1 问题现象
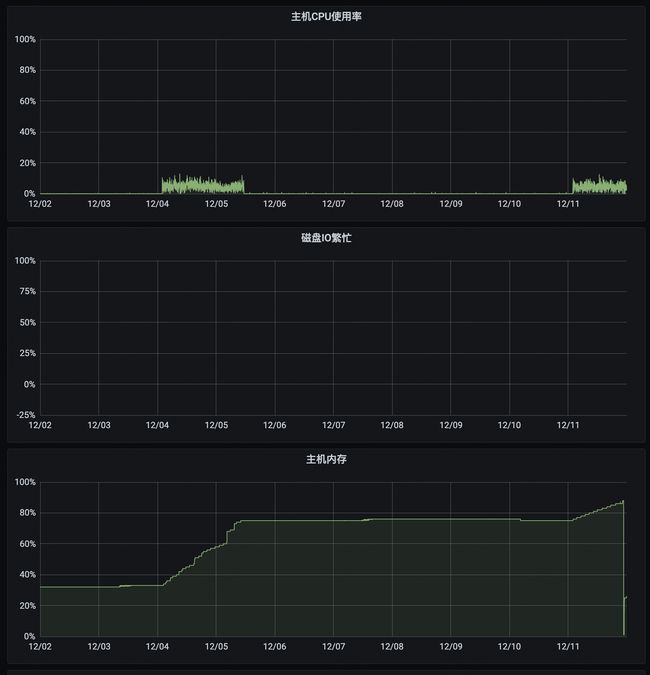
路由计算服务是路由系统的核心服务,负责运单路由计划的计算以及实操与计划的匹配。在运维过程中,发现在长期不重启的情况下,有TP99缓慢爬坡的现象。此外,在每周例行调度的试算过程中,能明显看到内存的上涨。以下截图为这两个异常情况的监控。
 []()
[]()
TP99爬坡
 []()
[]()
内存爬坡
机器配置如下
CPU: 16C RAM: 32G
Jvm配置如下:
-Xms20480m (后面切换到了8GB) -Xmx20480m (后面切换到了8GB) -XX:MaxPermSize=2048m -XX:MaxGCPauseMillis=200 -XX:+ParallelRefProcEnabled -XX:+PrintReferenceGC -XX:+UseG1GC -Xss256k -XX:ParallelGCThreads=16 -XX:ConcGCThreads=4 -XX:MaxDirectMemorySize=2g -Dsun.net.inetaddr.ttl=600 -Dlog4j2.contextSelector=org.apache.logging.log4j.core.async.AsyncLoggerContextSelector -Dlog4j2.asyncQueueFullPolicy=Discard -XX:MetaspaceSize=1024M -XX:G1NewSizePercent=35 -XX:G1MaxNewSizePercent=35
例行任务调度情况:
每周一凌晨2:00触发执行。上面截图,共包含了两个周期的任务。可以看到,在第一次执行时,内存直接从33%爬升至75%。在第二次执行时,爬坡至88%后,OOM异常退出。
2 问题排查
由于有两种现象,所以排查有两条主线。第一条是以追踪OOM原因为目的的内存使用情况排查,简称内存问题排查。第二条是TP99缓慢增长原因排查,简称性能下降问题排查。
2.1 性能下降问题排查
由于是缓慢爬坡,而且爬坡周期与服务重启有直接关系,所以可以排出外部接口性能问题的可能。优先从自身程序找原因。因此,首先排查GC情况和内存情况。下面是经过长期未重启的GC log。这是一次YGC,总耗时1.16秒。其中Ref Proc环节消耗了1150.3 ms,其中的JNI Weak Reference的回收消耗了1.1420596秒。而在刚重启的机器上,JNI Weak Reference的回收时间为0.0000162秒。所以可以定位到,TP99增加就是JNI Weak Reference回收周期增长导致的。
 []()
[]()
JNI Weak Reference顾名思义,应该跟Native memory的使用有关。不过由于Native memory排查难度较大。所以还是先从堆的使用情况开始排查,以碰碰运气的心态,看是否能发现蛛丝马迹。
2.2 内存问题排查
回到内存方面,经过建哥提示,应该优先复现问题。并且在每周触发的任务都会稳定复现内存上涨,所以从调度任务这个方向,排查更容易一些。通过@柳岩的帮助,具备了在试算环境随时复现问题的能力。
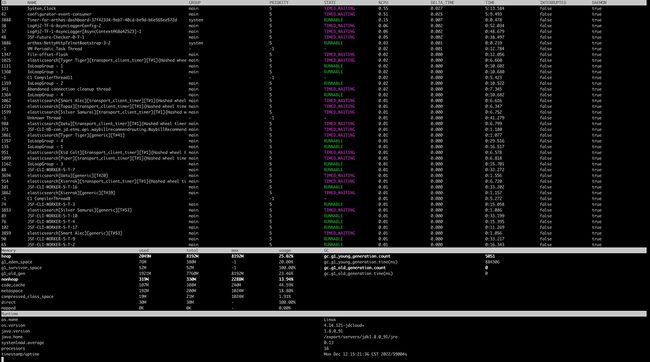
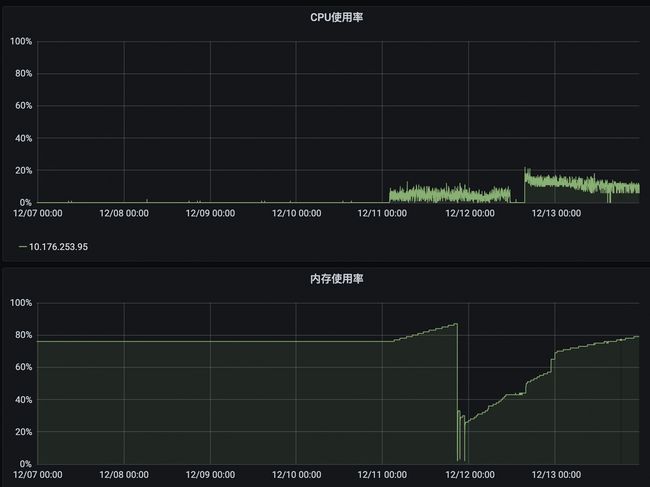
