【学习笔记】计算机视觉对比学习综述
计算机视觉对比学习综述
- 前言
- 百花齐放
-
- InstDisc
- InvaSpread
- CPC
- CMC
- CV双雄
-
- MoCo
- SimCLR
- MoCo v2
- SimCLR v2
- SwAV
- 不用负样本
-
- BYOL
- SimSiam
- Transformer
-
- MoCo v3
- DINO
- 总结
- 参考链接
前言
本篇对比学习综述内容来自于沐神对比学习串讲视频以及其中所提到的论文和博客,对应的链接详见第六节。本篇博客所涉及的对比学习内容均应用在CV领域,算是到21年为止比较全面的对比学习综述内容讲解。对比学习作为一种自监督学习方法,其在CV领域的发展也印证着自监督学习的发展,科研工作者也在一步步揭开自监督学习的神秘面纱,通过构建不同的代理任务,采用不同的模型架构,来极力挖掘自监督学习的潜力。相信通过本篇博客的学习,你能够对对比学习有着更深刻的认识,万变不离其宗,当你领悟到对比学习的本质,你就能
百花齐放
InstDisc
InstDisc文章设计了一个全新的代理任务——个体判别任务,并提出了memory bank方法,即记忆库,该方法在MoCo这篇文章中反复被比较,如果说MoCo是一个里程碑式的工作,那么InstDisc就是巨人的肩膀,MoCo正是站在这个肩膀上进行优化的。下面对这篇工作进行简单的介绍。
上图是监督学习对图片的识别结果,可以看到排名前列的都是和豹子相似的动物,这并不是因为这些动物的标签和豹子相近,而是图片本身就很相近。作者根据这个观察,提出了个体判别任务。
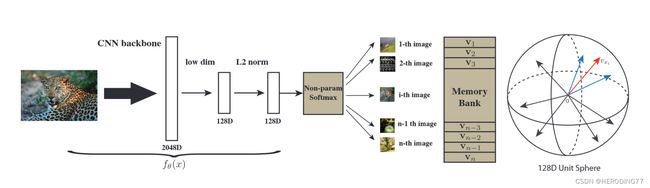
整个工作流程如上图所示。首先通过一个卷积神经网络将所有图片编码成128维度的特征,并且希望这些特征能够尽可能分开,因为对于个体判别任务来说,每个图片就是一个单独的类,不同图片的特征属于不同类。由于采用对比学习的方法,需要构建大量负样本,因此所有特征存在记忆库中作为负样本采样使用。每次训练时,采样K个负样本用于计算与正样本之间的NCE损失,并更新网络。网络更新完重新编码正样本的特征,替换记忆库中旧的特征,如此反复进行模型更新,记忆库的更新,以达到让每张图片的特征区分开的目的。
此外,InstDisc中也在训练中加入了约束,让特征能够动量式更新。
InvaSpread

