Controllable Person Image Synthesis with Attribute-Decomposed GAN
1. Idea
可控性的图像生成
提出了具有两个独立pathways的生成器。其中一个pathway是用于pose encoding,另一个用于decomposed component encoding。
对于后者首先使用预训练的human parser从source person image 中自动地分离出component attributes(得到的是semantic layouts)。得到的component layouts之后通过multi-branch embeddings送入global texture encoder中(得到相应的latent code)。得到的latent code通过一种特殊的形式结合得到style code。之后这些表示component attribute的style code通过AdnIN中的仿射变换与pose code相结合。最后进行图像生成。
2. Contribution
- 通过直接提供的的不同的源人物图像来控制人物图像属性的生成,解决pose和component attribute之间错综复杂的关系。
- 提出了attribute-decomposed GAN来进行人物属性合成。
- 通过利用off-the-shelf human parser 来提取component layouts,使得component attributes进行自动分离,解决了人物属性不高效的标注问题。
3. Related work
image synthesis
person image synthesis
目前的person image synthesis方法只是将条件图像转换为具有目标姿态的图像。但是本文中的方法不仅仅能够对姿态进行控制,还能够对component attributes(例如头,上衣和裤子)进行控制。而且生成的图像具有更加真实的纹理和连续的ID信息。
4. Method description
本文的目标生成具有用户控制属性(例如头发,上衣和裤子)的人物图像。与之前的属性编辑方式不同(之前的方法需要每一个属性都进行标注的标签数据),本文中通过精心设计的生成器来对component attributes进行自动和无监督的分离。因此本文中只需要无需对每一属性进行标注的人物图像训练数据。在训练期间,目标图像 p t p_t pt和条件图像 I s I_s Is送入生成器中,输出生成图像 I g I_g Ig。
4.1 Generator
生成器通过两个独立pathways将 p t p_t pt和 I s I_s Is表示为两个隐变量,分别称为pose encoding和decomposed component encoding。这两个pathways通过一系列的style blocks连接,style blocks将源人物图像的纹理风格嵌入到pose feature。
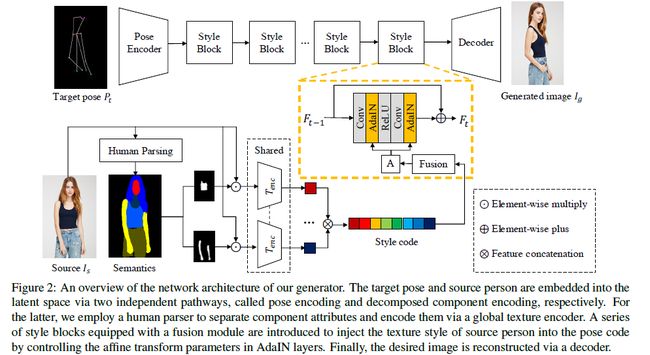
4.1.1 pose encoding
在pose pathways中 p t p_t pt通过pose encoder映射到隐空间中,用 C p o s e C_{pose} Cpose表示,其中pose encoder有N个下采样卷积层构成(N=2)。
4.1.2 Decomposed component encoding
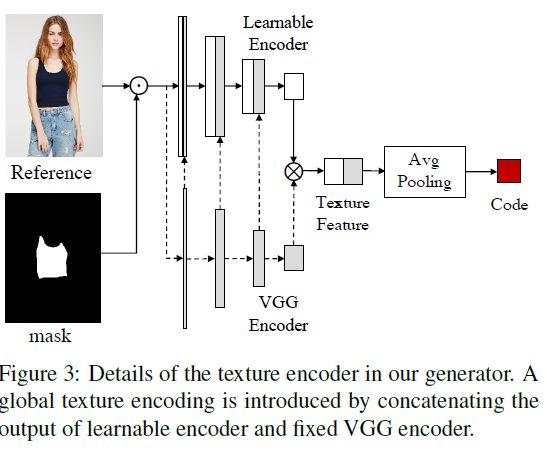
在source pathways中 I s I_s Is通过一个称为decomposed component encoding(DCE)的模块映射到隐空间中,用 C s t y C_{sty} Csty表示。
DCE这一模块首先提取 I s I_s Is的semantic map S S S (通过预训练的human parser进行 S S S的提取),并将 S S S转换为K个通道的heat map M ∈ R K × H × W M\in R^{K\times H\times W} M∈RK×H×W。每一个通道 i i i对应一个相应的component(例如上衣),用二进制掩模 M i M_i Mi来表示。其中K=8,分别表示(face,hair,paints,upper clothes,skirts,arm,leg,background)

有component i i i的解耦的人物图像 I s i I_s^i Isi是通过将 I s I_s Is和相应的 M i M_i Mi相乘得到的。
