【整合一切08/8】:用变压器实现语言翻译
一、说明
这里是国外高手实现德语-英语互译的变压器模型;这是“已实现的变压器”系列最后一篇文章。编码器和解码器相结合,创建了一个能够轻松将德语翻译成英语的模型。

图片来源:作者
本系列的前七篇文章详细研究了变压器的组件:
- 嵌入层
- 位置编码
- 多头注意力
- 位置前馈网络
- 层归一化
- 编码器
- 解码器
下面简要概述了每种方法,然后是德语到英语的翻译。
二、嵌入层
嵌入层为语料库中的每个标记提供相应的矢量表示形式。这是每个序列必须通过的第一层。每个序列中的每个标记都必须嵌入到长度为 d_model 的向量中。该层的输入是(batch_size,seq_length)。输出为 (batch_size、seq_length、d_model)。
class Embeddings(nn.Module):
def __init__(self, vocab_size: int, d_model: int):
"""
Args:
vocab_size: size of vocabulary
d_model: dimension of embeddings
"""
# inherit from nn.Module
super().__init__()
# embedding look-up table (lut)
self.lut = nn.Embedding(vocab_size, d_model)
# dimension of embeddings
self.d_model = d_model
def forward(self, x: Tensor):
"""
Args:
x: input Tensor (batch_size, seq_length)
Returns:
embedding vector
"""
# embeddings by constant sqrt(d_model)
return self.lut(x) * math.sqrt(self.d_model)三、位置编码
然后对这些嵌入的序列进行位置编码,为每个单词提供额外的上下文。这也允许单个单词根据其在句子中的位置而具有不同的含义。图层的输入为 (batch_size、seq_length、d_model)。大小为 (max_length, d_model) 的位置编码矩阵必须切片为与批处理中的每个序列相同的长度,使其大小为 (seq_length, d_model)。广播相同的矩阵并将其添加到批处理中的每个序列中,以确保一致性。最终输出为 (batch_size、seq_length、d_model)。
class PositionalEncoding(nn.Module):
def __init__(self, d_model: int, dropout: float = 0.1, max_length: int = 5000):
"""
Args:
d_model: dimension of embeddings
dropout: randomly zeroes-out some of the input
max_length: max sequence length
"""
# inherit from Module
super().__init__()
# initialize dropout
self.dropout = nn.Dropout(p=dropout)
# create tensor of 0s
pe = torch.zeros(max_length, d_model)
# create position column
k = torch.arange(0, max_length).unsqueeze(1)
# calc divisor for positional encoding
div_term = torch.exp(
torch.arange(0, d_model, 2) * -(math.log(10000.0) / d_model)
)
# calc sine on even indices
pe[:, 0::2] = torch.sin(k * div_term)
# calc cosine on odd indices
pe[:, 1::2] = torch.cos(k * div_term)
# add dimension
pe = pe.unsqueeze(0)
# buffers are saved in state_dict but not trained by the optimizer
self.register_buffer("pe", pe)
def forward(self, x: Tensor):
"""
Args:
x: embeddings (batch_size, seq_length, d_model)
Returns:
embeddings + positional encodings (batch_size, seq_length, d_model)
"""
# add positional encoding to the embeddings
x = x + self.pe[:, : x.size(1)].requires_grad_(False)
# perform dropout
return self.dropout(x)四、多头注意力
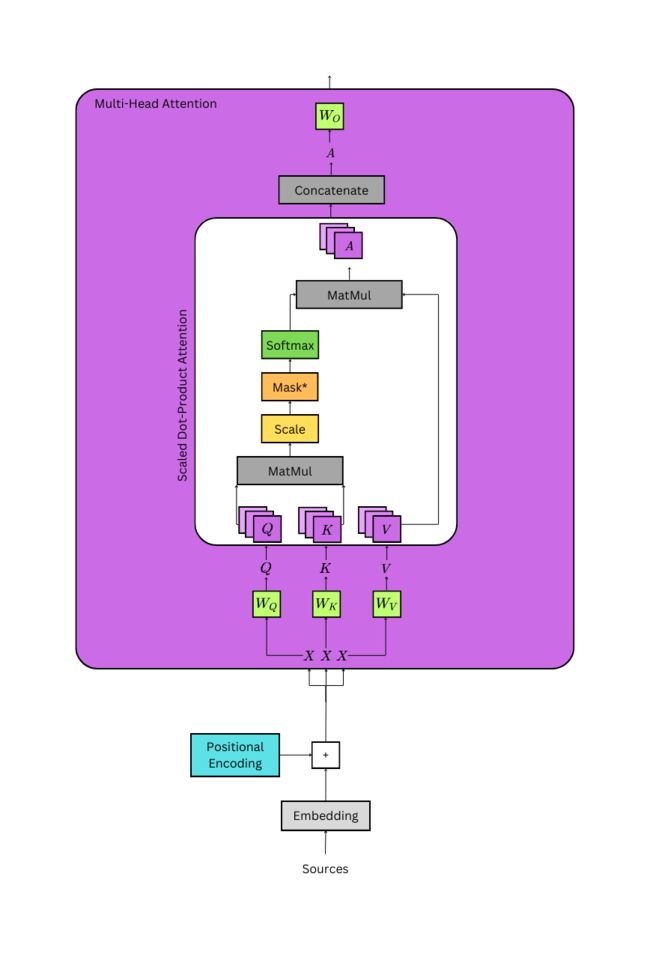
Image by Author
这些嵌入和编码序列的三个相同版本被传递到多头注意力层,以创建由线性层转换的唯一查询、键和值张量。它们的大小均为 (batch_size、seq_length、d_model),其中seq_length根据每个序列的各自长度而变化。这些张量被分成各自的头部数量,大小为 (batch_size、n_heads、seq_length、d_key),其中 d_key = (d_model / n_heads)。现在,每个序列都有n_heads表示形式,可以在训练期间关注序列的不同方面。
查询张量和键张量相乘以生成概率分布,并除以 √(d_key)。键张量必须转置。乘法的输出表示每个序列与自身的关系,它表示目标序列与解码器第二注意机制中的源序列的关系。这些分布的大小为 (batch_size、n_heads、Q_length、K_length)。它们根据序列的填充进行屏蔽,或者如果它们位于解码器的第一个注意机制中,它们也会被屏蔽以允许序列仅关注以前的标记,这是解码器的自回归属性。

图片来源:作者
这些概率乘以序列的另一个表示形式,即值张量。在解码器的第二注意力机制中,它又是源序列。值张量的形状为 (batch_size、n_heads、V_length、d_key)。乘法的输出是(batch_size、n_heads、Q_length、d_key)。将两个张量相乘,通过计算每个头或子空间中每个标记的最重要上下文的摘要来重新加权值张量。
注意力机制的输出被连接回其原始形状(batch_size,seq_length,d_model),其中seq_length = Q_length。最后,该张量通过一个形状为 (d_model, d_model) 的线性层,该层在每个序列中广播。最终输出为 (batch_size、seq_length、d_model)。
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int = 512, n_heads: int = 8, dropout: float = 0.1):
"""
Args:
d_model: dimension of embeddings
n_heads: number of self attention heads
dropout: probability of dropout occurring
"""
super().__init__()
assert d_model % n_heads == 0 # ensure an even num of heads
self.d_model = d_model # 512 dim
self.n_heads = n_heads # 8 heads
self.d_key = d_model // n_heads # assume d_value equals d_key | 512/8=64
self.Wq = nn.Linear(d_model, d_model) # query weights
self.Wk = nn.Linear(d_model, d_model) # key weights
self.Wv = nn.Linear(d_model, d_model) # value weights
self.Wo = nn.Linear(d_model, d_model) # output weights
self.dropout = nn.Dropout(p=dropout) # initialize dropout layer
def forward(self, query: Tensor, key: Tensor, value: Tensor, mask: Tensor = None):
"""
Args:
query: query vector (batch_size, q_length, d_model)
key: key vector (batch_size, k_length, d_model)
value: value vector (batch_size, s_length, d_model)
mask: mask for decoder
Returns:
output: attention values (batch_size, q_length, d_model)
attn_probs: softmax scores (batch_size, n_heads, q_length, k_length)
"""
batch_size = key.size(0)
# calculate query, key, and value tensors
Q = self.Wq(query) # (32, 10, 512) x (512, 512) = (32, 10, 512)
K = self.Wk(key) # (32, 10, 512) x (512, 512) = (32, 10, 512)
V = self.Wv(value) # (32, 10, 512) x (512, 512) = (32, 10, 512)
# split each tensor into n-heads to compute attention
# query tensor
Q = Q.view(batch_size, # (32, 10, 512) -> (32, 10, 8, 64)
