西湖大学的强化学习数学原理视频学习总结
断断续续在B站把西湖大学邵老师的‘【强化学习的数学原理】课程:从零开始到透彻理解’看完了,感觉非常棒的一门课程视频,涉及了一些基础的数学定理,也很多细节,用起来可以直接用,但如果不懂得整个脉络,基本上很短时间就忘得差不多了,因此,根据自己的思路整理起来,以便自己记忆。
一、基本概念或者名词
state 、state value 分别用S,和V(S)表示
action、action value 用a和P(s,a)表示,
policy 用π表示
return 针对一个trajectory中所有的rewards加起来
reward 用r表示
trajectory
episode
discaunted rate 一般在计算return时加个折扣率,在(0,1)之间,最大就越远视。
强化学习一定要以随机变量,及由概率事件组成的视角出发,经常提到的期望就是在某个概率模型(决策)下的期望(平均值),一个s采取某个a有概率,一个s采取了a后跳到某个s'也有概率。
强化学习是基于markov desition process的,因此有以下概念
state transition probability p(s‘|s,a)
reward probabiliy p(r|s,a)
policy π(a|s)
强化学习的目标就是寻找最优policy,什么是最优策略,就是在最优策略下,V(s)每一个状态下的state value都大于或等于其他策略下对应state的V(s)
什么是state value呢,就是在某个状态s出发获得的reward期望
什么是action value ,就是在某个s下,采用某个action后得到的reward
因此有以下公式表达:
![]()
二、贝尔曼公式

matrix-vector 形式
![]()


![]() 是在某个s下的即时reward的平均值,组起来就是一个向量,
是在某个s下的即时reward的平均值,组起来就是一个向量,![]()
是一个状态转移矩阵,即某个状态下转移到其他状态的概率,第i行代表第i个状态下跳到其他所有状态的概率,其实这个就是模型环境
贝尔曼公式求解:两种方法
1.解析解方法
![]()
如果状态空间很大,没法求,一般不用
2.数值逼近方法
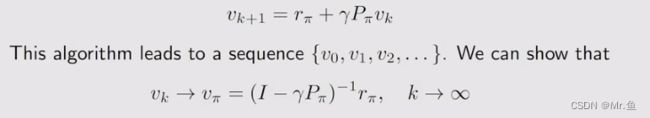
三,贝尔曼最优公式
首先理清state value 和action value的关系
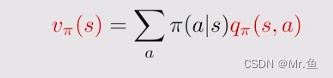
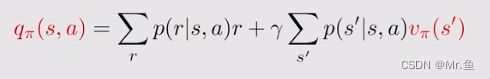
知道了所有v(s)就直到了q(s,a),知道了所有q(s,a)就知道了v(s)
基于这个思路,就可以用迭代方法求出贝尔曼最优公式(应用到contraction mapping theorem)


四、值迭代和策略迭代
1.value iteration
值迭代其实就是贝尔曼最优公式求解过程的迭代

2.policy iteration
策略迭代其实就是 先估计一个策略Π,根据这个策略利用贝尔曼公式求解所有v(s)(有两种方法,上面提到),有了所有v(s),一般用迭代发求出v(s),知道了v(s)就知道了所有
p(s,a),利用贪婪原理(跟值迭代哪个一样),得到一个新的策略,其核心就是p(s,a),策略就根据每个s下最大的p(s,a)来选取策略,这个以此迭代

3.value iteration和policy iteration的区别
很像,都是用贪婪算法去更新策略Π,但是value iteration 在更新v的时候是没有利用迭代求出v的,他迭代过程中的v不是在某个策略下的v(s),而只是一个优化过程中的一个值(取值于最大
q(s,a) ),但是策略迭代时每次策略迭代后,求的v是在该策略下的v(s),每次求v需要迭代,即大迭代里面有迭代。通俗讲就是值迭代时值关于state value 逼近的过程,而策略迭代时策略逼近最优策略的过程。
由于策略迭代中的每一次迭代中都有求解贝尔曼公式中求解v(s)的很多次迭代,而值迭代中只有一次,这样就两个极端,那么就有一个截断了的策略迭代,指定在每一轮策略下的v(s)求解不是无穷多次迭代,而是有限次的迭代即可,这就是truncated policy iteration。