I s i = I s ⊙ M i I_s^i=I_s\odot M_i Isi=Is⊙Mi
I s i I_s^i Isi之后被送入texture encoder T e n c T_{enc} Tenc来获取每一分支(不同的component)相应的style code C s t y i C_{sty}^i Cstyi。
C s t y i = T e n c ( I s i ) C_{sty}^i=T_{enc}(I_s^i) Cstyi=Tenc(Isi)
每一个分支的 T e n c T_{enc} Tenc的权重的共献的,之后将每一个 C s t y i C_{sty}^i Cstyi进行叠加得到最终的 C s t y C_{sty} Csty。
相比于直接将整个源人物图像进行编码,DCE将源人物图像解耦为不同component并将相应的隐编码进行结合得到最终的style code。DCE的好处有两个:1)该方法加快了模型的收敛速度,在较短的时间内获得了较好的仿真结果。由于由不同服装和姿势的人的图像组成的集合的复杂结构,很难用详细的纹理编码整个人,但只了解人的一个组成部分的特征要简单得多。此外,不同的组件可以共享相同的网络参数进行颜色编码,因此DCE隐式地为纹理学习提供了数据扩充。2)该方法可以进自动和无监督的属性分离而需要在训练集有任何的标注。DCE利用已有的human parser对人物进行空间解耦,在style code的固定位置进行特定attribute的学习。因此我们可以很容易的通过加入从不同source persons提取的期望的component codes来进行component attributes的控制。
对于texture encoder T e n c T_{enc} Tenc,本文引入了一种全局纹理编码的结构,通过将相应层中的VGG特征连接到我们的原始编码器。原始编码器中的参数值是可学习的,而VGG中的参数值是固定的。在COCO训练集上预训练的VGG网络有一定的全局属性和较强的泛化能力。但是和一般的风格迁移任务不同,该模型需要生成明确的结果,对于固定编码器的结构来说很难适用于该模型,因此引入了可学习编码器。
4.1.3 Texture style transfer
texture style transfer的目的是将源人物图像纹理特征与目标姿态姿态进行结合,起到了连接pose code和style code的作用。这个transfer network由几个级联的style blocks构成,每一个style block都由一个fusion module 和具有AdaINde 残差卷积块构成。以第t个style block进行分析,其输入为上一个style block的输出 F t − 1 F_{t-1} Ft−1和style code C s t y C_{sty} Csty,其输出为
F t = φ t ( F t − 1 , A ) + F t − 1 F_t=\varphi_t(F_{t-1},A)+F_{t-1} Ft=φt(Ft−1,A)+Ft−1
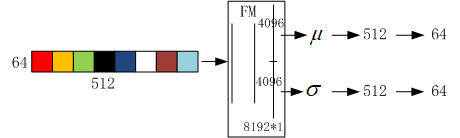
其中 φ t \varphi_t φt表示卷积块, F 0 = C p o s e F_0=C_{pose} F0=Cpose 。共采用了8个style blocks(与解耦的8个component attributes相对应,如果想要对某个component attribute进行改变,就要将对应的component style code进行改变)。A表示AdaIN层中已学习到的仿射参数(缩放 μ \mu μ和变化 σ \sigma σ),其能够用于将特征规范化为期望的style。这些参数能够使用fusion module(FM)从style code C s t y C_{sty} Csty中提取出来,FM是DCE中很重要的辅助模型。因为component codes是通过特殊的顺序进行叠加来构成style code的,这使得位置和component feature之间是高度相关的,这就强加了很多人为的干预,并导致了与网络本身的学习倾向的冲突。因此,我们引入了由3个全连接的层组成的FM,前两个层允许网络通过线性重组灵活地选择所需的特征,最后一个层提供所需维度的参数。FM可以有效地分离特征,避免前向操作和后向反馈之间的冲突。