-1, # -1 = q_length
self.n_heads,
self.d_key
).permute(0, 2, 1, 3) # (32, 10, 8, 64) -> (32, 8, 10, 64) = (batch_size, n_heads, q_length, d_key)
# key tensor
K = K.view(batch_size, # (32, 10, 512) -> (32, 10, 8, 64)
-1, # -1 = k_length
self.n_heads,
self.d_key
).permute(0, 2, 1, 3) # (32, 10, 8, 64) -> (32, 8, 10, 64) = (batch_size, n_heads, k_length, d_key)
# value tensor
V = V.view(batch_size, # (32, 10, 512) -> (32, 10, 8, 64)
-1, # -1 = v_length
self.n_heads,
self.d_key
).permute(0, 2, 1, 3) # (32, 10, 8, 64) -> (32, 8, 10, 64) = (batch_size, n_heads, v_length, d_key)
# computes attention
# scaled dot product -> QK^{T}
scaled_dot_prod = torch.matmul(Q, # (32, 8, 10, 64) x (32, 8, 64, 10) -> (32, 8, 10, 10) = (batch_size, n_heads, q_length, k_length)
K.permute(0, 1, 3, 2)
) / math.sqrt(self.d_key) # sqrt(64)
# fill those positions of product as (-1e10) where mask positions are 0
if mask is not None:
scaled_dot_prod = scaled_dot_prod.masked_fill(mask == 0, -1e10)
# apply softmax
attn_probs = torch.softmax(scaled_dot_prod, dim=-1)
# multiply by values to get attention
A = torch.matmul(self.dropout(attn_probs), V) # (32, 8, 10, 10) x (32, 8, 10, 64) -> (32, 8, 10, 64)
# (batch_size, n_heads, q_length, k_length) x (batch_size, n_heads, v_length, d_key) -> (batch_size, n_heads, q_length, d_key)
# reshape attention back to (32, 10, 512)
A = A.permute(0, 2, 1, 3).contiguous() # (32, 8, 10, 64) -> (32, 10, 8, 64)
A = A.view(batch_size, -1, self.n_heads*self.d_key) # (32, 10, 8, 64) -> (32, 10, 8*64) -> (32, 10, 512) = (batch_size, q_length, d_model)
# push through the final weight layer
output = self.Wo(A) # (32, 10, 512) x (512, 512) = (32, 10, 512)
return output, attn_probs # return attn_probs for visualization of the scores五、位置前馈网络 (FFN)
经过层归一化并进行残差加法后,注意力机制的输出被传递给FFN。FFN由两个具有ReLU激活函数的线性层组成。第一层的形状为 (d_model, d_ffn)。这是在(batch_size、seq_length、d_model)张量的每个序列上广播的,它允许模型了解有关每个序列的更多信息。此时张量的形状为 (batch_size、seq_length、d_ffn),并且通过 ReLU。然后,它通过第二层,其形状为(d_ffn,d_model)。这会将张量收缩到其原始大小(batch_size、seq_length、d_model)。输出通过层归一化并进行残差加法。
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model: int, d_ffn: int, dropout: float = 0.1):
"""
Args:
d_model: dimension of embeddings
d_ffn: dimension of feed-forward network
dropout: probability of dropout occurring
"""
super().__init__()
self.w_1 = nn.Linear(d_model, d_ffn)
self.w_2 = nn.Linear(d_ffn, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
"""
Args:
x: output from attention (batch_size, seq_length, d_model)
Returns:
expanded-and-contracted representation (batch_size, seq_length, d_model)
"""
# w_1(x).relu(): (batch_size, seq_length, d_model) x (d_model,d_ffn) -> (batch_size, seq_length, d_ffn)
# w_2(w_1(x).relu()): (batch_size, seq_length, d_ffn) x (d_ffn, d_model) -> (batch_size, seq_length, d_model)
return self.w_2(self.dropout(self.w_1(x).relu()))六、层归一化和残差添加

图片来源:作者
对于 (batch_size、seq_length、d_model) 的形状,将跨每个d_model向量执行层归一化。这些值使用修改后的 z 分数方程进行标准化,以保持每个嵌入向量的平均值和标准偏差;这可以防止梯度下降问题。
残差加法在嵌入传入层之前获取嵌入,并将它们添加到输出中。这用从多头注意力和FFN获得的信息丰富了嵌入向量。
层归一化或残差添加都不会影响其输入的形状。这些在编码器和解码器模块以及 nn 中实现。为了简单起见,LayerNorm 用于而不是本文中创建的自定义模块。
七、编码器

图片来源:作者
每个编码器层都包括上述所有层。它负责丰富源序列的嵌入。输入的大小为 (batch_size、seq_length、d_model)。 嵌入的序列直接传递到多头注意力机制。在通过编码器堆栈中的 Nx 层传递后,输出是每个序列的丰富表示形式,其中包含尽可能多的上下文。它的大小为 (batch_size、seq_length、d_model)。
class EncoderLayer(nn.Module):
def __init__(self, d_model: int, n_heads: int, d_ffn: int, dropout: float):
"""
Args:
d_model: dimension of embeddings
n_heads: number of heads
d_ffn: dimension of feed-forward network
dropout: probability of dropout occurring
"""
super().__init__()
# multi-head attention sublayer
self.attention = MultiHeadAttention(d_model, n_heads, dropout)
# layer norm for multi-head attention
self.attn_layer_norm = nn.LayerNorm(d_model)
# position-wise feed-forward network
self.positionwise_ffn = PositionwiseFeedForward(d_model, d_ffn, dropout)
# layer norm for position-wise ffn
self.ffn_layer_norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, src: Tensor, src_mask: Tensor):
"""
Args:
src: positionally embedded sequences (batch_size, seq_length, d_model)
src_mask: mask for the sequences (batch_size, 1, 1, seq_length)
Returns:
src: sequences after self-attention (batch_size, seq_length, d_model)
"""
# pass embeddings through multi-head attention
_src, attn_probs = self.attention(src, src, src, src_mask)
# residual add and norm
src = self.attn_layer_norm(src + self.dropout(_src))
# position-wise feed-forward network
_src = self.positionwise_ffn(src)
# residual add and norm
src = self.ffn_layer_norm(src + self.dropout(_src))
