【stable-diffusion使用扩展+插件和模型资源(下)】
插件模型魔法图片等资源:https://tianfeng.space/1240.html
书接上文:(上)
插件推荐
1.lobe theme
lobe theme是一款主题插件,直接可以在扩展安装
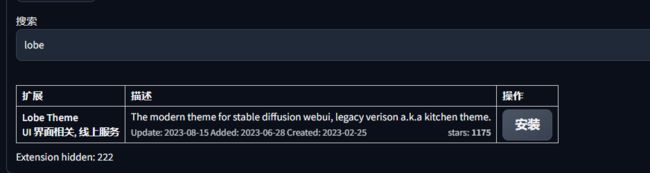
界面进行了重新布局,做了一些优化,有兴趣的可以下载试试,右上角设置按钮,第一行就是语言设置,还有颜色等等

2.SadTalker
https://github.com/OpenTalker/SadTalker
基于最新顶会文章的一款插件,只需要一张图片和一段音频就可以使图片动起来说话的一段视频

点击请在此处,来到安装说明界面,从网址安装,下载方法最后总结说一遍,下次我直接放网址了,你可以从以下四种方式安装
- 直接扩展搜索sadTalker安装,如果没有
- 从网址安装,需要魔法,如果还不行
- 直接在扩展目录下,git clone 网址(之前写过git安装,往前翻翻)
- 压缩包下载,解压放到扩展

安装完后还需要把模型文件下载放到扩展目录sadtalker插件下的模型目录下,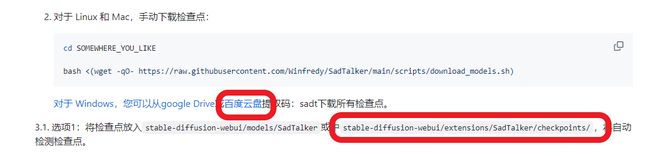
如果你想要启用图片面部修复,还需下载gfpgan

下完这两个文件,解压把它里面的文件放到该目录下
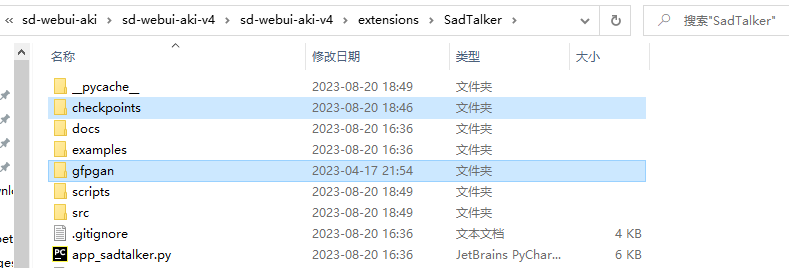
把模型里archive,BFM,hub三个压缩包解压,

还需要下载ffmpeg,之前Ai无闪烁视频制作那期讲了安装过程,就是去官网,下载压缩包解压,然后添加环境变量就行了,很简单,详细过程看https://tianfeng.space/1616.html
到此,准备工作完毕!!来到webui,上传照片,声音(太长可能处理不了),右边的参数很少,就是选择分辨率,和裁剪方式,是否启用面部修复(效果不一定好),直接生成就行,推荐256,裁剪