这篇工作就是MoCo中进行比较的端到端执行的方法,即在一个mini-batch中挑选正负样本,而不采用记忆库存储。InvaSpread的核心思想是说,对于相似的图片,其通过编码的特征应该是相近的,而不相似的图片编码得到的特征应该是远离的。它同样采用了个体判别的代理任务。
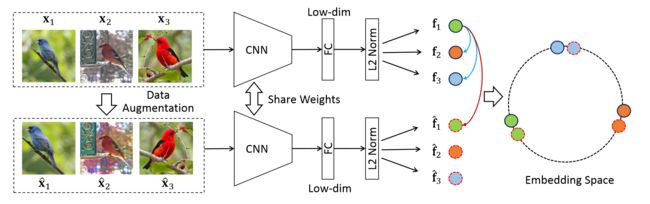
上图是整个训练流程。首先对于输入的mini-batch中的图片进行数据增强,比如256张图片,经过增强得到256张增强图片,这样对于一张图片,就有一个正样本,和510个负样本,然后将这些样本输入到同一个编码器中得到表征,通过对比损失来更新参数。
通过上面的描述我们可以看到,端到端学习的特点在于共享同一个编码器,没有采用格外的数据结构来存储编码好的特征。但是这也是模型性能没有那么突出的原因,mini-batch的样本个数有限,文中最多仅支持256个样本,学习到特征较少,性能提升没有那么明显。
CPC
在代理任务上也可以做文章。除了判别式的代理任务,还有生成式的代理任务。CPC这篇工作采用的就是生成式的代理任务,流程如下所示:
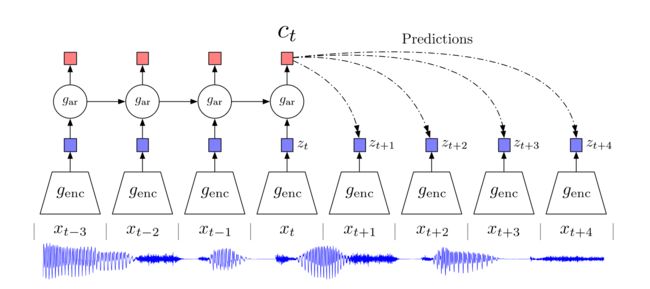
对于任意的音频、文本序列或者图像块,都可以以时序的方式输入到模型中,这里的模型可以是LSTM这样的时序模型,通过处理得到表征,采用t时刻最后一层输出用于预测后面序列,后面 t~t+4 时刻的输入得到的表征都可以作为正样本,而负样本可以是任意其它时刻输入得到的表征。
CMC
CMC工作的核心在于学习所有视角的互信息,它认为像眼睛、耳朵、皮肤等一系列传感器所感知的信息是一致且共享的,比如对于一只狗,你可以看到它、听到它或者感受到它,这些信息都指向这只狗。如果能够将这些所有传感器的信息整合起来,那么将会学习到特别强大的特征。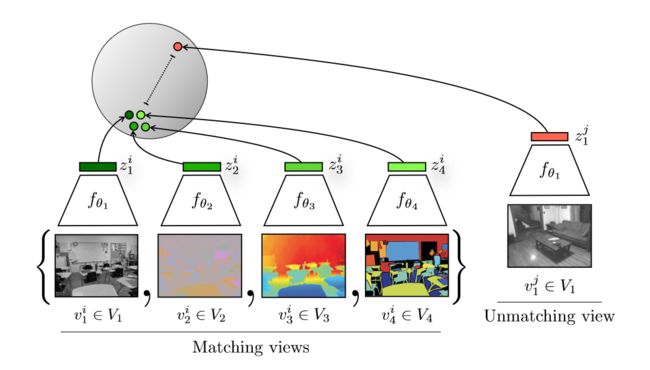
整体流程如上图所示,输入的是一个图像的多个视角信息,包括原始图像,图像对应的深度信息,表面法线信息和语义分割信息,通过不同的编码器编码得到特征,并互为正样本,其余的任何不配对的视角都是负样本,与这些绿色的正样本特征远离。
这篇工作思想很简单,和个体判别任务类似,只不过是多个视角多张图片作为正样本,但是它展示了对比学习的灵活性,只要你脑洞大开,就可以联想到多模态场景,一张图片和其对应的文本的编码可以作为正样本,其余都是负样本,只不过可能需要多个编码器进行编码,计算代价比较高。
上面多个编码器的gap已经被解决了,由于Transformer架构的通用性和可扩展性,多模态的数据可以都使用同一个Transformer进行编码,极 大程度上降低了计算代价。
CV双雄
MoCo
MoCo的主要贡献是将之前的对比学习方法都总结为字典查询问题,提出了队列和动量编码器,得到又大又一致的字典。
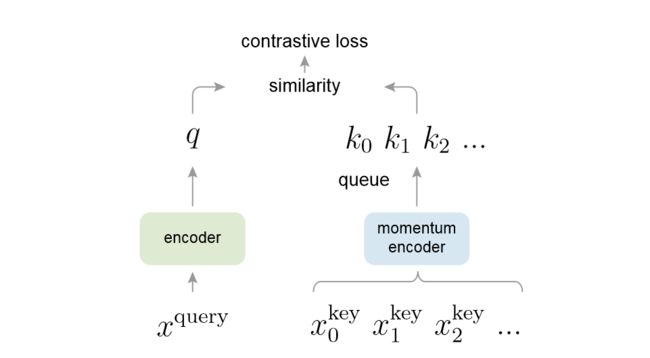
MoCo方法本质上是对InstDisc的改进,但是其简单有效,证明了CV中无监督特征学习也能比有监督特征学习的预训练模型性能要好,这是具有里程碑意义的。
从写作上来看,MoCo明显要比一般的套路要高一筹,它并不是先介绍对比学习,阐述别的工作的不足,提出创新点,而是从无监督学习在CV和NLP领域的差异入手,然后归纳之前对比学习方法的本质,将问题升华了,也提升了整个工作的格局。
SimCLR
SimCLR这篇工作可以看做是对InvaSpread的改进,整体流程如下:

