用 AI 取代人工?或许 LLMs 可以给你答案
近日,比尔盖茨在 reddit 回答「巨大的技术变革」是什么时,他回复道:
「 Web3 没那么重要,元宇宙也没那么大的革命性,人工智能是最重要的。」

确实,随着 ChatGPT 爆红网络,数百家创业公司正冲进来,开发基础模型,构建 AI 原生应用,建设基础设施或工具等等, 而 ChatGPT 所用的 LLMs 模型也逐渐走入了大家的视线中。
那让 AI 领域发生大规模变革的 LLMs 究竟是什么呢?
01
LLMs 是什么?
LLMs 全称 Large Language Models (大型语言模型),是基于自然语言处理( NLP )和超过 1000 亿个不同参数的人工智能训练模型。过去几年, LLMs 被广泛运用在了搜索、推荐、智能对话、智能机器交互、文本生成等语言类的自然语言技术处理上。
得益于数十亿参数的模型,大型语言模型在语言( language )、理解( understanding )、智能( intelligence )的本质方面有很多东西可以“传授”给我们,从某种程度上来说 LLMs 在文本生成、对话聊天上做意图理解的能力,帮我们节省了很多检索信息的时间成本。
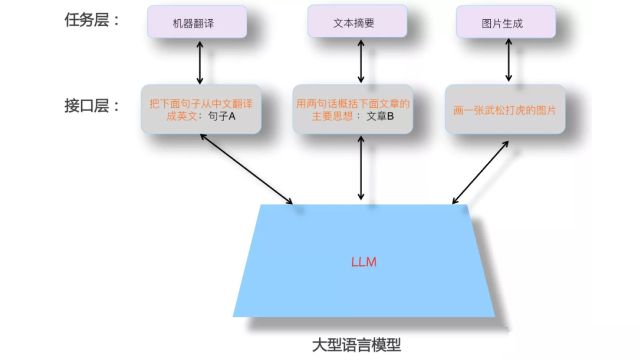
大型语言模型( Large Language Models,LLMs )代表了人工智能的一大进步,特别是朝着“类人( human-like )”的通用人工智能的目标迈进。
02
LLMs 的特点
所谓语言模型,就是让机器理解并预测人类语言的技术。比如在某一句话说一半的时候,这个模型会根据以往记录的实例,来推断出这句话后面的几个字,从而达到快速续写、改写的内容产出效果。
而大型语言模型指的是一种利用深度学习的算法,通过数千本书和互联网的大量文本进行训练,将这种“推断能力”发挥出最大的效果,让单词和单词之间快速串联、自动生成更准确的表述。
03
LLMs 的技术能力
规模效应
LLMs 在整体的规模效应上表现出了固定规律,即模型规模增大,模型性能不断提高。
通过 GPT 的不断升级,我们可以判断出,当 LLMs 被更多量的文本进行训练,即可产生更大的模型,在语言理解的准确率上就会更高。
理解能力
伴随着 LLMs 的问世,关于语言模型的“理解”,也出现了很多褒贬不一的声音,有人认为 LLMs 具备了意图性或响应真实世界中的请求的能力,这代表其已经足够智能;但也有人说 LLMs 只是具备了在大数据中进行模仿的能力,而非足够智能。
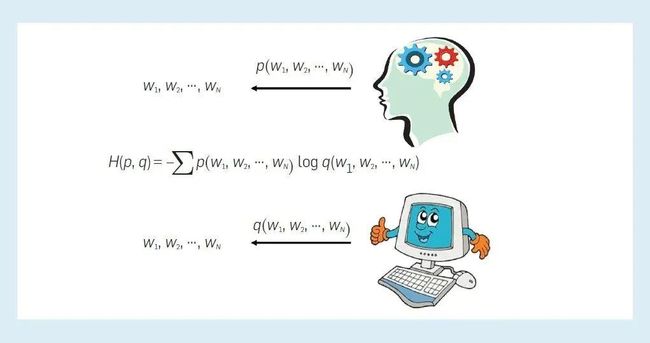
真正具有理解能力的模型,可以掌握数据特征和期望行为之间的因果关系。而大型语言模型的能力,究竟是因为在足够多的数据和模型支持下,使其具备了同人类研究者一样,可以从观测数据中来学习因果关系的能力;还是利用数据中固有的“虚假相关性”或“捷径特性”,推测出了类似真实的潜在因果模型?
