国产开源优秀新一代MPP数据库StarRocks入门之旅-数仓新利器(中)
表设计
列式存储
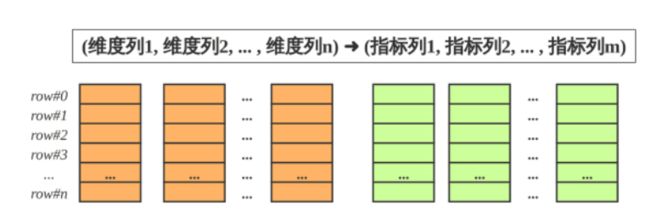
- StarRocks的表和关系型数据相同, 由行和列构成. 每行数据对应用户一条记录, 每列数据有相同数据类型. 所有数据行的列数相同, 可以动态增删列. StarRocks中, 一张表的列可以分为维度列(也成为key列)和指标列(value列), 维度列用于分组和排序, 指标列可通过聚合函数SUM, COUNT, MIN, MAX, REPLACE, HLL_UNION, BITMAP_UNION等累加起来. 因此, StarRocks的表也可以认为是多维的key到多维指标的映射。
- 在StarRocks中, 表中数据按列存储, 物理上, 一列数据会经过分块编码压缩等操作, 然后持久化于非易失设备, 但在逻辑上, 一列数据可以看成由相同类型的元素构成的数组. 一行数据的所有列在各自的列数组中保持对齐, 即拥有相同的数组下标, 该下标称之为序号或者行号. 该序号是隐式, 不需要存储的, 表中的所有行按照维度列, 做多重排序, 排序后的位置就是该行的行号。
- 查询时, 如果指定了维度列的等值条件或者范围条件, 并且这些条件中维度列可构成表维度列的前缀, 则可以利用数据的有序性, 使用range-scan快速锁定目标行. 例如: 对于表table1: (event_day, siteid, citycode, username)➜(pv); 当查询条件为event_day > 2020-09-18 and siteid = 2, 则可以使用范围查找; 如果指定条件为citycode = 4 and username in [“Andy”, “Boby”, “Christian”, “StarRocks”], 则无法使用范围查找。
稀疏索引
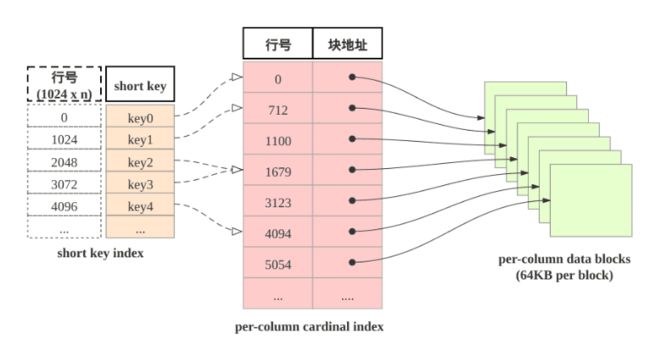
shortkey索引为稀疏索引,表中数据组织有主要由三部分构成:
- shortkey index表: 表中数据每1024行, 构成一个逻辑block. 每个逻辑block在shortkey index表中存储一项索引, 内容为表的维度列的前缀, 并且不超过36字节. shortkey index为稀疏索引, 用数据行的维度列的前缀查找索引表, 可以确定该行数据所在逻辑块的起始行号。
- Per-column data block: 表中每一列数据按64KB分块存储, 数据块作为一个单位单独编码压缩, 也作为IO单位, 整体写回设备或者读出。
- Per-column cardinal index: 表中的每列数据有各自的行号索引表, 列的数据块和行号索引项一一对应, 索引项由数据块的起始行号和数据块的位置和长度信息构成, 用数据行的行号查找行号索引表, 可以获取包含该行号的数据块所在位置, 读取目标数据块后, 可以进一步查找数据。
由此可见, 查找维度列的前缀的查找过程为: 先查找shortkey index, 获得逻辑块的起始行号, 查找维度列的行号索引, 获得目标列的数据块, 读取数据块, 然后解压解码, 从数据块中找到维度列前缀对应的数据项。
加速数据处理
- 预先聚合: StarRocks支持聚合模型, 维度列取值相同数据行可合并一行, 合并后数据行的维度列取值不变, 指标列的取值为这些数据行的聚合结果, 用户需要给指标列指定聚合函数. 通过预先聚合, 可以加速聚合操作。
- 分区分桶: 事实上StarRocks的表被划分成tablet, 每个tablet多副本冗余存储在BE上, BE和tablet的数量可以根据计算资源和数据规模而弹性伸缩. 查询时, 多台BE可并行地查找tablet快速获取数据. 此外, tablet的副本可复制和迁移, 增强了数据的可靠性, 避免了数据倾斜. 总之, 分区分桶保证了数据访问的高效性和稳定性。