五、蒙特卡洛算法
1.前面通过贝尔曼求解都是在环境模型已知的情况下,即每个state下可能采取的a的概率以及跳转到其他s的概率等,但更一般的时环境模型时不知道的,就有了后面的各种算法
蒙特卡洛算法(MC) 基本思想就是在policy iteration中不是通过模型计算v(s),进而计算
q(s,a),再更新策略的,而是通过经验数据,计算v(s)的,其他的就跟策略更新一样。
MC basic
在模型不知道的情况下,如状态转移矩阵 ![]() 不知道的情况下,在policy iteration中是不能用迭代的方法求出V(s)的,但是我们有经验(数据),利用q(s,a)最原始定义(计算他的期望return)如下:
不知道的情况下,在policy iteration中是不能用迭代的方法求出V(s)的,但是我们有经验(数据),利用q(s,a)最原始定义(计算他的期望return)如下:

跑很多次,每个状态下都跑过很多条episode,这样就有在s下很多次return,直接求这些经验数据的平均,就得到了q(s,a),一句话利用经验数据求出,而不是模型得到。这是蒙特卡洛算法的核心
2.MC basic 的一个算法推广 MC exploring starts
其根本是解决MC basic 里面经验数据利用不高的弊端,以为每一个(s,a)下的episode只利用一次,就是计算q(s,a),但这个episode其实还包含了其他的(s‘,a),因此可以利用起来就有了这个MC exploring starts

3.前面哪个算法需要生成的episode尽可能的遍历或所有(s,a),但物理世界里很难做到,这就催生了另外一个 算法,MC - ε greedy
其思想就是,之前在更新策略里面,在某个s下找到让q(s,a)最大的那个action,并让采用这个action的概率为1,其他统统为0,这就导致在某给s下采用a的概率几种在其中一个里面,很硬,可以变得更soft,最大的那个q(s,a) 的a的概率不给1,而是给比1小的概率,其他的也给个大于0的的概率,即下面

六,第6章和第7章都是有关一些数学算法的理论和推到
第6章是 stochastic approximation 和stochastic gradient descent
这个理论其实就是去优化g(x)=0问题,这个g(x)经常是求一个梯度的函数,因为梯度=0一般是一个极值,其思想就是我有很多数据,利用这些数据去求解g(x)=0
基于这个理论才推出了第7章的temporal -difference (TD)(这个数学理论推出的东西很像那个神经网络里面优化梯度的SGD,移动指数加权平均)
我的理解就是这个理论就是用来处理实时数据的,MC算法都是episode出来后才处理,有了TD算法就可以在每一次action后得到一次数据就处理,不用等长长的episode跑完后才处理。如实时更新v(s)

基于TD的理论,就推出了sarsa、n_stepsarsa、expect sarsa 和 Q_learning
这些算法都是围绕着下面这个公式

这些算法就是TD target(![]() )不同而产生的,
)不同而产生的,

前面的值迭代或者策略迭代 后出来的结果时每个状态可能都是有最大的v(s),但是TD求出来后可能只有当前你关系的那个出发点的v(s)时最大的,其他出发点很可能不是最优的。
七、value function approximation
前面的值迭代或者策略迭代,或者TD算法下的sarsa等算法,其v(s)或者q(s,a)都是通过离散的方式记录,即像一个网格里面,一个格子对应一个相关的值,这样如果状态空间和action空间很多,就需要很多个格子(空间)且没有泛化型,这个原因就有了value function approximation。即用经验数据去拟合一个函数去求值v(s)或者q(s,a),这个拟合函数可以是线性也可也时非线性,现在都是用神经网络去拟合

利用sarsa和Q_learning 的TD target代入就得到了sarsa和Q_learning结合value function approximation的算法:


整个框架跟之前的sarsa基本一样,就是更新q(s,a)时,是通过拟合函数更新参数以获得q的更新。
Q_learning与value function approximation结合就有如下


而利用神经网络去拟合函数q(s,a,w)就推出的DQN(deep Q_learning)

为了用梯度下降的方法优化q(s,a,w),就用了一种方法去做,就是两个网络,一个是主网络main network,即后面那个q(S,A,w),还有一个是target network,就是q(S‘,a,w),主网络是实时更新w的,但是target network是隔一段时间从住网络那里copy w来更新w的

八、policy gradient
前面的value function approximation是通过经验数据拟合一个函数求value(state value或者action value),进而更新policy,这里是直接用经验数据拟合应给策略函数求策略值,而不再像离散的情况得到策略。
拟合函数首先要考虑的是loss fuction ,进而用梯度的方法求极值,这里的拟合函数记为:
π(a|s,θ),θ就是参数,现在一般用神经网络拟合。
用函数的方式求策略,需要定义一个标量的数,以优化求最大值,这里引出两个计算标量的metric:
1.关于state value的,求出最大的平均值,就是求期望

这里d(s)与v(s)有两种不同的关系,一个是互相独立的,一个是相关的,独立的就简单直接是均匀分布,即1/|s|状态空间个数分之一,这个计做v0,相关的就复杂点就是之前提过的有这样的关系:

