APP爬虫之-Protobuf协议逆向解析
在做APP抓取时,会发现有的APP Response回来的数据有“加密”。不知道返回的内容是什么。
如下:
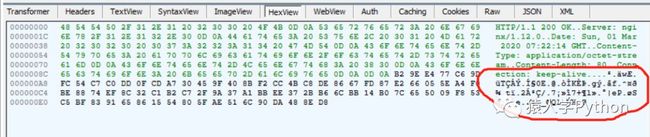
如上,内容不是明文的,没办法解析数据。APP常见的对数据加密有三种情况:第一种是,用诸如AES这类加密算法对数据加密,然后在APP里用key进行解密,这类的数据解密的难度不是很大,弄清楚是用的什么加密算法就能反解。
第二种是,用“私有”协议把数据序列化,只有了解该协议的细节才有可能把数据反序列化出来。这个的难度较大,没有功底,头发撸白都不一定撸出来。游戏和大厂APP盛行搞一个自己的私有协议来交换数据。
第三种是,用第三方厂商的协议来数据序列化,自己搞不出来私有协议的就选用第三方厂商的。比如用 Google 的 Protobuf ,来做数据序列化,也就是数据“加密”。
今天聊的就是第三种,Protobuf 的数据反解析。
先来看一个 Protobuf ,做数据序列化的直观例子。比如一个 APP 的 Response 原先是以 json 格式返回的:
这样很容易被解析,用Protobuf把上面数据序列化再传输就变成类似这样:
这张图片只是样例
这样就没法直接解析数据,如果了解 Protobuf 协议的话就能加快反解速度。所以还得从头来聊 Protobuf 。
一、什么是 Protobuf ?
Protobuf 是 Google 开发的一套数据存储传输协议,跟 xml 和 json 一样的,都是用来储存和传输数据的。 因为 Protobuf 能够把数据压缩得很小,所以传输数据就比 xml 和 json 快几倍,Protobuf 解析数据的速度也比它两快,所以在数据网络传输上,用 Protobuf 而不用 json 就有点受欢迎了。
不过 Protobuf 储存、压缩、传输效率比 json 好,付出的代价就是用法麻烦,不像 json.loads() json.dumps() 一下就搞定了这么简单。Protobuf 有一套自己的语法。不了解 Protobuf 协议语法和用法的话也无法反解数据。
先了解下 Protobuf 序列化和反序列化的整个流程:
1.1.先定义一个 Protobuf 语法文件( .proto 文件)
该语法文件用来说明要传输哪些字段、字段的数据类型、数据间的嵌套关系这些。比如一个APP要返回的数据有电话号码,姓名,年龄这三个字段,你就需要把这三个字段定义在 .proto 文件里,并且指明他们的数据类型,比如姓名和电话是字符串, 年龄是整型。
1.2.使用 Protobuf 提供的工具编译该语法文件。用工具编译 .proto 文件的目的是,把 .proto 文件编译成代码,工具会根据该 .proto 文件自动生产代码。 这个代码就是用来做数据序列化和反序列化的。
1.3.服务端用第2步中的代码,把“明文”数据序列化,变成“密文”后,返回给APP。
1.4. APP 客户端用第2步中的代码,把“密文”数据反序列化,就“解密”成明文拉。
理论说多了很迷糊,再整个完整的直观例子:
二、Protobuf 正向开发流程
2.1.先配置 Protobuf 环境
https://github.com/protocolbuffers/protobuf/releases/在 Google 官方 github 地址下载 Protobuf 。
下载一个 Protobuf 编译器和一个调用编译器的接口程序,我们这里用Python版的。
如上图,箭头所示,解压 protoc.win64.zip 里有个 protoc 命令就是编译器。PS:注意要给 protoc 配置上环境变量,不然没法全局调用该命令。
