《Spark大数据技术与应用》肖芳 张良均著——课后习题
目录
- 教材
- 知识汇总+课后习题
-
- 第一章 Spark概述
-
- Spark的特点
- Spark生态圈
- Spark应用场景
- `第二章 Scala基础`
- `匿名函数`
- Set
- Map
- `map`
- `flatMap`
- `groupBy`
-
- 课后习题
- 第三章 Spark编程
- `教材52页任务3.2及之后的任务` 重点复习
- `sortBy排序`
- `collect查询`
- `distinct去重`
- zip
- `实训题`
-
- 实训1
- 实训2
- 选择题
- 编程题
- 第四章 Spark编程进阶
- 第五章 Spark SQL:结构化数据文件处理
- 课后习题
-
- 选择题
- 操作题
- 第六章 Spark Streaming:实时计算框架
教材

知识汇总+课后习题
第一章 Spark概述
Spark的特点
- 快速
- 易用
- 通用
- 随处运行
- 代码简洁
Spark生态圈
- Spark Core 提供底层框架和核心支持
- BlinkDB 用于海量数据上运行交互式SQL查询的大规模并行查询引擎
- Spark SQL
- Spark Streaming 流式计算
- MLBase
- MLlib 数据挖掘算法库
- GraphX 图计算
- Spark R
Spark应用场景
- 腾讯
- Yahoo
- 淘宝
- 优酷土豆
第二章 Scala基础
Scala的特性
- 面向对象
- 函数式编程
- 静态类型
- Scala是可扩展的
val是常量
val name:type = initialization
var是变量
var name:type = initialization
运算符
数组
var z:Array[String] = new Array[String](num)
或
var z=Array(元素1, 元素2, ……)
Scala列表与数组非常相似,列表的所有元素都具有相同的类型。
与数组不同的是列表不可变,也就是说列表内的元素不能通过赋值来更改。
 如果需要合并两个列表,可以使用”:::”三个冒号表示。
如果需要合并两个列表,可以使用”:::”三个冒号表示。
基本操作方法
| 基本操作 | 描述 |
|---|---|
| arr.length | 返回数组的长度 |
| arr.head | 查看数组的第一个元素 |
| arr.tail | 查看数组中除了第一个元素外的其他元素 |
| arr.isEmpty | 判断数组是否为空 |
| arr.contains(x) | 判断数组是否包含元素x |
匿名函数
匿名函数是使用箭头”⇒”定义的,头的左边是参数列表,箭头右边是表达式,表达式产生函数的结果。
但在考试中也许是这样使用。
如果函数的每个参数在函数中最多出现一次,则可以使用占位符“_”代替参数。 可以把这里的占位符当作需要填入的空白,也就是上一条的x和y。
scala> (x:Int, y:Int)=>x+y
scala> val addInt = (x:Int, y:Int) => x+y
scala> val addInt = (_:Int) + (_:Int)
Set
没有重复对象的集合
scala> val set:Set[Int]=Set(参数1, 参数2, ……)
Map
映射是一种可迭代的键值对结构,所有值都可以通过键来获取,并且Map中的键都是唯一的。
scala> val person:Map[String, Int]=Map("John"->21, "Betty"->20)
关键点在函数组合器
| 函数 | 描述 |
|---|---|
| map(func) | 对RDD数据集中的每个元素都使用func,返回一个新的RDD |
| filter(func) | 对RDD数据集中的每个元素都是用func,返回func为true的元素构成RDD |
| flatMap(func) | 和map类似,但是flatMap生成的是多个结果 |
| union(otherDataset) | 返回一个新的dataset,包含源dataset和给定的dataset的元素的集合 |
| groupByKey(func) | 返回(K, Seq[V]),根据相同的键分组 |
| reduceByKey(func, [num Taskk]) | 用一个给定的func作用在groupByKey而产生的(K, Seq[V]),比如求和 |
map
通过一个函数重新计算列表中的所有元素,并且返回一个相同数目元素的新列表。直接看样例:
scala> val num = List(1,2,3,4,5)
scala> num.map(x => x * x)

这里使用到了匿名函数,代码解释为:常量val列表内的信息,将其进行匿名函数处理,它原先的值相乘。也就是说,11,22,3*3……。这里只是初级使用,一定要先了解这一步!考试的时候一定会有题目考到要使用map的情况!
过滤函数。
scala> val num:List[Int] = List(1,2,3,4)
scala> num.filter(x => x % 2 == 0)

其使用方法相当于if条件判断,只不过将其变得更为简洁。当然使用起来还可以结合map。

flatMap
将多维数组或列表进行扁平化。

groupBy
分组聚合,得到的结果是Map类型。
scala> val num = List(1,2,3,4,5,6,7,8,9,10)
scala> num.groupBy(x => x % 2 == 0)