内存问题排查,仍然是从堆内内存开始。多次dump后,尽管java进程的总内存使用量持续上涨,但是堆内存使用量并未见明显增长。通过申请root权限,并部署arthas后,通过arthas的dashbord功能,可以明显看到,堆(heap)和非堆(nonheap)都保持平稳。
 []()
[]()
arthas dashboard
 []()
[]()
内存使用情况,存在翻倍现象
由此可以断定,是native memory使用量增长,导致整个java应用的内存使用率增长。分析native的第一步是需要jvm开启-XX:NativeMemoryTracking=detail。
2.2.1 使用jcmd查看内存整体情况
jcmd可以打印java进程所有内存分配情况,当开启NativeMemoryTracking=detail参数后,可以看到native方法调用栈信息。在申请root权限后,直接使用yum安装即可。
安装好后,执行如下命令。
jcmd VM.native_memory detail  []()
[]()
jcmd结果展示
上图中,共包含两部分,第一部分是内存总体情况摘要,包括总内存使用量,以及分类使用情况。分类包括:Java Heap、Class、Thread、Code、GC、Compiler、Internal、Symbol、Native Memory Tracking、Arena Chunk、Unknown,每个分类的介绍,可以看这篇文档;第二部分是详情,包括了每段内存分配的起始地址和结束地址,具体大小,和所属的分类。比如截图中的部分,是描述了为Java heap分配了8GB的内存(后面为了快速复现问题,heap size从20GB调整为8GB)。后面缩进的行,代表了内存具体分配的情况。
间隔2小时,使用jcmd dump两次后,进行对比。可以看到Internal这部分,有明显的增长。Internal是干什么的,为什么会增长?经过Google,发现此方面的介绍非常少,基本就是命令行解析、JVMTI等调用。请教@崔立群后,了解到JVMTI可能与java agent相关,在路由计算中,应该只有pfinder与java agent有关,但是底层中间件出问题的影响面,不应该只有路由一家,所以只是问了一下pfinder研发,就没再继续投入跟进。
2.2.2 使用pmap和gdb分析内存
首先给出此方式的结论,这种分析由于包含了比较大的猜测的成分,所以不建议优先尝试。整体的思路是,使用pmap将java进程分配的所有内存进行输出,挑选出可疑的内存区间,使用gdb进行dump,并编码可视化其内容,进行分析。
网上有很多相关博客,都通过分析存在大量的64MB内存分配块,从而定位到了链接泄漏的案例。所以我也在我们的进程上查看了一下,确实包含很多64MB左右的内存占用。按照博客中介绍,将内存编码后,内容大部分为JSF相关,可以推断是JSF netty 使用的内存池。我们使用的1.7.4版本的JSF并未有内存池泄漏问题,所以应当与此无关。
pmap:https://docs.oracle.com/cd/E56344_01/html/E54075/pmap-1.html
gdb:https://segmentfault.com/a/1190000024435739
2.2.3 使用strace分析系统调用情况