成品:随便找的音频(狗头)
https://tianfeng.space/wp-content/uploads/2023/08/tmppu_mfqe22-0-100.mp4
3.预设管理器
就是比自带的预设多了很多选择,比如采样方法,种子,宽高等等,以往的预设只能保存正反向提示词,很多一些常用的基础设置并不能很好的保存
https://github.com/Gerschel/sd_web_ui_preset_utils
从网址安装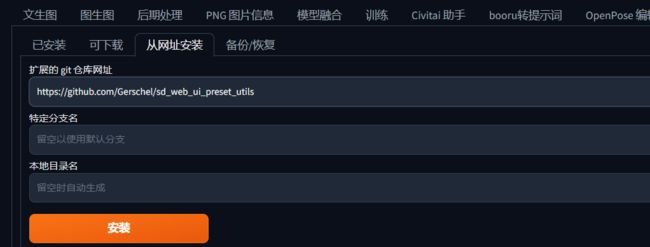
重启客户端打开,在右下角,点击详细设置,,可以勾选你想要保存的信息
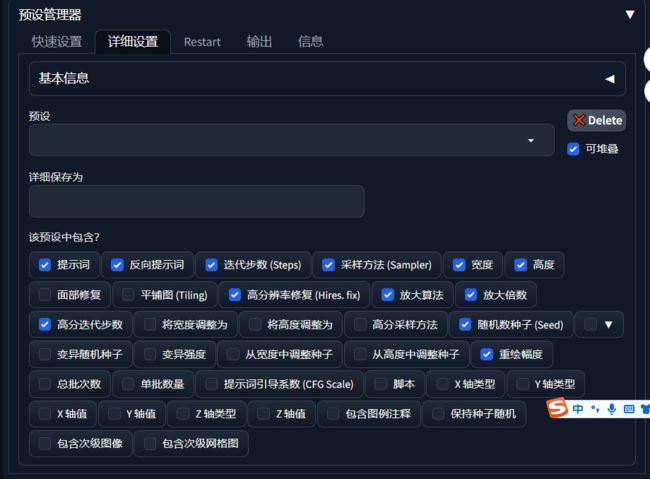
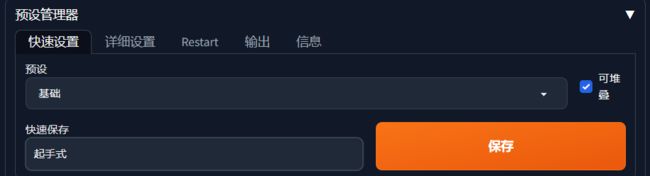
然后起名“起手式”,点击保存,下次可以直接加载了
4.infinite-image-browsing
https://github.com/zanllp/sd-webui-infinite-image-browsing
一个强大的图像管理器。精准的图片搜索结合多选操作,可以进行过滤/归档/打包,大大提高效率。再也不用读取图片信息来得到图片的生成信息了,直接查阅生成图片,一键发送到文生图,图生图
从网址安装,重启

来到“无图片边浏览插件”,翻译的怪怪的,你们界面应该也差不多
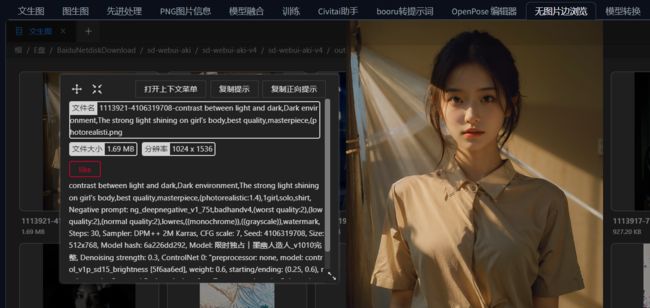
打开上下文菜单选项可以把生成信息发送到文生图,图生图,局部重绘等等,OK下一个
5.纵横比助手
https://github.com/thomasasfk/sd-webui-aspect-ratio-helper
该插件有点小问题,超过限定分辨率容易长宽比会锁死无法调整,所以在该目录下,用记事本打开就行,在红框出更改如下