对于mini-batch大小为n的输入,分别通过两个数据增强的方式得到增强后的 x ~ i \tilde{x}_i x~i和 x ~ j \tilde{x}_j x~j,然后输入到相同的编码器中(比如res50)得到各自的表征,之后就是SimCLR与InvaSpread最为不同的地方,它将得到的表征又输入到共享的非线性MLP中,得到降维的特征,然后进行正负样本的判别,这样的简单操作能够将模型的性能提升多大10个点,并且在下游任务上,SIMCLR并不使用MLP,目的是和其它工作对齐,也证实其在无监督预训练部分的优越性。
当然SimCLR还有很多细节的trick,其贡献可以总结如下:
- 大量的数据增强。
- 编码器后添加非线性变换的MLP。
- 更大的batch-size。
MoCo v2
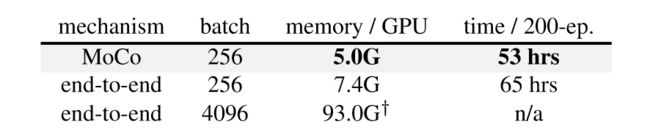
MoCo v2这篇工作就是在原先MoCo的基础上加上了SimCLR的trick,即MLP,数据增强,余弦学习率和更长的训练次数。其效果如下表所示:

可以看到其性能提升还是很明显的,尤其是非线性MLP层的加入,直接提升了6个点。接下来是与SimCLR的对比:

可以看到无论是200个epoch还是更大的训练epoch,MoCo v2都要更胜一筹,并且大大降低了显存和时间上的成本。
SimCLR v2
恰如其标题,大的自监督模型是好的半监督学习者。因此SimCLR v2这篇工作的核心是在说如何做半监督的学习。其工作流程如下:
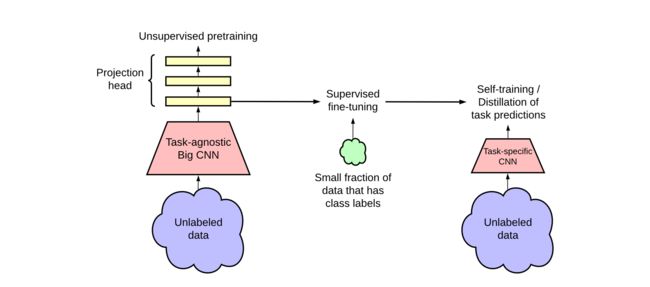
首先在大规模无标签数据集上进行预训练,然后将预训练好的模型在少量的监督数据上微调,最后在无标注的数据上基于特定任务进行自学习。
对于这篇工作,本文主要关注其从v1升级到v2的部分。分成三个点:
- 更大的模型,无监督训练会更好。
- 两层的MLP层。
- 采用动量编码器。
SwAV
SwAV这篇工作将对比学习和聚类结合在一起,因为聚类的思想和对比学习的目标和做法都很相近。
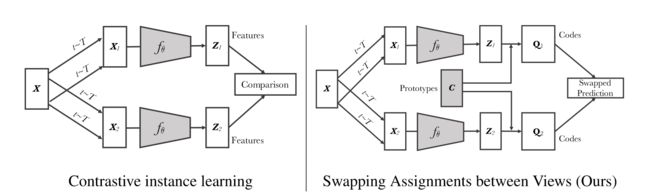
上图是SwAV方法与之前对比学习方法的对比。前面部分的操作相同,对于输入的x,进行两次数据增强,再输入到编码器中得到编码的特征。之前的对比学习方法直接将得到的特征进行比较,但是在SwAV中,编码后的特征还要和聚类的中心进行点乘,其中,,表示聚类中心的个数。 得到的结果即是预测的分类,最后与真实的聚类结果进行比较。
SwAV结合聚类方法的优势如下:
- 之前的对比学习方法需要与上万个负样本进行对比,如ImageNet有128万个样本,那么每个样本本质上就需要和128个负样本进行对比,但是聚类后,只需要和很少的聚类中心进行比较(本文是3000个),大大降低了计算成本。
- 聚类中心具有明确的语义含义,之前的对比学习方法过于随机,可能部分正样本也被当做负样本,并且抽取的类别不均衡。