这应该算是碰运气的一种分析方法了。思路就是使用strace将每次分配内存的系统调用输出,然后与jstack中线程进行匹配。从而确定具体是由哪个java线程分配的native memory。这种效率最低,首先系统调用非常频繁,尤其在RPC较多的服务上面。所以除了比较明显的内存泄漏情况,容易用此种方式排查。如本文的缓慢内存泄漏,基本都会被正常调用淹没,难以观察。
2.3 问题定位
经过一系列尝试,均没有定位根本原因。所以只能再次从jcmd查出的Internal内存增长这个现象入手。到目前,还有内存分配明细这条线索没有分析,尽管有1.2w行记录,只能顺着捋一遍,希望能发现Internal相关的线索。
通过下面这段内容,可以看到分配32k Internal内存空间后,有两个JNIHandleBlock相关的内存分配,分别是4GB和2GB,MemberNameTable相关调用,分配了7GB内存。
[0x00007fa4aa9a1000 - 0x00007fa4aa9a9000] reserved and committed 32KB for Internal from
[0x00007fa4a97be272] PerfMemory::create_memory_region(unsigned long)+0xaf2
[0x00007fa4a97bcf24] PerfMemory::initialize()+0x44
[0x00007fa4a98c5ead] Threads::create_vm(JavaVMInitArgs*, bool*)+0x1ad
[0x00007fa4a952bde4] JNI_CreateJavaVM+0x74
[0x00007fa4aa9de000 - 0x00007fa4aaa1f000] reserved and committed 260KB for Thread Stack from
[0x00007fa4a98c5ee6] Threads::create_vm(JavaVMInitArgs*, bool*)+0x1e6
[0x00007fa4a952bde4] JNI_CreateJavaVM+0x74
[0x00007fa4aa3df45e] JavaMain+0x9e
Details:
[0x00007fa4a946d1bd] GenericGrowableArray::raw_allocate(int)+0x17d
[0x00007fa4a971b836] MemberNameTable::add_member_name(_jobject*)+0x66
[0x00007fa4a9499ae4] InstanceKlass::add_member_name(Handle)+0x84
[0x00007fa4a971cb5d] MethodHandles::init_method_MemberName(Handle, CallInfo&)+0x28d
(malloc=7036942KB #10)
[0x00007fa4a9568d51] JNIHandleBlock::allocate_handle(oopDesc*)+0x2f1
[0x00007fa4a9568db1] JNIHandles::make_weak_global(Handle)+0x41
[0x00007fa4a9499a8a] InstanceKlass::add_member_name(Handle)+0x2a