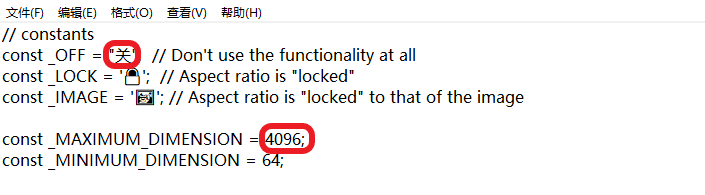
重启,打开就可以正常使用了
5.制作海报
传入带文字的黑字白底图,设置如下:
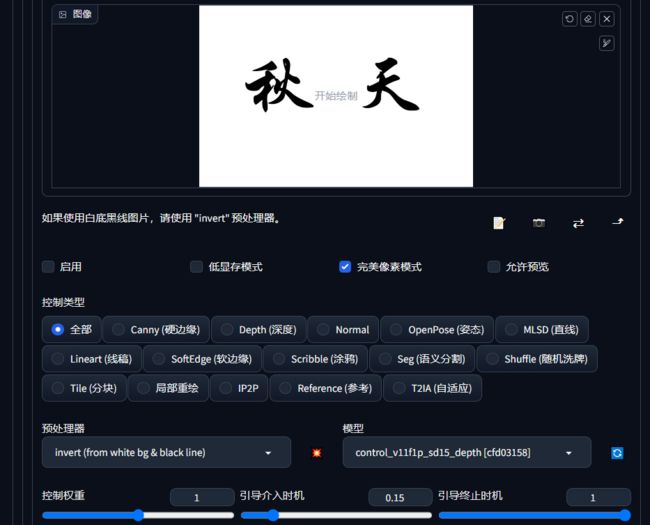
简单书写提示词
masterpiece,best quality,in autumn,(autumn maple forest:1.3),(very few fallen leaves),(path),maple_leaf,grove,fallen leaves,golden theme,
Negative prompt: (man:1.3),lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
Steps: 40, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 3775422122, Size: 768x512, Model hash: 4199bcdd14, Model: revAnimated_v122, Denoising strength: 0.7, ControlNet 0: "preprocessor: invert (from white bg & black line), model: control_v11f1p_sd15_depth [cfd03158], weight: 1, starting/ending: (0.2, 1), resize mode: Crop and Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (512, 64, 64)", Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+, Version: v1.5.1
然后对生成图片ps添加文字排版,简单作参考,毕竟本人没什么设计天赋!
6.logo设计

提示词参考如下:
masterpiece,best quality,Digital Art Concept,High detail,4k,Industrial Design,(magnificent_architecture:1.3),(house:1.3),beautiful background,Futurism,Seby Punk,Studio Lighting,Concept Art,Assembly,Fantasy Engine,Octane Rendering,Architectural Visualization,Architectural Rendering,surrealism,16k,Surreal,High detail,
7.面部修复
https://github.com/Bing-su/adetailer
扩展搜索安装

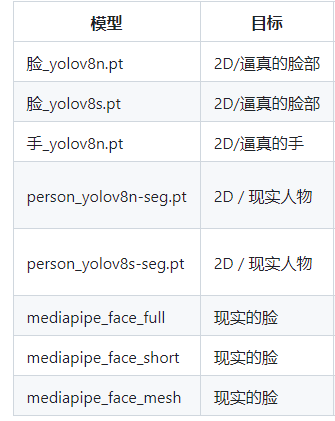
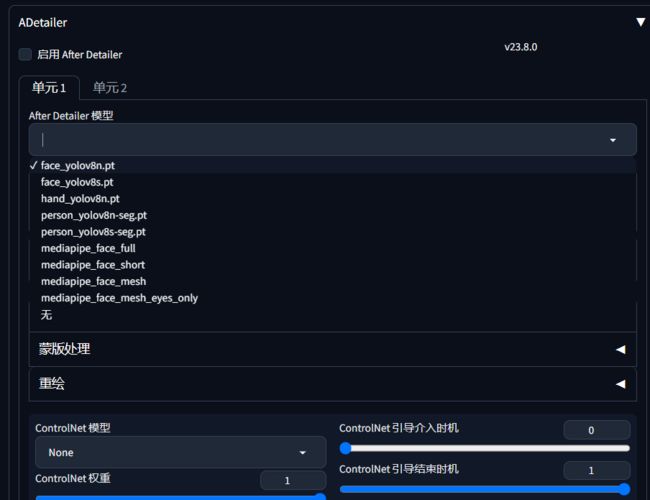
使用直接使用lora填入提示词,它会根据lora重新绘制脸型
模型推荐
1
https://www.liblibai.com/modelinfo/e1ec32b3de474c19a216e30b0050d895