关于 LLMs 是否真的足够智能,一直有众多的讨论,或许当我们将 LLMs 放入它的工具中进行使用时,可以更加清晰地认识这一点。
04
LLMs 的应用能力
LLMs 作为拥有庞大模型的大型语言,其最主要的能力就是生成。
借助 LLMs 的技术底座,我们就可以实现将它和其它模型融合,生成语言、图画、或者音乐等多种类型的内容;因此,我们认为,只要拥有足够的训练,它就可以快速又准确的生成用户所需要的各种类型的内容。
文本生成
LLMs 的最基础、也是被最广泛应用的能力就是文本生成,即根据给定的输入(通常是一段文本)生成新的文本。
LLMs 通过预先训练在大量文本数据上,学习了如何生成自然语言。因此,LLMs 可以生成各种各样的文本,包括新闻报道、小说、诗歌、聊天对话、续写等。
以 GPT-3 为例,无论你输入任何续写指令,它都可以快速生成一段长作文;基于此,你可以借助它来生成各类邮件范本等;但 GPT-3 也有着自己的弊端,例如,当我们输入【床前明月光】续写时,偶尔会出现一些错误的引导。
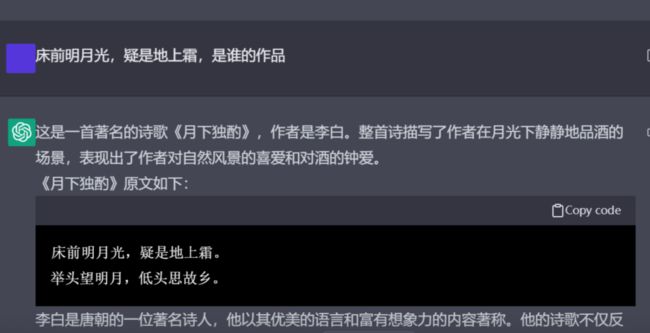
更多文本生成的能力展示,有兴趣的伙伴们可以参考我们已发表的文章《 OpenAI究竟计划抢走多少人的“饭碗”?》了解~
编码
LLMs 能够被认为是真正智能化的原因之一就是其编码能力。
通过 ChatGPT 的演示,我们发现 LLMs 可以支持这个聊天机器人在它的强大的数据训练中得到编码内容,例如当我们告诉它“创建一个 PHP 程序来扫描主机名上的开放端口”时:

编码能力的出现使得马斯克也为之惊叹,但随着大家不断对 ChatGPT 进行试验,也很快发现了它的弊端:
用户确实可以用它来直接翻译高度规则约束下语言指令、让它重新生成代码,或将函数直接翻译成其他语言等;但其能力更多在整合,即将已经发布在网路上的代码优化后二次生成,而非新建一个全新的内容。
换言之,使用 ChatGPT 的代码时,产品的安全性和独特性则会相对降低。
05
广泛使用的影响
虽然 LLMs 在安全性和准确性上还是有一定的局限,但它快速生成的能力还是收获了一大批粉丝,毕竟相比于独立构思一个全新的内容所花费的成本,远高于基于 LLMs 提供的内容进行删改优化。因此,越来越多的人加入了使用 LLMs 的大军,也使得 LLMs 产生了很多意料之外的影响。
滥用
LLMs 的快速发展无疑为创作者增加了更多灵感,也给非专业从事者带来了更多的机会;同时,也出现了越来越多过于依赖 LLMs 进行产出的情况;
更有甚者会利用 LLMs 强大的能力生产虚假信息,在不同程度上误导了用户,因此,多个互联网公司和大学已经明令禁止其员工或学生使用 GPT 系列产品。
而对于此问题,有人认为未来的语言模型可能会生成具有高说服力的文本,使得虚假信息难以被检测;也有人表示未来 LLMs 可以自行鉴别该类虚假内容。
社会价值
正向来看, LLMs 确实掀起了互联网发展的新浪潮, OpenAI 也正在向社会不同阶层的各种群体都提供 API 访问,这意味着 OpenAI 已经做好准备向外界打开联系纽带,而通过输入和训练, LLMs 也可能会根据输入内容而推算出社会潜在变化。
06
总结
随着 Naver 、Google 、Meta 等越来越多公司的入局,市面上出现了众多拥有着相似的模型构建应用,应用程序提供商缺乏显著的的产品差异。
对于此,我们认为如果终端产品的差异化源自 AI 本身,那么纵向深耕,为终端市场和终端用户提供最佳解决方案,最大程度的满足用户对于更快捷、简便的使用要求,才能在目前的市场中脱颖而出。
鼎道作为一家坚持“以人为本”的科技创新公司,我们也始终与时俱进、拥抱变化,时刻关注用户真正的需求,去繁化简,专注于研发“以人为本”的智能响应操作系统;对于如何设计和落地智能响应,是其中重要的一环, LLMs 作为其中的佼佼者,是鼎道关注并研究的对象。当然,如果你对自然语言模型有自己独到的见解或者畅想,也欢迎大家加入鼎道生态一起讨论。