[0x00007fa4a971cb5d] MethodHandles::init_method_MemberName(Handle, CallInfo&)+0x28d
(malloc=4371507KB #14347509)
[0x00007fa4a956821a] JNIHandleBlock::allocate_block(Thread*)+0xaa
[0x00007fa4a94e952b] JavaCallWrapper::JavaCallWrapper(methodHandle, Handle, JavaValue*, Thread*)+0x6b
[0x00007fa4a94ea3f4] JavaCalls::call_helper(JavaValue*, methodHandle*, JavaCallArguments*, Thread*)+0x884
[0x00007fa4a949dea1] InstanceKlass::register_finalizer(instanceOopDesc*, Thread*)+0xf1
(malloc=2626130KB #8619093)
[0x00007fa4a98e4473] Unsafe_AllocateMemory+0xc3
[0x00007fa496a89868]
(malloc=239454KB #723)
[0x00007fa4a91933d5] ArrayAllocator::allocate(unsigned long)+0x175
[0x00007fa4a9191cbb] BitMap::resize(unsigned long, bool)+0x6b
[0x00007fa4a9488339] OtherRegionsTable::add_reference(void*, int)+0x1c9
[0x00007fa4a94a45c4] InstanceKlass::oop_oop_iterate_nv(oopDesc*, FilterOutOfRegionClosure*)+0xb4
(malloc=157411KB #157411)
[0x00007fa4a956821a] JNIHandleBlock::allocate_block(Thread*)+0xaa
[0x00007fa4a94e952b] JavaCallWrapper::JavaCallWrapper(methodHandle, Handle, JavaValue*, Thread*)+0x6b
[0x00007fa4a94ea3f4] JavaCalls::call_helper(JavaValue*, methodHandle*, JavaCallArguments*, Thread*)+0x884
[0x00007fa4a94eb0d1] JavaCalls::call_virtual(JavaValue*, KlassHandle, Symbol*, Symbol*, JavaCallArguments*, Thread*)+0x321
(malloc=140557KB #461314) 通过对比两个时间段的jcmd的输出,可以看到JNIHandleBlock相关的内存分配,确实存在持续增长的情况。因此可以断定,就是JNIHandles::make_weak_global 这部分内存分配,导致的泄漏。那么这段逻辑在干什么,是什么导致的泄漏?