这是艺术向的一款lora,风格直逼MJ的氛围感~如果你希望自己的模型有一些高级感的表达,淡色盛宴绝对是好选择!这是一个艺术向的尝试使用了大量艺术馆摄影风格,带有淡色系的优雅美感人物可以在场景中走秀,舞蹈。
2
https://www.liblibai.com/modelinfo/966e76ef52674283a5b06fe7c34f6ec4
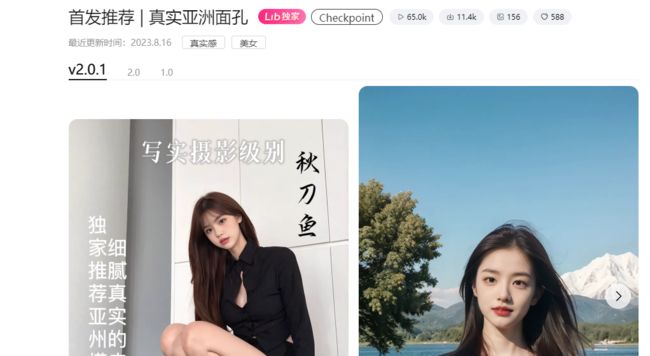
更细腻的光影更真实的皮肤纹理告别网红脸会摄影的朋友加上相机参数会有不一样的效果哦,全身图建议配合使用adetailer,
3
https://www.liblibai.com/modelinfo/b5bf9fce324b79ddcedca71217740357
此模型是各种真实,摄影,写实风格模型的合体,经历了配比调整,追求一个摄影真实感,去除油腻感,
4.
https://www.liblibai.com/modelinfo/e8f951aa5dc6d7ac2f422a231c058dd0
尝试这两个插件我使用了动态阈值修复和adetailer插件,都讲过
5.
https://www.liblibai.com/modelinfo/1fd281cf6bcf01b95033c03b471d8fd8
本模型适用性较广,插画、二次元及普遍的2D、2.5D均可很好出图,比较有特色的是对niji风的复现,搭配LoRA nijiexpress以及不同LoRA的复用有很好的相性,直出图就会有很高的质量,
6.
https://www.liblibai.com/modelinfo/e44b67fbe1d5c73f7aa22a91adfde9b8
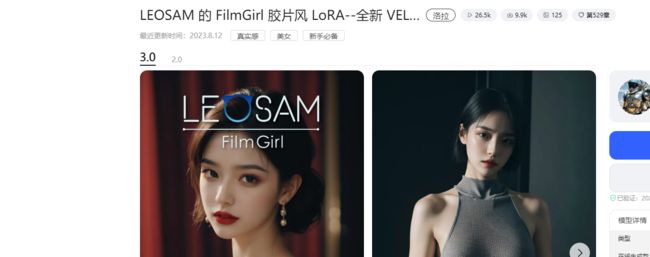
这是一个用于生成胶片风格AI写真照片的LoRA模型,C站上下载量已近6万,广受大家好评。
该模型与MoonMIX、majicMIX real或Chilloumix等写实模型搭配使用,可以生成鲜艳的胶片风格照片。同时搭配TEXTUAL IVERSION模型: bad_pictures 、 negative_hand Negative Embedding 。这两个Negative Embedding模型不会对胶片的成像有明显影响。
7.
https://www.liblibai.com/modelinfo/cb8d7083b853b2361c243fdb03778b17
这个不用多说了:
1.GhostMix是Civitai All Time Highest Rated (历史最高评价排名)第二名的模型,仅次于DreamShaper,Civitai上400次评价4.99(满分5分)也是最高评分的模型之一。
2.GhostMix没有融任何Lora,Checkpoint应该主打的是兼容性,解决的是做的到的问题,而Lora是做的对的问题,GhostMix是对lora兼容性最强的模型,2D-3D都可以兼容。
3.推荐一定要做高清修复! 高清修复: 2倍, 重绘幅度:0.4-0.5 或 1.5倍, 重绘幅度:0.5-0.65
4.如果想要复现,确保CLIP值要对! CLIP1和CLIP2要对!建议把图下下来然后放到PNG信息里面去查设置)
5.之前用的大多数Prompts在新版本也可以生成相似的结果
6.用 ng_deepnegative_v1_75t和easynegative,建议别用BadHandV4,V5(会非常影响画风)
7.采样方法建议 DPM++系列 , 步数20-30, CFG:3-7(7最好,3有时候会有非常大的惊喜)