return src, attn_probs
class Encoder(nn.Module):
def __init__(self, d_model: int, n_layers: int,
n_heads: int, d_ffn: int, dropout: float = 0.1):
"""
Args:
d_model: dimension of embeddings
n_layers: number of encoder layers
n_heads: number of heads
d_ffn: dimension of feed-forward network
dropout: probability of dropout occurring
"""
super().__init__()
# create n_layers encoders
self.layers = nn.ModuleList([EncoderLayer(d_model, n_heads, d_ffn, dropout)
for layer in range(n_layers)])
self.dropout = nn.Dropout(dropout)
def forward(self, src: Tensor, src_mask: Tensor):
"""
Args:
src: embedded sequences (batch_size, seq_length, d_model)
src_mask: mask for the sequences (batch_size, 1, 1, seq_length)
Returns:
src: sequences after self-attention (batch_size, seq_length, d_model)
"""
# pass the sequences through each encoder
for layer in self.layers:
src, attn_probs = layer(src, src_mask)
self.attn_probs = attn_probs
return src八、解码器

图片来源:作者
每个解码器层有两个职责:(1) 学习移位目标序列的自回归表示,以及 (2) 了解目标序列与编码器的丰富嵌入的关系。与编码器一样,解码器堆栈具有 Nx 解码器层。如前所述,编码器输出将传递到每个解码器层。
第一个解码器层的输入向右移动,并被嵌入和编码。它的形状为 (batch_size、seq_length、d_model)。它通过第一个注意力机制传递,其中模型学习序列与自身的自回归表示。该机制的输出保持其形状,并传递给第二个注意力机制。它与编码器的丰富嵌入相乘,输出再次保持其原始形状。
在通过FFN后,张量通过形状为(d_model,vocab_size)的最终线性层。这将创建一个大小为 (batch_size、seq_length、vocab_size) 的张量。这些是序列的对数。这些对数可以通过softmax函数传递,最高概率是每个令牌的预测。
class DecoderLayer(nn.Module):
def __init__(self, d_model: int, n_heads: int, d_ffn: int, dropout: float):
"""
Args:
d_model: dimension of embeddings
n_heads: number of heads
d_ffn: dimension of feed-forward network
dropout: probability of dropout occurring
"""
super().__init__()
# masked multi-head attention sublayer
self.masked_attention = MultiHeadAttention(d_model, n_heads, dropout)
# layer norm for masked multi-head attention
self.masked_attn_layer_norm = nn.LayerNorm(d_model)
# multi-head attention sublayer
self.attention = MultiHeadAttention(d_model, n_heads, dropout)
# layer norm for multi-head attention
self.attn_layer_norm = nn.LayerNorm(d_model)
# position-wise feed-forward network
self.positionwise_ffn = PositionwiseFeedForward(d_model, d_ffn, dropout)
# layer norm for position-wise ffn
self.ffn_layer_norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, trg: Tensor, src: Tensor, trg_mask: Tensor, src_mask: Tensor):
"""
Args:
trg: embedded sequences (batch_size, trg_seq_length, d_model)
src: embedded sequences (batch_size, src_seq_length, d_model)
trg_mask: mask for the sequences (batch_size, 1, trg_seq_length, trg_seq_length)
src_mask: mask for the sequences (batch_size, 1, 1, src_seq_length)
Returns:
trg: sequences after self-attention (batch_size, trg_seq_length, d_model)
attn_probs: self-attention softmax scores (batch_size, n_heads, trg_seq_length, src_seq_length)
"""
# pass trg embeddings through masked multi-head attention
_trg, attn_probs = self.masked_attention(trg, trg, trg, trg_mask)
# residual add and norm
trg = self.masked_attn_layer_norm(trg + self.dropout(_trg))
# pass trg and src embeddings through multi-head attention
_trg, attn_probs = self.attention(trg, src, src, src_mask)
# residual add and norm
trg = self.attn_layer_norm(trg + self.dropout(_trg))
# position-wise feed-forward network
_trg = self.positionwise_ffn(trg)
# residual add and norm
trg = self.ffn_layer_norm(trg + self.dropout(_trg))
return trg, attn_probs
class Decoder(nn.Module):
def __init__(self, vocab_size: int, d_model: int, n_layers: int,
n_heads: int, d_ffn: int, dropout: float = 0.1):
"""
Args:
vocab_size: size of the target vocabulary
d_model: dimension of embeddings
n_layers: number of encoder layers
n_heads: number of heads
d_ffn: dimension of feed-forward network
dropout: probability of dropout occurring
"""
super().__init__()
# create n_layers encoders
self.layers = nn.ModuleList([DecoderLayer(d_model, n_heads, d_ffn, dropout)
for layer in range(n_layers)])
self.dropout = nn.Dropout(dropout)
# set output layer
self.Wo = nn.Linear(d_model, vocab_size)
def forward(self, trg: Tensor, src: Tensor, trg_mask: Tensor, src_mask: Tensor):
"""
Args:
trg: embedded sequences (batch_size, trg_seq_length, d_model)
src: encoded sequences from encoder (batch_size, src_seq_length, d_model)
trg_mask: mask for the sequences (batch_size, 1, trg_seq_length, trg_seq_length)
src_mask: mask for the sequences (batch_size, 1, 1, src_seq_length)
Returns:
output: sequences after decoder (batch_size, trg_seq_length, vocab_size)
attn_probs: self-attention softmax scores (batch_size, n_heads, trg_seq_length, src_seq_length)
"""
# pass the sequences through each decoder
for layer in self.layers:
trg, attn_probs = layer(trg, src, trg_mask, src_mask)