其实![]() 可以写成
可以写成
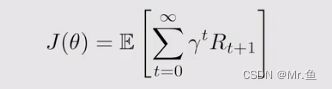
2.是关于reward的,实际上它是等价于第一种关于state value的

在具体中,有以下做法

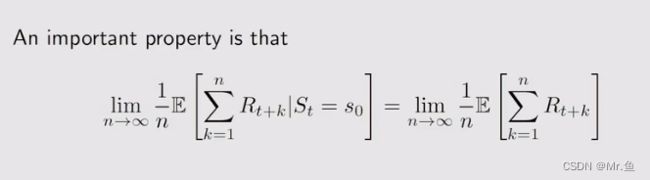
这个就是关于r的metric
上面两个metric其实是等价的:

哪如何求策略metric的梯度呢?
有一个统一的写法:


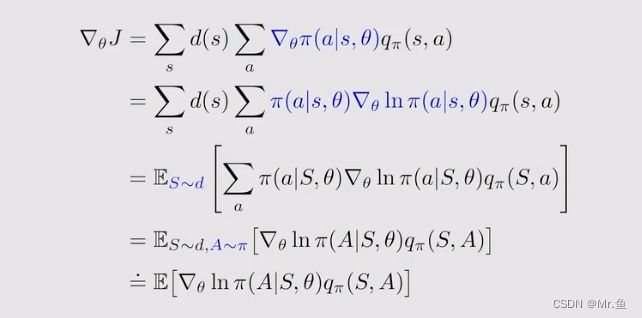
为什么要引入ln呢,主要是为了写成Expecation的形式:
有Expectation,可以用采用近似,
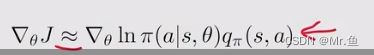
因为带ln,因此要保证π(a|s,θ)大于0,需要引入softmax fuction

在引入神经网络后,其实很简单,就是最后输出层加一个softmax 激活函数
由于有expectation,因此可以用采用近似,以此梯度可以用以下方式求出:

近似q(s,a)的方法有两种,一个是蒙特卡洛和TD

那如何采样呢?

用蒙特卡洛的方法求q(s,a)就是REINFORCE方法,这个方法是offline的,因为蒙特卡洛需要跑完一个episode后可以,以此下面θ的更新是在遍历完条episode才更新。

九、Actor-Critic methods (AC)
Actor --- policy update
Critic --- policy evaluation
1.QAC
跟REINFORCE 差不多,只是在计算action value(即q(s,a))时方法不一样,这里用的是SARSA的方法,属于TD的算法,因为可以一边跑episode,每一步就可以更新action value数据,进而更新策略函数中的参数θ,从而更新策略:

这里就需要两个神经网络,一个是q(s,a,w)还有一个是Π(a|s,θ)
2.A2C(advance AC)
其实就是引入了一个baseline(偏置),不改变期望(平均值),但影响方差
其目的就是每次采样的action value 不是以其值作为影响因素,而是以每次采样其相对平均值的幅值来作为影响因素,即类似神经网络那种namorlization
baseline的选择就是v(s),不要忘了,v(s)就是在该s下的action value(q(a,s))的期望,即平均。这样就有了:



这样就只有一个v(s)的网络,而不需要在来一个q(s,a),当然后面还有一个Π的神经网络。

3.off_policy actor critic
前面提到的都是on_policy 的,当前的数据需要根据当前的策略更新,这就导致之前的历史数据没法用了,这里就有一个方法可以充分利用历史数据,即你可以先跑,有完整的数据后再计算,即off policy的。
这个方法要用到important sampling 理论,属于概率论方面的数学公式
大致的意思是,我在一个已知的概率分布下有数据,现在我在一个新的概率分布下有数据,但我不知道这个新的概率分布是怎样的,那么我可以通过前面一个已知概率分布的经验知识去求这个新的概率分布。


基于这个important sampling 就有了这个off policy的AC算法


其他的跟A2C一样


这个β(a|s}是一个定值,历史数据

4.Deterministic actor-critic
前面的方法都是stotastic的,但假如action有无穷多的时候,stotastic就不行了,需要deterministic的

这里的μ就是直接把状态空间转成动作空间,就是给我一个s,就直接输出一个动作,比如往上走或往下走
有了定义,就需要找目标函数



这个deterministic 看得有点懵,会用就好吧
十、这些算法都有去openai的gym库里找环境进行实现,这里推荐b站的一个视频,里面提供有一些代码,可以去跑跑,b站搜 “强化学习 简明教程 代码实战”