解压 protobuf-python-3.11.4.zip 这是Python模块,cd到python目录里运行 Python setup.py build 和 Python setup.py install 安装Python模块。
Python编辑器里运行 import google.protobuf 可以检测是否安装成功。
example目录里有官方写好的Python示例程序 和 示例 .proto文件。
2.2.写一个 .proto 语法文件
语法文件怎么写,要根据具体的传输数据来定制,比如按照 example 里的示例,如果要传输的数据是如下格式:
那么定义的 .proto 语法文件就如下:
这样就定义好了一个 .proto 语法文件,语法文件如何定义要根据传输数据的不同而变。
更全的 protobuf 语法 可以看这个,有网友翻译成了中文版的。https://colobu.com/2017/03/16/Protobuf3-language-guide/
2.3.使用第一步中下载的 protoc 编译器来编译 .proto 文件
protoc --python_out=. addressbook.proto
上述表示把 addressbook.proto 文件编译成Python版的。
如果文件语法错误,在编译的时候会有提示。编译完后,会多出一个.py文件
我们就可以调用这个 .py 来序列化上面的数据。
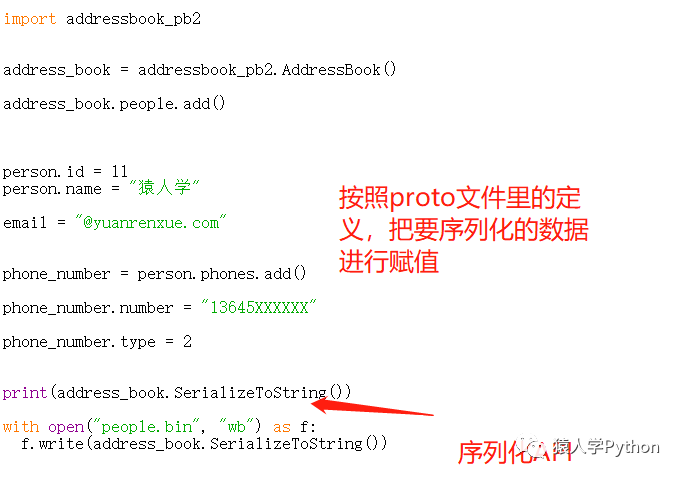
2.4.开始序列化数据

print里输出的就是序列化(“加密”)后的数据。
2.5.对序列化后的数据进行反序列化(“解密”)
反序列化就把数据又还原啦。
上述过程就是一个完整的正向数据 protobuf 序列化过程。我们可以看出来,主要是定义一个 .proto 文件,然后把它编译生成代码。 后面就主要用这个代码来做序列化和反序列化工作。
三、逆向解析 Protobuf
正向过程比较轻松,因为对方即有 .proto 文件,也有序列化代码,也知道要传输的数据样式。但是逆向这个过程,APP里是没有 .proto文件的,APP里是有反序列化的代码,但是看得也头晕。那该怎么办呢?
借助工具,我们使用上面下载的protoc编译工具,这个工具提供反解析参数
protoc --decode_raw < people.bin
如上,使用 --decode_raw 参数就能把序列化后的数据,反序列化(解密)出来。
上面只是把数据还原了,那如果我们要完全把 .proto 文件也还原出来该怎么办呢?
如果 APP 发送 request 的数据要先序列化后再发送给服务端的话,那爬虫要做的事情就不只反序列化,还要能序列化。
做序列化是一个正向的过程,按照上面流程,必须先要有 .proto 文件才行。所以继续还原 .proto 文件,还原 .proto 是个体力活和细致活。就是参照反解析出来的数据,还原出 .proto 文件。
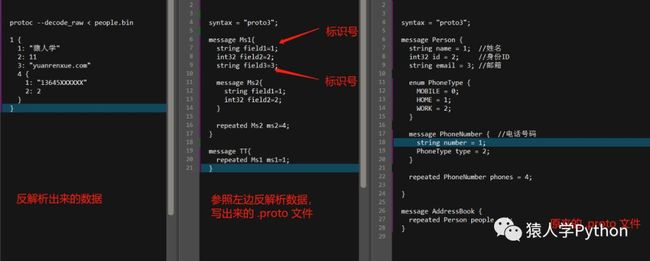
上面这张图是关键,看懂了就能还原出来。上图左边是反解析出来的数据,中中间是参照左边写出来的 .proto 文件,右边是人家原本的 .proto 文件。
左边和中间图对比可以看出,就是根据左边的字段,挨个把字段重新定义出来就OK啦。遇到 "{" 就定义一个message。
中间和右边图对比可以看出,变量的名字是无关紧要的,数据类型还原正确就行。变量赋值的那些1,2,3是标识号,message里同一层级的标识号不能重复,一般是按照变量顺序从1开始递增。标识号的数字是个关键,数字写错了反解析出来的数据会不对。
这样就把 .proto 文件还原出来了,然后按照正向流程又去编译,就可以使用它去序列化(“加密”)和反序列化(“解密”)APP数据了。