通过上图可以看出,SwAV的性能已经和监督训练的性能没有明显差异。基本上达到了ImageNet上对比学习的天花板。
上面的故事虽然很精彩,但是对SwAV性能有着大幅提升的是采用了Multi-crop。之前的对比学习方法采用了两个crop,但是这样采样的crop重叠部分很多,学习的只是全局的特征。Multi-crop加入了学习局部特征的部分,即在采样两个crop的基础上,加入了随机采取四个小crop的操作,为了不增加更多的计算成本,作者也减小了前两个crop的大小。比如之前是采样两个224224的crop,现在是采样两个160160的crop和4个96*96的crop。
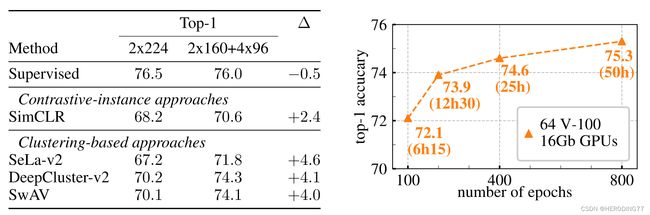
Multi-crop效果显著,它已经不只只是SwAV上的一个trick,而是一个通用的方法,应用在之前的对比学习方法上也能有显著的提升。
不用负样本
BYOL
BYOL这篇工作开创了对比学习的先河,不用负样本就可以很好的学习,而不会出现模型坍塌等问题。它的核心思想是利用一个视角的信息来预测另一个视角的信息。
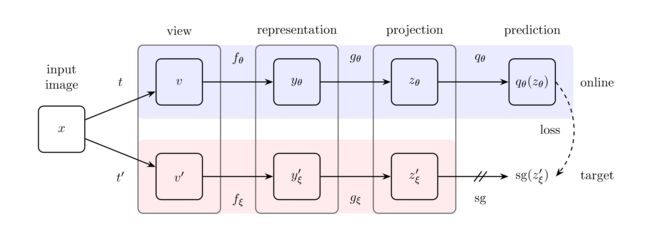
整体流程如上图所示,前面的步骤和正常的对比学习流程一致,都是先数据增强,通过编码器得到特征,然后经过MLP得到映射,上面紫色部分相当于query的编码器,通过梯度更新,下面相当于key的编码器,通过动量更新。与之前工作不同,得到映射后的query还要经过一层映射得到预测,用于预测,将配对的问题转化为了预测的问题。
这种训练方式模型不坍塌,可能的原因在于BN操作。一个有道理的结论是说,BN让整个min-batch中的数据发生了泄露,其他样本变成了隐式的负样本,类似于SwAV和聚类中的对比,这里相当于是和mini-batch的平均图片进行了对比。
但是这样的结论就大大降低了BYOL的创新性,因为BYOL的卖点就在于不用负样本进行对比,但是上面的结论显然打脸了。于是BYOL的团队又写了篇工作进行回应,即 BYOL works even without batch statistics。详尽的实验过程如下表所示:

通过SimCLR最后一个结果可以发现,当编码器和projector都没有用BN时,SimCLR也失败了,隐式负样本的说法不攻自破。因此最后的结论是,BN能提升模型的稳健性,并且如果模型初始化很好,没有BN也能学得很好。
SimSiam
通过上述相关内容的描述,可以看到对比学习加入的trick越来越多,性能也越来越好。SimSiam这篇工作来自何恺明团队,它将对比学习的工作化繁为简,即不需要负样本,也不需要大的batch-size,也不需要动量编码器,就能取得很好的效果。
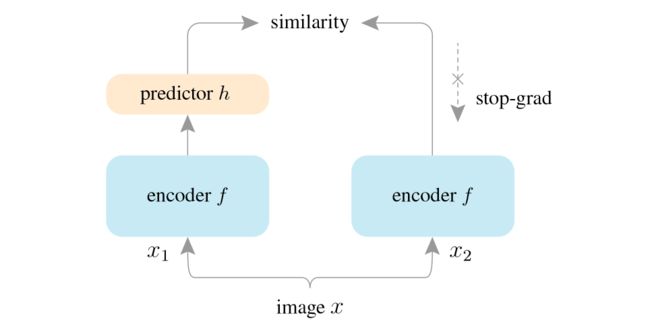

整体的流程和伪代码如上所示,可以看到方法真的是非常简单。就是数据增强,然后将增强的两个图片输入到相同的编码器得到表征,接着就是得到二者互相预测的loss反向传播更新参数。SimSiam和其它工作的对比如下图所示:

可以看到SimSiam和BYOL几乎一模一样,只不过没有采用动量编码器。在ImageNet的表现和其它模型的对比如下表所示:

可以看到MoCo v2在长时间训练下表现最好,这也间接印证了动量编码器的优势。下表是在下游任务上训练的结果:
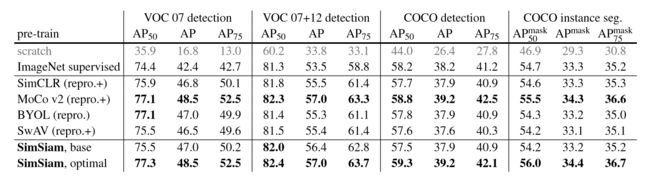
可以看到MoCo v2和SimSiam表现最好。
Transformer
MoCo v3
MoCo v3的工作核心在于如何解决ViT自监督训练的不稳定性。它并没有什么创新性的工作,但是却展示了自监督学习很多有意思的部分。它的核心算法如下伪代码所示:

可以看到,MoCo v2相当于是MoCo v2和SimSiam的合体。只不过把模型的骨干网络换成了ViT。ViT在训练时有一个问题,如下图所示:

随着batch-size的增大,模型的波动也随着增大,并且性能也在逐渐降低。作者通过观察梯度发现,ViT的第一层,即将token编码为embedding时会在波动时产生大的变化,因此作者就将这一层直接冻结,结果就解决了这个问题。
DINO
DINO工作本质上是BYOL工作的延续。其流程如下图所示:
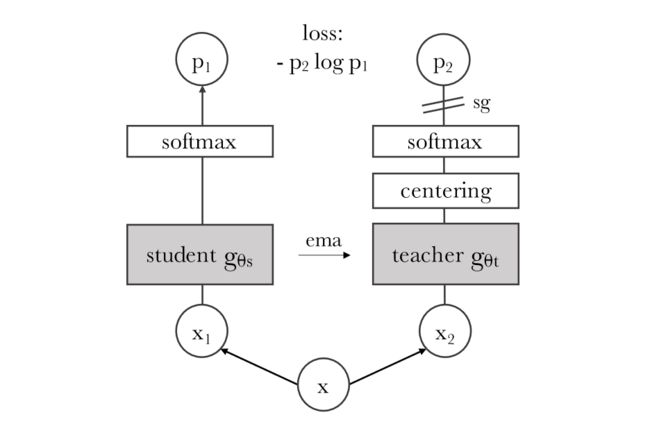
它的优势在于融合了Transformer,其它部分基本上和BYOL一致。在伪代码上也和MoCo v3几乎相同,只是在损失函数上有所区分:

总结
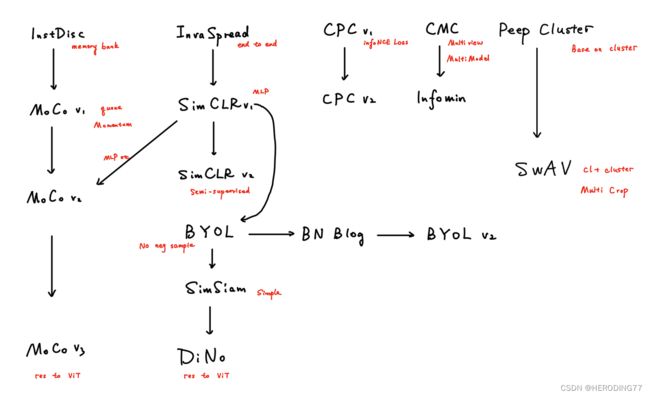
以上工作可以总结为一张图。所以对比学习的发展从大的方向上分为四个阶段,第一阶段百花齐放,所有工作都在摸索如何使用对比学习,如何定义代理任务,如何设计损失函数。紧接着这些工作就根据负样本存储方式分为了两个主流方法,一个是基于记忆库的MoCo方法,另一个是基于端到端的SimCLR算法,二者称为CV双雄。第三阶段以BYOL为首,其发现对比学习无需负样本也能进行,样本通过不同视图的各自预测,就能实现自己和自己比较,从而学习到特征。最后阶段当然是ViT的出现,改变了对比学习的backbone,Transformer架构的优越性得以体现,这个阶段没有创新性的工作,只是替换了模型架构,就实现了很好的性能。
总而言之,对比学习本质上是一种自监督学习方法,其特征学习的核心还是在于代理任务的构建,无论是个体判别,还是多视图预测,亦或是生成,这些都是不同的任务,才是特征学习的核心部分。而其它的trick,包括memory bank,非线性MLP,都是为了帮助完成代理任务的。所以在我看来,对比学习和MAE,BERT,GPT这些预训练模型的本质相同,越好、越复杂的预训练任务,在越大的数据集上,往往能学习到更为丰富的特征。
参考链接
https://www.bilibili.com/video/BV19S4y1M7hm
https://openaccess.thecvf.com/content_cvpr_2018/papers/Wu_Unsupervised_Feature_Learning_CVPR_2018_paper.pdf
https://openaccess.thecvf.com/content_CVPR_2019/papers/Ye_Unsupervised_Embedding_Learning_via_Invariant_and_Spreading_Instance_Feature_CVPR_2019_paper.pdf
https://arxiv.org/pdf/1807.03748.pdf?fbclid=IwAR2G_jEkb54YSIvN0uY7JbW9kfhogUq9KhKrmHuXPi34KYOE8L5LD1RGPTo
https://arxiv.org/pdf/1906.05849.pdf
https://openaccess.thecvf.com/content_CVPR_2020/papers/He_Momentum_Contrast_for_Unsupervised_Visual_Representation_Learning_CVPR_2020_paper.pdf
http://proceedings.mlr.press/v119/chen20j/chen20j.pdf
https://arxiv.org/pdf/2003.04297.pdf
https://proceedings.neurips.cc/paper/2020/file/fcbc95ccdd551da181207c0c1400c655-Paper.pdf
https://proceedings.neurips.cc/paper_files/paper/2020/file/70feb62b69f16e0238f741fab228fec2-Paper.pdf
https://proceedings.neurips.cc/paper_files/paper/2020/file/f3ada80d5c4ee70142b17b8192b2958e-Paper.pdf
https://arxiv.org/pdf/2010.10241.pdf
https://openaccess.thecvf.com/content/CVPR2021/papers/Chen_Exploring_Simple_Siamese_Representation_Learning_CVPR_2021_paper.pdf
https://arxiv.org/pdf/2104.02057.pdf
https://openaccess.thecvf.com/content/ICCV2021/papers/Caron_Emerging_Properties_in_Self-Supervised_Vision_Transformers_ICCV_2021_paper.pdf