如何通过style code计算AdaIN的参数 μ \mu μ和 σ \sigma σ:将维度为 64 × 512 64\times 512 64×512的style code经过FM重构为维度为 8192 × 1 8192\times 1 8192×1的特征,其上半部分的特征共4096维用于计算 μ \mu μ,下半部分用于计算 σ \sigma σ。由于共有8个style blocks,所以每个style blocks分给512维特征,且每个style block有两个AdaIN层,每一个AdaIN层分给64为特征用于计算AdaIN层参数。
4.1.4 person image reconstruction
解码器由N个反卷积层构成(N=2)。
4.2 Discriminators
判别器由 D p D_p Dp和 D s D_s Ds构成, D p D_p Dp是由于保证 I g I_g Ig和 I t I_t It的人物姿态是对齐的, D s D_s Ds是由于保证 I g I_g Ig和 I s I_s Is的外观纹理是相同的。 D p D_p Dp和 D s D_s Ds采用patchGAN进行实施。
4.3 Training
损失函数包括对抗损失函数、L1损失函数、感知损失函数以及内容损失函数。总的损失函数为:
L t o t a l = L a d v + λ r e c L r e c + λ p e r L p e r + λ C X L C X {\mathcal{L}}_{total}={\mathcal{L}}_{adv}+\lambda_{rec}{\mathcal{L}}_{rec}+\lambda_{per}{\mathcal{L}}_{per}+\lambda_{CX}{\mathcal{L}}_{CX} Ltotal=Ladv+λrecLrec+λperLper+λCXLCX
L1损失函数
使用L1损失函数的目的是直接指导 I g I_g Ig和 I s I_s Is的外观纹理相同,这避免了明显的颜色失真,加快了算法的收敛速度,获得满意的结果。
L r e c = ∥ G ( I s , p t ) − I t ∥ \mathcal{L}_{rec}=\Vert G(I_s,p_t) -I_t\Vert Lrec=∥G(Is,pt)−It∥
感知损失函数
除了需要在RGB空间中满足低层的约束外,还需要利用预训练的VGG来提取特定层的深层特征用于纹理匹配。由于视觉风格统计特性能够通过特征相关性来表示,所以本文中使用了特征的Gram矩阵来度量纹理相似性。Gram矩阵的计算为:
G ( F l ( I t ) ) = [ F l ( I t ) ] [ F l ( I t ) ] T \mathcal{G}(\mathcal{F}^l(I_t))=[\mathcal{F}^l(I_t)][\mathcal{F}^l(I_t)]^T G(Fl(It))=[Fl(It)][Fl(It)]T
其中 F l ( I t ) \mathcal{F}^l(I_t) Fl(It)表示通过预训练的VGG提取的 I t I_t It的 l l l层的特征。因此感知损失函数为:
L p e r = ∥ G ( F l ( G ( I s , p t ) ) ) − G ( F l ( I t ) ) ∥ {\mathcal{L}_{per}}={\Vert {\mathcal{G}}{({\mathcal{F}}^l {(G(I_s,p_t))})}-\mathcal{G}(\mathcal{F}^l(I_t))\Vert} Lper=∥G(Fl(G(Is,pt)))−G(Fl(It))∥
内容损失函数
内容损失函数最初被提出用于度量image translation任务中两张non-aligned图片的相似性。相比于pixel-level损失需要pixel-to-pixel alignment,内容损失函数允许相对目标的空间变形,能够得到更少纹理失真和更合理的结果。内容损失函数为:
L c x = − l o g [ C X ( F l ( I g ) , F l ( I t ) ) ] {\mathcal{L_{cx}}}=-log[CX({\mathcal{F}^l(I_g)},{\mathcal{F}^l(I_t)})] Lcx=−log[CX(Fl(Ig),Fl(It))]
其中 l = r e l u { 3 − 2 , 4 − 2 } l=relu\{ 3_-2,4_-2\} l=relu{3−2,4−2},是通过VGG19提取出来的, C X CX CX表示匹配特征的相似度量函数,考虑了像素的语义平均值以及整张图片的内容。
工作的不足之处
只是用AdaIN将style code融入到pose中(实际上纹理细节会有缺失),实际上在纹理细节方面保持的不是那么的好,例如某些衣服的纹理保持的不是很好。