self.attn_probs = attn_probs
return self.Wo(trg)九、变压器
编码器和解码器可以组合在一个模块中以创建转换器模型。可以使用编码器、解码器以及目标和源嵌入来初始化模块。
正向传递需要源序列和移位目标序列。源被嵌入并通过编码器传递。输出和嵌入的目标序列通过解码器传递。用于创建源掩码和目标掩码的函数也是模块的一部分。
对数是模型的输出。张量的大小为 (batch_size、seq_length、vocab_size)。
class Transformer(nn.Module):
def __init__(self, encoder: Encoder, decoder: Decoder,
src_embed: Embeddings, trg_embed: Embeddings,
src_pad_idx: int, trg_pad_idx: int, device):
"""
Args:
encoder: encoder stack
decoder: decoder stack
src_embed: source embeddings and encodings
trg_embed: target embeddings and encodings
src_pad_idx: padding index
trg_pad_idx: padding index
device: cuda or cpu
Returns:
output: sequences after decoder (batch_size, trg_seq_length, vocab_size)
"""
super().__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.trg_embed = trg_embed
self.device = device
self.src_pad_idx = src_pad_idx
self.trg_pad_idx = trg_pad_idx
def make_src_mask(self, src: Tensor):
"""
Args:
src: raw sequences with padding (batch_size, seq_length)
Returns:
src_mask: mask for each sequence (batch_size, 1, 1, seq_length)
"""
# assign 1 to tokens that need attended to and 0 to padding tokens, then add 2 dimensions
src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)
return src_mask
def make_trg_mask(self, trg: Tensor):
"""
Args:
trg: raw sequences with padding (batch_size, seq_length)
Returns:
trg_mask: mask for each sequence (batch_size, 1, seq_length, seq_length)
"""
seq_length = trg.shape[1]
# assign True to tokens that need attended to and False to padding tokens, then add 2 dimensions
trg_mask = (trg != self.trg_pad_idx).unsqueeze(1).unsqueeze(2) # (batch_size, 1, 1, seq_length)
# generate subsequent mask
trg_sub_mask = torch.tril(torch.ones((seq_length, seq_length), device=self.device)).bool() # (batch_size, 1, seq_length, seq_length)
# bitwise "and" operator | 0 & 0 = 0, 1 & 1 = 1, 1 & 0 = 0
trg_mask = trg_mask & trg_sub_mask
return trg_mask
def forward(self, src: Tensor, trg: Tensor):
"""
Args:
trg: raw target sequences (batch_size, trg_seq_length)
src: raw src sequences (batch_size, src_seq_length)
Returns:
output: sequences after decoder (batch_size, trg_seq_length, output_dim)
"""
# create source and target masks
src_mask = self.make_src_mask(src) # (batch_size, 1, 1, src_seq_length)
trg_mask = self.make_trg_mask(trg) # (batch_size, 1, trg_seq_length, trg_seq_length)
# push the src through the encoder layers
src = self.encoder(self.src_embed(src), src_mask) # (batch_size, src_seq_length, d_model)
# decoder output and attention probabilities
output = self.decoder(self.trg_embed(trg), src, trg_mask, src_mask)
return output十、生成模型
下面的简单函数初始化编码器、解码器、位置编码和嵌入。然后,它将这些内容传递到转换器模块中,以创建可训练的模型。在上一篇文章中,这些步骤是自行执行的,这是一个可接受的替代方法。
def make_model(device, src_vocab, trg_vocab, n_layers: int = 3, d_model: int = 512,
d_ffn: int = 2048, n_heads: int = 8, dropout: float = 0.1,
max_length: int = 5000):
"""
Construct a model when provided parameters.
Args:
src_vocab: source vocabulary
trg_vocab: target vocabulary
n_layers: Number of Encoder and Decoders
d_model: dimension of embeddings
d_ffn: dimension of feed-forward network
n_heads: number of heads
dropout: probability of dropout occurring
max_length: maximum sequence length for positional encodings
Returns:
Transformer model based on hyperparameters
"""
# create the encoder
encoder = Encoder(d_model, n_layers, n_heads, d_ffn, dropout)
# create the decoder
decoder = Decoder(len(trg_vocab), d_model, n_layers, n_heads, d_ffn, dropout)
# create source embedding matrix
src_embed = Embeddings(len(src_vocab), d_model)
# create target embedding matrix
trg_embed = Embeddings(len(trg_vocab), d_model)
# create a positional encoding matrix
pos_enc = PositionalEncoding(d_model, dropout, max_length)
# create the Transformer model
model = Transformer(encoder, decoder, nn.Sequential(src_embed, pos_enc),
nn.Sequential(trg_embed, pos_enc),
src_pad_idx=src_vocab.get_stoi()[""],
trg_pad_idx=trg_vocab.get_stoi()[""],
device=device)
# initialize parameters with Xavier/Glorot
for p in model.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model 十一、将德语翻译成英语
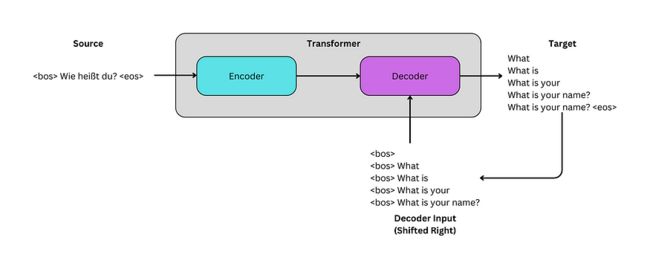
图片来源:作者
预处理数据
上一篇文章训练了一个转换器模型,使用一个小数据集从德语翻译成英语。本文将使用torchtext.datasets中的Multi30k数据集。它包含训练、验证和测试集。可以在附录中找到用于加载分词器、生成词汇表、处理数据和生成批处理的所有自定义函数。
第一步是从spaCy加载每种语言的分词器,并使用load_vocab为两种语言创建词汇表。它调用 build_vocabary,这是一个使用 torchtext.vocab 中的build_vocab_from_iterator函数的自定义函数。单词在词汇表中出现的最小频率为 2,词汇表中的每个单词都是小写的。build_vocabulary函数加载 Multi30k 数据集以生成词汇表。
# global variables used later in the script
spacy_de, spacy_en = load_tokenizers()
vocab_src, vocab_trg = load_vocab(spacy_de, spacy_en)Loaded English and German tokenizers.