课后习题
-
选择题

-
编程题
水仙花数是指其个位、十位、百位3个数的立方和等于这个数本身,请用Scala变成求出所有水仙花数。
for (n <- 100 to 999){ val b = n / 100 // 百位 val s = n % 100 / 10 // 十位 val g = n % 100 % 10 // 个位 if (b * b * b + s * s * s + g * g * g == n){ println(n); } }

第三章 Spark编程
RDD的创建与使用
RDD是一种容错的、只读的、可进行并行操作的数据结构
创建:makeRDD
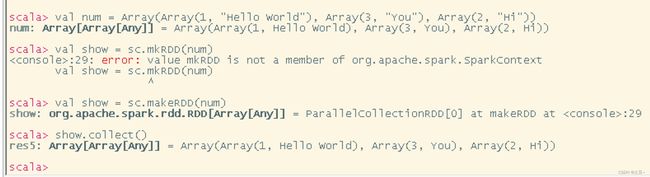
CSV文件的读取也可以这样读,不用按照书上描述的写。
从HDFS创建RDD
// HDFS下的文件
val file = sc.textFile("hdfs://主机名:9000/文件目录")
// Linux下的文件
val file = sc.textFile("file:///文件目录")
文件的存储
rdd名称.saveAsSequenceFile("保存路径")
// 或
rdd名称.saveAsTextFile("保存路径")
教材52页任务3.2及之后的任务 重点复习
sortBy排序
- 参数1,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值
- 参数2,默认为true(升序),false(降序)
- 参数3,排序后的分区个数
collect查询
distinct去重
zip
将两个RDD组合成Key / Value形式,这两个RDD的partition数量以及与元素数量必须都相同。
简单的集合操作
| 方法 | 描述 | 简述 |
|---|---|---|
| intersection( ) | 参数是RDD,求出两个RDD的共同元素 | 交集 |
| union( ) | 参数是RDD,合并两个集合的所有元素 | 并集 |
| subtract( ) | 参数是RDD,将原RDD和参数RDD的相同元素去掉 | 补集 |
| cartesian( ) | 参数是RDD,求两个RDD的笛卡尔积 | 笛卡尔积 |
实训题
实训1
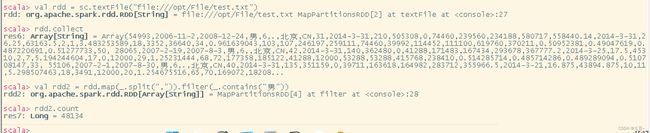
统计性别为“男”的用户
//分开处理
val rdd = sc.textFile("file:///opt/test.txt")
rdd.collect // 在考试时可写,可不写
val rdd2 = rdd.map(_.split(",")).filter(_.contains("男"))
rdd2.count
// 统合处理
sc.textFile("file:///opt/test.txt").map(_.split(",")).filter(_.contains("男")).count
![]()
实训2
单词计数

//分开处理
val rdd = sc.textFile("file:///opt/words.txt")
rdd.collect // 在考试时可写,可不写
val rdd2 = rdd.flatMap(_.split("\\w+")).map((_, 1)).reduceByKey(_+_, 1)
val rdd3 = rdd2.filter(_._2 > 3)
rdd3.saveAsSequenceFile("HDFS路径")
// 统合处理
sc.textFile("file:///opt/words.txt").flatMap(_.split("\\w+")).map((_, 1)).reduceByKey(_+_, 1).filter(_._2 > 3).saveAsSequenceFile("HDFS路径")
选择题

编程题
地名次数
```scala
//分开处理
val rdd = sc.textFile("file:///opt/users.csv")
val rdd2 = rdd.map(_.split(",")).map(x => (x(1), 1))
rdd2.reduceByKey(_+_).collect
```

//统合处理
sc.textFile("file:///opt/users.csv").map(_.split(",")).map(x => (x(1), 1)).reduceByKey(_+_).collect
将结果保存……
![]()
第四章 Spark编程进阶


第五章 Spark SQL:结构化数据文件处理
基本的MySQL命令操作
DataFrame查询操作两种方式
- 将DataFrame注册称为临时表,然后通过SQL语句进行查询
- 直接在DataFrame对象上进行查询。
课后习题
选择题
操作题
用户播放歌曲次数
case class userList(userid:Int, artistid:Int, count:Int) // 创建用例类
val user_artist_data = sc.textFile("file:///opt/user_artist_data.txt").map{x => val y = x.split(" "); userList(y(0).toInt, y(1).toInt, y(2).toInt)}.toDF();
user_artist_data.createOrReplaceTempView("user_artist")
spark.sql("select userid, count(distinct artistid) from user_artist group by userid").show()
spark.sql("select artistid, count from user_artist where userid=1000002 oder by count desc limit 10").show()
第六章 Spark Streaming:实时计算框架
课后习题