通过Google,找到了Jvm大神的文章,为我们解答了整个问题的来龙去脉。问题现象与我们的基本一致。博客:https://blog.csdn.net/weixin_45583158/article/details/100143231
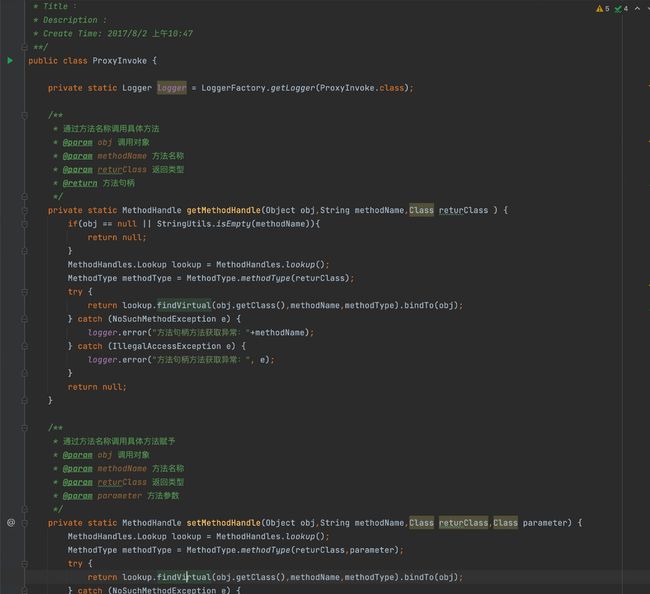
其中,寒泉子给出了一个复现问题的代码。在我们的代码中有一段几乎一摸一样的,这确实包含了运气成分。
// 博客中的代码
public static void main(String args[]){
while(true){
MethodType type = MethodType.methodType(double.class, double.class);
try {
MethodHandle mh = lookup.findStatic(Math.class, "log", type);
} catch (NoSuchMethodException e) {
e.printStackTrace();
} catch (IllegalAccessException e) {
e.printStackTrace();
}
}
}
} []()
[]()
jvm bug:https://bugs.openjdk.org/browse/JDK-8152271
就是上面这个bug,频繁使用MethodHandles相关反射,会导致过期对象无法被回收,同时会引发YGC扫描时间增长,导致性能下降。
3 问题解决
由于jvm 1.8已经明确表示,不会在1.8处理这个问题,会在java 重构。但是我们短时间也没办法升级到java 。所以没办法通过直接升级JVM进行修复。由于问题是频繁使用反射,所以考虑了添加缓存,让频率降低,从而解决性能下降和内存泄漏的问题。又考虑到线程安全的问题,所以将缓存放在ThreadLocal中,并添加LRU的淘汰规则,避免再次泄漏情况发生。
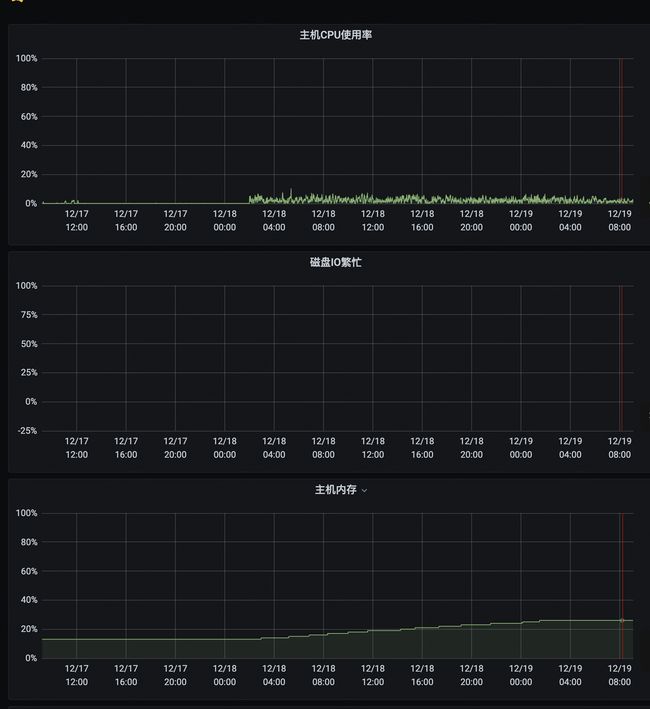
最终修复效果如下,内存增长控制在正常的堆内存设置范围内(8GB),增涨速度较温和。重启2天后,JNI Weak Reference时间为0.0001583秒,符合预期。
 []()
[]()
4 总结
Native memory leak的排查思路与堆内内存排查类似,主要是以分时dump和对比为主。通过观察异常值或异常增长量的方式,确定问题原因。由于工具差异,Native memory的排查过程,难以将内存泄漏直接与线程相关联,可以通过strace方式碰碰运气。此外,根据有限的线索,在搜索引擎上进行搜索,也许会搜到相关的排查过程,收到意外惊喜。毕竟jvm还是非常可靠的软件,所以如果存在比较严重的问题,应该很容易在网上找到相关的解决办法。如果网上的内容较少,那可能还是需要考虑,是不是用了过于小众的软件依赖。
在开发方面,尽量使用主流的开发设计模式。尽管技术没有好坏之分,但是像反射、AOP等实现方式,需要限制使用范围。因为这些技术,会影响代码的可读性,并且性能也是在不断增加的AOP中,逐步变差的。另外,在新技术尝试方面,尽量从边缘业务开始。在核心应用中,首先需要考虑的就是稳定性问题,这种意识可以避免踩一些别人难以遇到的坑,从而减少不必要的麻烦。
作者:京东物流 陈昊龙
来源:京东云开发者社区