Building German Vocabulary...
Building English Vocabulary...
Vocabulary sizes:
Source: 8147
Target: 6082 通过生成的词汇表,可以设置一些全局变量,这些变量将用大写字母表示。下面的变量用于“
BOS_IDX = vocab_trg['']
EOS_IDX = vocab_trg['']
PAD_IDX = vocab_trg[''] 可以加载数据集进行处理。
# raw data
train_data_raw, val_data_raw, test_data_raw = datasets.Multi30k(language_pair=("de", "en"))每个集合都是一个数据迭代器,可以将其视为元组列表。每个元组都包含一个德语-英语对,例如(“Wie heißt du?”,“你叫什么名字?”)。这些数据可以标记化并根据词汇转换为适当的索引。这些操作在自定义函数data_process中执行。
# processed data
train_data = data_process(train_data_raw)
val_data = data_process(val_data_raw)
test_data = data_process(test_data_raw)这些数据迭代器现在可以从torch.utils.data传递到DataLoader,该加载器可用于在训练期间生成批处理。DataLoader 需要一个数据迭代器、批大小和一个用于自定义批的整理函数。它还允许对批次进行随机排序,如果不是完整批次,则删除最后一个批次。提醒一下,批大小是每个优化步骤中使用的序列数。
在下面的代码中,MAX_PADDING表示序列可以具有的最大标记数。torch.nn.functional 中的 pad 函数截断任何比它长的序列,否则添加填充。这由generate_batch函数使用,该函数将“
MAX_PADDING = 20
BATCH_SIZE = 128
train_iter = DataLoader(to_map_style_dataset(train_data), batch_size=BATCH_SIZE,
shuffle=True, drop_last=True, collate_fn=generate_batch)
valid_iter = DataLoader(to_map_style_dataset(val_data), batch_size=BATCH_SIZE,
shuffle=True, drop_last=True, collate_fn=generate_batch)
test_iter = DataLoader(to_map_style_dataset(test_data), batch_size=BATCH_SIZE,
shuffle=True, drop_last=True, collate_fn=generate_batch)Creating the Model
下一步是创建模型来训练数据。make_model函数可以传递参数来创建模型,model.cuda() 可用于确保模型将在 GPU 上训练(如果可用)。这些值是根据经验选择的。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = make_model(device, vocab_src, vocab_trg,
n_layers=3, n_heads=8, d_model=256,
d_ffn=512, max_length=50)
model.cuda()还可以预览模型的总可训练参数以评估其大小。
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f'The model has {count_parameters(model):,} trainable parameters')The model has 9,159,362 trainable parameters.培训功能
为了训练模型,可以使用学习率为 0.0005 的 Adam 优化器,并且可以将交叉熵损失用于损失函数。交叉熵损失接受来自模型的对数作为输入,使用 softmax 函数转换它们,获取每个令牌的 argmax,并将它们与预期的目标输出进行比较。
LEARNING_RATE = 0.0005
optimizer = torch.optim.Adam(model.parameters(), lr = LEARNING_RATE)
criterion = nn.CrossEntropyLoss(ignore_index = PAD_IDX)可以使用以下函数训练模型,这些函数是每个时期要执行的步骤。该模型计算对数并根据损失更新参数。最后,该函数返回纪元中批次的平均损失。请注意,对数和预期输出被调整为单个序列,而不是单独的序列。对于 logits,给定 (3, 10, 27),由 27 个元素向量表示的三个十个标记序列,新形状将是 (30, 27),一个大序列。执行 argmax 时,输出是一个 30 个元素的向量。形状为 (3,10) 的预期输出也可以重新调整为 30 个元素向量,并且两者可以很容易地相互比较。
def train(model, iterator, optimizer, criterion, clip):
"""
Train the model on the given data.
Args:
model: Transformer model to be trained
iterator: data to be trained on
optimizer: optimizer for updating parameters
criterion: loss function for updating parameters
clip: value to help prevent exploding gradients
Returns:
loss for the epoch
"""
# set the model to training mode
model.train()
epoch_loss = 0
# loop through each batch in the iterator
for i, batch in enumerate(iterator):
# set the source and target batches
src,trg = batch
# zero the gradients
optimizer.zero_grad()
# logits for each output
logits = model(src, trg[:,:-1])
# expected output
expected_output = trg[:,1:]
# calculate the loss
loss = criterion(logits.contiguous().view(-1, logits.shape[-1]),
expected_output.contiguous().view(-1))
# backpropagation
loss.backward()
# clip the weights
torch.nn.utils.clip_grad_norm_(model.parameters(), clip)
# update the weights
optimizer.step()
# update the loss
epoch_loss += loss.item()
# return the average loss for the epoch
return epoch_loss / len(iterator)下面的评估函数执行与训练函数相同的过程,但它不会更新权重。这将与测试和验证集一起使用,以查看模型如何泛化。
def evaluate(model, iterator, criterion):
"""
Evaluate the model on the given data.
