=max(U(:,i));
a1(i)=idx;
end
%% 模糊聚类结果分析
Confusion_Matrix_FCM=zeros(6,6);
Confusion_Matrix_FCM(1,:)=[0:5];
Confusion_Matrix_FCM(:,1)=[0:5]';
for nf=1:5
for nc=1:5
Confusion_Matrix_FCM(nf+1,nc+1)=length(find(a1(find(T1==nf))==nc));
end
end
%% 网络训练样本提取
cent1=P1(find(a1==1),:);cent1=mean(cent1);
cent2=P1(find(a1==2),:);cent2=mean(cent2);
cent3=P1(find(a1==3),:);cent3=mean(cent3);
cent4=P1(find(a1==4),:);cent4=mean(cent4);
cent5=P1(find(a1==5),:);cent5=mean(cent5);
%提取范数最小为训练样本
for n=1:R1;
ecent1(n)=norm(P1(n,:)-cent1);
ecent2(n)=norm(P1(n,:)-cent2);
ecent3(n)=norm(P1(n,:)-cent3);
ecent4(n)=norm(P1(n,:)-cent4);
ecent5(n)=norm(P1(n,:)-cent5);
end
for n=1:csum
[va me1]=min(ecent1);
[va me2]=min(ecent2);
[va me3]=min(ecent3);
[va me4]=min(ecent4);
[va me5]=min(ecent5);
ecnt1(n,:)=P1(me1(1),:);ecent1(me1(1))=[];tcl(n)=1;
ecnt2(n,:)=P1(me2(1),:);ecent2(me2(1))=[];tc2(n)=2;
ecnt3(n,:)=P1(me3(1),:);ecent3(me3(1))=[];tc3(n)=3;
ecnt4(n,:)=P1(me4(1),:);ecent4(me4(1))=[];tc4(n)=4;
ecnt5(n,:)=P1(me5(1),:);ecent5(me5(1))=[];tc5(n)=5;
end
P2=[ecnt1;ecnt2;ecnt3;ecnt4;ecnt5];T2=[tcl,tc2,tc3,tc4,tc5];
k=0;
%% 迭代计算
for nit=1:10%开始迭代
%% 广义神经网络聚类
net = newgrnn(P2',T2,50); %训练广义网络
a2=sim(net,P1') ; %预测结果
%输出标准化(根据输出来分类)
a2(find(a2<=1.5))=1;
a2(find(a2>1.5&a2<=2.5))=2;
a2(find(a2>2.5&a2<=3.5))=3;
a2(find(a2>3.5&a2<=4.5))=4;
a2(find(a2>4.5))=5;
%% 网络训练数据再次提取
cent1=P1(find(a2==1),:);cent1=mean(cent1);
cent2=P1(find(a2==2),:);cent2=mean(cent2);
cent3=P1(find(a2==3),:);cent3=mean(cent3);
cent4=P1(find(a2==4),:);cent4=mean(cent4);
cent5=P1(find(a2==5),:);cent5=mean(cent5);
for n=1:R1%计算样本到各个中心的距离
ecent1(n)=norm(P1(n,:)-cent1);
ecent2(n)=norm(P1(n,:)-cent2);
ecent3(n)=norm(P1(n,:)-cent3);
ecent4(n)=norm(P1(n,:)-cent4);
ecent5(n)=norm(P1(n,:)-cent5);
end
%选择离每类中心最近的csum个样本
for n=1:csum
[va me1]=min(ecent1);
[va me2]=min(ecent2);
[va me3]=min(ecent3);
[va me4]=min(ecent4);
[va me5]=min(ecent5);
ecnt1(n,:)=P1(me1(1),:);ecent1(me1(1))=[];tc1(n)=1;
ecnt2(n,:)=P1(me2(1),:);ecent2(me2(1))=[];tc2(n)=2;
ecnt3(n,:)=P1(me3(1),:);ecent3(me3(1))=[];tc3(n)=3;
ecnt4(n,:)=P1(me4(1),:);ecent4(me4(1))=[];tc4(n)=4;
ecnt5(n,:)=P1(me5(1),:);ecent5(me5(1))=[];tc5(n)=5;
end
p2=[ecnt1;ecnt2;ecnt3;ecnt4;ecnt5];T2=[tc1,tc2,tc3,tc4,tc5];
%统计分类结果
Confusion_Matrix_GRNN=zeros(6,6);
Confusion_Matrix_GRNN(1,:)=[0:5];
Confusion_Matrix_GRNN(:,1)=[0:5]';
for nf=1:5
for nc=1:5
Confusion_Matrix_GRNN(nf+1,nc+1)=length(find(a2(find(T1==nf))==nc));
end
end
pre2=0;
for n=2:6;
pre2=pre2+max(Confusion_Matrix_GRNN(n,:));
end
pre2=pre2/R1*100;
end
%% 结果显示
Confusion_Matrix_FCM
Confusion_Matrix_GRNN
算法反复计算10次,最后得到的聚类结果及两种聚类方法的比较如表34-1所列。其中,每一行均表示聚类算法得到每类样本在实际各入侵类别中的分布数量。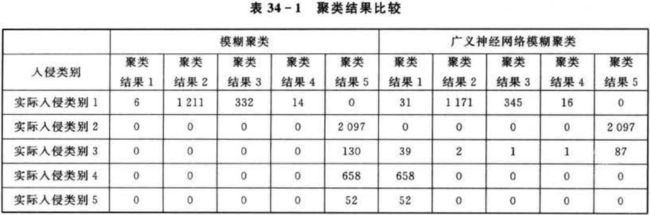
从表34-1中可以看出,对于网络入侵数据,模糊聚类没有实现对数据的有效分类,聚类结果没有把类别2到类别5的样本区分开来,广义神经网络模糊聚类有效分类了类别1和类别2的样本,类别3到类别5没有有效分类,但是同模糊聚类相比,聚类结果有所改善。
4.案例扩展
本案例结合了模糊聚类的无导师聚类和广义神经网络的有导师学习功能完成了对未知网络入侵数据的聚类,广义神经网络所起的作用为训练后分类所有入侵样本。
除了广义神经网络以外,还可以选择BP神经网络、RBF神经网络等。虽然两种方法结合的分类效果比模糊聚类要好,但是还应该看到,该方法没有实现对所有样本有效分类,在第38章中将继续探讨网络人侵聚类问题。
5.完整代码和数据文件
基于广义神经网络的网络入侵检测Matlab代码