Args:
model: Transformer model to be trained
iterator: data to be evaluated
criterion: loss function for assessing outputs
Returns:
loss for the data
"""
# set the model to evaluation mode
model.eval()
epoch_loss = 0
# evaluate without updating gradients
with torch.no_grad():
# loop through each batch in the iterator
for i, batch in enumerate(iterator):
# set the source and target batches
src, trg = batch
# logits for each output
logits = model(src, trg[:,:-1])
# expected output
expected_output = trg[:,1:]
# calculate the loss
loss = criterion(logits.contiguous().view(-1, logits.shape[-1]),
expected_output.contiguous().view(-1))
# update the loss
epoch_loss += loss.item()
# return the average loss for the epoch
return epoch_loss / len(iterator)最后,可以创建最后一个函数来计算每个纪元需要多长时间。
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs训练模型
现在可以创建训练循环来训练模型并评估其在验证集上的性能。
N_EPOCHS = 10
CLIP = 1
best_valid_loss = float('inf')
# loop through each epoch
for epoch in range(N_EPOCHS):
start_time = time.time()
# calculate the train loss and update the parameters
train_loss = train(model, train_iter, optimizer, criterion, CLIP)
# calculate the loss on the validation set
valid_loss = evaluate(model, valid_iter, criterion)
end_time = time.time()
# calculate how long the epoch took
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
# save the model when it performs better than the previous run
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'transformer-model.pt')
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')Epoch: 01 | Time: 0m 21s
Train Loss: 4.534 | Train PPL: 93.169
Val. Loss: 3.474 | Val. PPL: 32.280
Epoch: 02 | Time: 0m 13s
Train Loss: 3.219 | Train PPL: 24.992
Val. Loss: 2.735 | Val. PPL: 15.403
Epoch: 03 | Time: 0m 13s
Train Loss: 2.544 | Train PPL: 12.733
Val. Loss: 2.225 | Val. PPL: 9.250
Epoch: 04 | Time: 0m 14s
Train Loss: 2.096 | Train PPL: 8.131
Val. Loss: 1.980 | Val. PPL: 7.246
Epoch: 05 | Time: 0m 13s
Train Loss: 1.801 | Train PPL: 6.055
Val. Loss: 1.829 | Val. PPL: 6.229
Epoch: 06 | Time: 0m 14s
Train Loss: 1.588 | Train PPL: 4.896
Val. Loss: 1.743 | Val. PPL: 5.717
Epoch: 07 | Time: 0m 13s
Train Loss: 1.427 | Train PPL: 4.166
Val. Loss: 1.700 | Val. PPL: 5.476
Epoch: 08 | Time: 0m 13s
Train Loss: 1.295 | Train PPL: 3.650
Val. Loss: 1.679 | Val. PPL: 5.358
Epoch: 09 | Time: 0m 13s
Train Loss: 1.184 | Train PPL: 3.268
Val. Loss: 1.677 | Val. PPL: 5.349
Epoch: 10 | Time: 0m 13s
Train Loss: 1.093 | Train PPL: 2.984
Val. Loss: 1.677 | Val. PPL: 5.351在评估结果之前,还可以使用评估功能在测试集上评估准确性。
# load the weights
model.load_state_dict(torch.load('transformer-model.pt'))
# calculate the loss on the test set
test_loss = evaluate(model, test_iter, criterion)
print(f'Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f}')Test Loss: 1.692 | Test PPL: 5.430虽然损失已显着减少,但没有迹象表明该模型在从德语翻译成英语方面有多成功。这可以通过两种方式进行评估。首先是给它一个句子,并在推理过程中预览它的翻译。第二种是通过另一个指标(如BLEU)计算其准确性,这是翻译任务的标准。
推理
可以通过将句子传递给下面的函数来执行实时翻译。它将被标记化并通过模型传递,一次生成一个令牌。一旦出现“
def translate_sentence(sentence, model, device, max_length = 50):
"""
Translate a German sentence to its English equivalent.
Args:
sentence: German sentence to be translated to English; list or str
model: Transformer model used for translation
device: device to perform translation on
max_length: maximum token length for translation
Returns:
src: return the tokenized input
trg_input: return the input to the decoder before the final output
trg_output: return the final translation, shifted right
attn_probs: return the attention scores for the decoder heads
masked_attn_probs: return the masked attention scores for the decoder heads
"""
model.eval()
# tokenize and index the provided string
if isinstance(sentence, str):
src = [''] + [token.text.lower() for token in spacy_de(sentence)] + ['']
else:
src = [''] + sentence + ['']
# convert to integers
src_indexes = [vocab_src[token] for token in src]
# convert list to tensor
src_tensor = torch.tensor(src_indexes).int().unsqueeze(0).to(device)
# set token for target generation
trg_indexes = [vocab_trg.get_stoi()['']]
# generate new tokens
for i in range(max_length):
# convert the list to a tensor
trg_tensor = torch.tensor(trg_indexes).int().unsqueeze(0).to(device)
# generate the next token
with torch.no_grad():
# generate the logits
logits = model.forward(src_tensor, trg_tensor)
# select the newly predicted token
pred_token = logits.argmax(2)[:,-1].item()
# if token or max length, stop generating
if pred_token == vocab_trg.get_stoi()[''] or i == (max_length-1):
# decoder input
trg_input = vocab_trg.lookup_tokens(trg_indexes)
# decoder output
trg_output = vocab_trg.lookup_tokens(logits.argmax(2).squeeze(0).tolist())
return src, trg_input, trg_output, model.decoder.attn_probs, model.decoder.masked_attn_probs
# else, continue generating
else:
# add the token
trg_indexes.append(pred_token) 训练集中的示例可用于确保生成的可视化演示注意力的工作原理。
# 'a woman with a large purse is walking by a gate'
src = ['eine', 'frau', 'mit', 'einer', 'großen', 'geldbörse', 'geht', 'an', 'einem', 'tor', 'vorbei', '.']
src, trg_input, trg_output, attn_probs, masked_attn_probs = translate_sentence(src, model, device)
print(f'source = {src}')
print(f'target input = {trg_input}')
print(f'target output = {trg_output}')source = ['', 'eine', 'frau', 'mit', 'einer', 'großen', 'geldbörse', 'geht', 'an', 'einem', 'tor', 'vorbei', '.', '']
target input = ['', 'a', 'woman', 'with', 'a', 'large', 'purse', 'walking', 'past', 'a', 'gate', '.']
target output = ['a', 'woman', 'with', 'a', 'large', 'purse', 'walking', 'past', 'a', 'gate', '.', ''] 目标输出是模型对源序列的预测,目标输入是生成序列结束标记之前解码器的最终输入。这是使用注意力矩阵中的源序列可视化的内容。
display_attention(src, trg_input, attn_probs)
图片来源:作者
屏蔽的注意力矩阵也可以与目标输入一起查看。
display_attention(trg_input, trg_input, masked_attn_probs)
图片来源:作者
尽管这些是有用的可视化效果,但训练集中没有的句子可用于确定模型对实际翻译的有用性。以下两个示例来自测试集。
# A guy works on a building
src = 'Ein Typ arbeitet an einem Gebäude.'
src, trg_input, trg_output, attn_probs, masked_attn_probs = translate_sentence(src, model, device)
print(f'source = {src}')
print(f'target input = {trg_input}')
print(f'target output = {trg_output}')source = ['', 'ein', 'typ', 'arbeitet', 'an', 'einem', 'gebäude', '.', '']
target input = ['', 'a', 'guy', 'working', 'on', 'a', 'building', '.']
target output = ['a', 'guy', 'working', 'on', 'a', 'building', '.', ''] 第一个示例是有效的翻译,但第二个示例不是。
# A mother teaches her two young boys to fish off of a rocky coast into very blue water.
src = 'Eine Mutter bringt ihren zwei kleinen Söhnen an einer felsigen Küste mit sehr blauem Wasser das Angeln bei.'
src, trg_input, trg_output, attn_probs, masked_attn_probs = translate_sentence(src, model, device)
print(f'source = {src}')
print(f'target input = {trg_input}')
print(f'target output = {trg_output}')source = ['', 'eine', 'mutter', 'bringt', 'ihren', 'zwei', 'kleinen', 'söhnen', 'an', 'einer', 'felsigen', 'küste', 'mit', 'sehr', 'blauem', 'wasser', 'das', 'angeln', 'bei', '.', '']
target input = ['', 'a', 'mother', 'is', 'training', 'her', 'two', 'small', 'sons', 'to', 'the', 'shore', 'of', 'a', 'rocky', 'shore', 'with', 'very', 'tall', 'blue', 'shore', '.']
target output = ['a', 'mother', 'is', 'training', 'her', 'two', 'small', 'sons', 'to', 'the', 'shore', 'of', 'a', 'rocky', 'shore', 'with', 'very', 'tall', 'blue', 'shore', '.', ''] 为了评估模型在整个测试集上的准确度,现在可以计算BLEU分数。
BLEU分数
双语评估替补 (BLEU) 是评估机器翻译模型的常用指标。分数范围介于 0 和 1 之间,1 表示预测和预期翻译相同。
根据Google的AutoML文档,BLEU分数的值可以具有以下含义(以百分比表示):
- <10:几乎没用
- 10-19:难以理解
- 20-29:可理解但严重的语法错误
- 30-39岁:可以理解
- 40-49:高品质
- 50-59:高质量、充足、流利
- >60:优于人类品质
若要计算BLEU分数,需要生成模型的预测及其期望值。这可以通过下面的功能完成,该函数利用translate_sentence功能。
def compute_metrics(model, iterator):
"""
Generate predictions for the provided iterator.
Args:
model: Transformer model to be trained
iterator: data to be evaluated
Returns:
predictions: list of predictions, which are tokenized strings
labels: list of expected output, which are tokenized strings
"""
# set the model to evaluation mode
model.eval()
predictions = []
labels = []
# evaluate without updating gradients
with torch.no_grad():
# loop through each batch in the iterator
for i, batch in enumerate(iterator):
# set the source and target batches
src, trg = batch
# predict the output
src_out, trg_input, trg_output, attn_probs, masked_attn_probs = translate_sentence(vocab_src.lookup_tokens(src.tolist()), model, device)
# prediction | remove token
predictions.append(trg_output[:-1])
# expected output | add extra dim for calculation
labels.append([vocab_trg.lookup_tokens(trg.tolist())])
# return the average loss for the epoch
return predictions, labels 之前生成的包含标记化序列的test_data可以传递给compute_metrics函数。然后,可以将预测和标签从torchtext.data.metrics传递给bleu_score,以计算BLEU分数。
from torchtext.data.metrics import bleu_score
bleu_score(predictions, labels)0.3588869571685791此输出表明翻译是可以理解的,这是本教程可接受的结果。完成此示例后,已实施的变压器系列将结束。
请不要忘记点赞和关注更多!:)
引用
- 迪帕克·赛尼的变压器实现
- 哈佛的《带注释的变压器》
附录
包
!pip install -q portalocker
# importing required libraries
import math
import copy
import time
import random
import spacy
import numpy as np
import os
# torch packages
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
import torch.optim as optim
# load and build datasets
import torchtext
from torchtext.data.functional import to_map_style_dataset
from torch.nn.functional import pad
from torch.utils.data import DataLoader
from torchtext.vocab import build_vocab_from_iterator
import torchtext.datasets as datasets
import portalocker
# visualization packages
from mpl_toolkits import mplot3d
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker加载分词器
此函数下载 spaCy 提供的德语和英语分词器。
def load_tokenizers():
"""
Load the German and English tokenizers provided by spaCy.
Returns:
spacy_de: German tokenizer
spacy_en: English tokenizer
"""
try:
spacy_de = spacy.load("de_core_news_sm")
except OSError:
os.system("python -m spacy download de_core_news_sm")
spacy_de = spacy.load("de_core_news_sm")
try:
spacy_en = spacy.load("en_core_web_sm")
except OSError:
os.system("python -m spacy download en_core_web_sm")
spacy_en = spacy.load("en_core_web_sm")
print("Loaded English and German tokenizers.")
return spacy_de, spacy_en标记序列
此函数使用 spaCy 标记器来标记提供的序列。
def tokenize(text: str, tokenizer):
"""
Split a string into its tokens using the provided tokenizer.
Args:
text: string
tokenizer: tokenizer for the language
Returns:
tokenized list of strings
"""
return [tok.text.lower() for tok in tokenizer.tokenizer(text)]收益代币
此函数调用提供的分词器以生成正确语言的分词。如果索引 = 0,则德语被标记化。如果索引 = 1,则标记英语。数据迭代器中的每个元组都包含一个德语-英语对,例如(“Wie heißt du?”,“你叫什么名字?”)。
def yield_tokens(data_iter, tokenizer, index: int):
"""
Return the tokens for the appropriate language.
Args:
data_iter: text here
tokenizer: tokenizer for the language
index: index of the language in the tuple | (de=0, en=1)
Yields:
sequences based on index
"""
for from_tuple in data_iter:
yield tokenizer(from_tuple[index])建立词汇量
此函数接受德语和英语 spaCy 分词器作为参数,并接受单词包含在词汇表中所需的最小频率。tokenize_de 和 tokenize_en 函数调用 tokenize 并传递每种语言的相应分词器。
德语-英语数据集是使用数据集加载的。Multi30k(language_pair = (“de”, “en”))。这将返回可以迭代以生成词汇表的训练集、验证集和测试集。
torchtext.vocab 的 build_vocab_from_iterator 函数用于构建包含所有这些组件的词汇表。它使用yield_tokens为每个序列生成令牌。yield_tokens采用 train + val + test,它创建一个包含所有源的数据迭代器、相应语言的标记化函数(tokenize_de 或 tokenize_en)以及迭代器中语言的相应索引(0 表示德语,1 表示英语)。它还需要最小频率和特殊令牌。特殊令牌是
- “
”表示序列的开始 - “
”表示序列的结尾 - “
”用于填充 - “
”表示词汇表中不存在的标记
def build_vocabulary(spacy_de, spacy_en, min_freq: int = 2):
def tokenize_de(text: str):
"""
Call the German tokenizer.
Args:
text: string
min_freq: minimum frequency needed to include a word in the vocabulary
Returns:
tokenized list of strings
"""
return tokenize(text, spacy_de)
def tokenize_en(text: str):
"""
Call the English tokenizer.
Args:
text: string
Returns:
tokenized list of strings
"""
return tokenize(text, spacy_en)
print("Building German Vocabulary...")
# load train, val, and test data pipelines
train, val, test = datasets.Multi30k(language_pair=("de", "en"))
# generate source vocabulary
vocab_src = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_de, index=0), # tokens for each German sentence (index 0)
min_freq=min_freq,
specials=["", "", "", ""],
)
print("Building English Vocabulary...")
# generate target vocabulary
vocab_trg = build_vocab_from_iterator(
yield_tokens(train + val + test, tokenize_en, index=1), # tokens for each English sentence (index 1)
min_freq=2, #
specials=["", "", "", ""],
)
# set default token for out-of-vocabulary words (OOV)
vocab_src.set_default_index(vocab_src[""])
vocab_trg.set_default_index(vocab_trg[""])
return vocab_src, vocab_trg 加载词汇
此函数生成并保存词汇表(如果尚未创建)。否则,它会加载词汇表。它需要空间分词器和最小频率作为输入。
def load_vocab(spacy_de, spacy_en, min_freq: int = 2):
"""
Args:
spacy_de: German tokenizer
spacy_en: English tokenizer
min_freq: minimum frequency needed to include a word in the vocabulary
Returns:
vocab_src: German vocabulary
vocab_trg: English vocabulary
"""
if not os.path.exists("vocab.pt"):
# build the German/English vocabulary if it does not exist
vocab_src, vocab_trg = build_vocabulary(spacy_de, spacy_en, min_freq)
# save it to a file
torch.save((vocab_src, vocab_trg), "vocab.pt")
else:
# load the vocab if it exists
vocab_src, vocab_trg = torch.load("vocab.pt")
print("Finished.\nVocabulary sizes:")
print("\tSource:", len(vocab_src))
print("\tTarget:", len(vocab_trg))
return vocab_src, vocab_trg索引序列
此函数接受原始的德语-英语元组,标记它们,将它们转换为张量,并返回元组列表。
def data_process(raw_data):
"""
Process raw sentences by tokenizing and converting to integers based on
the vocabulary.
Args:
raw_data: German-English sentence pairs
Returns:
data: tokenized data converted to index based on vocabulary
"""
data = []
# loop through each sentence pair
for (raw_de, raw_en) in raw_data:
# tokenize the sentence and convert each word to an integers
de_tensor_ = torch.tensor([vocab_src[token.text.lower()] for token in spacy_de.tokenizer(raw_de)], dtype=torch.long)
en_tensor_ = torch.tensor([vocab_trg[token.text.lower()] for token in spacy_en.tokenizer(raw_en)], dtype=torch.long)
# append tensor representations
data.append((de_tensor_, en_tensor_))
return data生成批处理
此函数用于将开始、结束和填充标记添加到索引序列。
def generate_batch(data_batch):
"""
Process indexed-sequences by adding , , and tokens.
Args:
data_batch: German-English indexed-sentence pairs
Returns:
two batches: one for German and one for English
"""
de_batch, en_batch = [], []
# for each sentence
for (de_item, en_item) in data_batch:
# add and indices before and after the sentence
de_temp = torch.cat([torch.tensor([BOS_IDX]), de_item, torch.tensor([EOS_IDX])], dim=0).to(device)
en_temp = torch.cat([torch.tensor([BOS_IDX]), en_item, torch.tensor([EOS_IDX])], dim=0).to(device)
# add padding
de_batch.append(pad(de_temp,(0, # dimension to pad
MAX_PADDING - len(de_temp), # amount of padding to add
),value=PAD_IDX,))
# add padding
en_batch.append(pad(en_temp,(0, # dimension to pad
MAX_PADDING - len(en_temp), # amount of padding to add
),
value=PAD_IDX,))
return torch.stack(de_batch), torch.stack(en_batch) 显示注意力
此函数可以显示自我注意、屏蔽注意和源目标注意。
def display_attention(sentence: list, translation: list, attention: Tensor,
n_heads: int = 8, n_rows: int = 4, n_cols: int = 2):
"""
Display the attention matrix for each head of a sequence.
Args:
sentence: German sentence to be translated to English; list
translation: English sentence predicted by the model
attention: attention scores for the heads
n_heads: number of heads
n_rows: number of rows
n_cols: number of columns
"""
# ensure the number of rows and columns are equal to the number of heads
assert n_rows * n_cols == n_heads
# figure size
fig = plt.figure(figsize=(15,25))
# visualize each head
for i in range(n_heads):
# create a plot
ax = fig.add_subplot(n_rows, n_cols, i+1)
# select the respective head and make it a numpy array for plotting
_attention = attention.squeeze(0)[i,:,:].cpu().detach().numpy()
# plot the matrix
cax = ax.matshow(_attention, cmap='bone')
# set the size of the labels
ax.tick_params(labelsize=12)
# set the indices for the tick marks
ax.set_xticks(range(len(sentence)))
ax.set_yticks(range(len(translation)))
# if the provided sequences are sentences or indices
if isinstance(sentence[0], str):
ax.set_xticklabels([t.lower() for t in sentence], rotation=45)
ax.set_yticklabels(translation)
elif isinstance(sentence[0], int):
ax.set_xticklabels(sentence)
ax.set_yticklabels(translation)
plt.show()整合一切:已实施的变压器 |作者:亨特·菲利普斯 |中等 (medium.com)