- RollUp表索引: shortkey index可加速数据查找, 然后shortkey index依赖维度列排列次序. 如果使用非前缀的维度列构造查找谓词, 则无法使用shortkey index. 用户可以为数据表创建若干RollUp表索引, RollUp表索引的数据组织和存储和数据表相同, 但RollUp表拥有自身的shortkey index. 用户创建RollUp表索引时, 可选择聚合的粒度, 列的数量, 维度列的次序; 使频繁使用的查询条件能够命中相应的RollUp表索引。
- 列级别的索引技术: Bloomfilter可快速判断数据块中不含所查找值, ZoneMap通过数据范围快速过滤待查找值, Bitmap索引可快速计算出枚举类型的列满足一定条件的行。
数据模型
基本介绍
目前,StarRocks根据摄入数据和实际存储数据之间的映射关系, 其中明细表对应明细模型(Duplicate Key),聚合表对应聚合模型(Aggregate Key),更新表对应更新模型(Unique Key)和主键模型(Primary Key)。StarRocks表的维度列的取值构成数据表的排序键, StarRocks的排序键对比传统的主键具有:
- 数据表所有维度列构成排序键, 所以后文中提及的排序列, key列本质上都是维度列。
- 排序键可重复, 不必满足唯一性约束。
- 数据表的每一列, 以排序键的顺序, 聚簇存储。
- 排序键使用稀疏索引。
对于摄入(ingest)的主键重复的多行数据, 填充于(populate)数据表中时, 按照三种处理方式划分:
- 明细模型: 表中存在主键重复的数据行, 和摄入数据行一一对应, 用户可以召回所摄入的全部历史数据。
- 聚合模型: 表中不存在主键重复的数据行, 摄入的主键重复的数据行合并为一行, 这些数据行的指标列通过聚合函数合并, 用户可以召回所摄入的全部历史数据的累积结果, 但无法召回全部历史数据。
- 更新模型&主键模型: 聚合模型的特殊情形, 主键满足唯一性约束, 最近导入的数据行, 替换掉其他主键重复的数据行。相当于在聚合模型中, 为数据表的指标列指定的聚合函数为REPLACE, REPLACE函数返回一组数据中的最新数据。
需要注意:
- 建表语句, 排序列的定义必须出现在指标列定义之前。
- 排序列在建表语句中的出现次序为数据行的多重排序的次序。
- 排序键的稀疏索引(Shortkey Index)会选择排序键的若干前缀列。
明细模型
- 适用场景:StarRocks建表的默认模型是明细模型(Duplicate Key)。一般用明细模型来处理的场景有如下特点:
- 需要保留原始的数据(例如原始日志,原始操作记录等)来进行分析;
- 查询方式灵活, 不局限于预先定义的分析方式, 传统的预聚合方式难以命中;
- 数据更新不频繁。导入数据的来源一般为日志数据或者是时序数据, 以追加写为主要特点, 数据产生后就不会发生太多变化。
- 原理
- 用户可以指定数据表的排序列, 没有明确指定的情况下, 那么StarRocks会为表选择默认的几个列作为排序列。这样,在查询中,有相关排序列的过滤条件时,StarRocks能够快速地过滤数据,降低整个查询的时延。
- 注意:在向StarRocks明细模型表中导入完全相同的两行数据时,StarRocks会认为是两行数据。
- 使用
- 充分利用排序列,在建表时将经常在查询中用于过滤的列放在表的前面,这样能够提升查询速度。
- 明细模型中, 可以指定部分的维度列为排序键; 而聚合模型和更新模型中, 排序键只能是全体维度列。
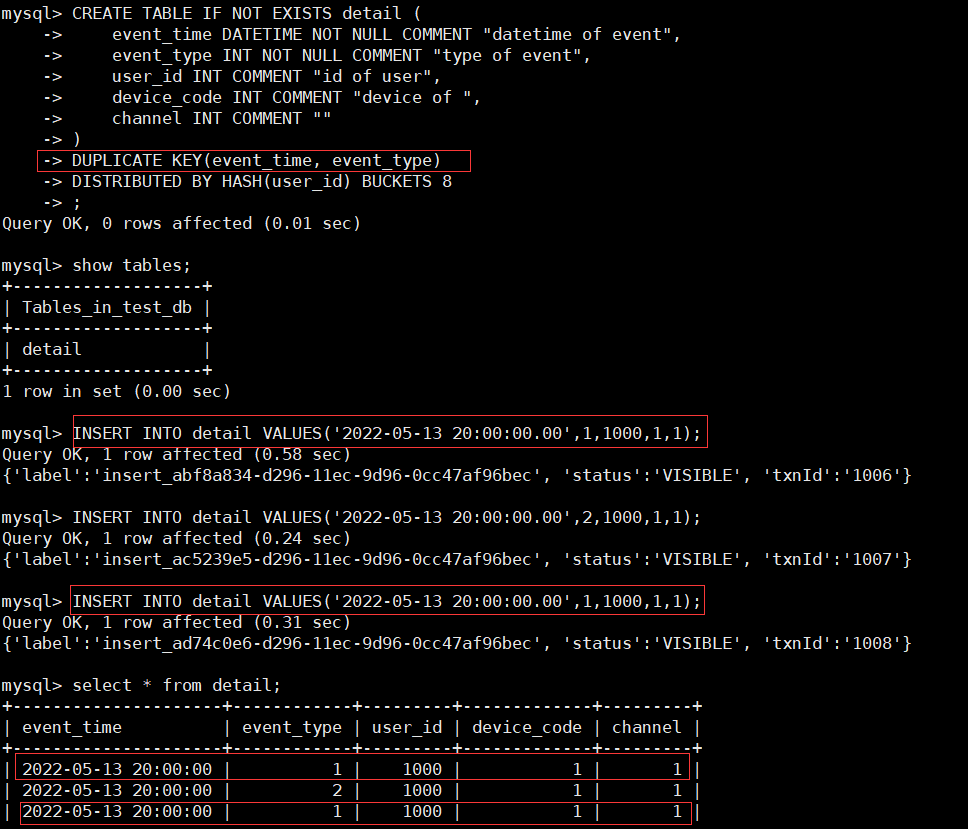
创建测试数据库和明细表,其中DUPLICATE KEY(event_time, event_type)说明采用明细模型, 并且指定了排序键, 并且排序列的定义在其他列定义之前。
CREATE DATABASE test_db;
USE test_db;
CREATE TABLE IF NOT EXISTS detail (
event_time DATETIME NOT NULL COMMENT "datetime of event",
event_type INT NOT NULL COMMENT "type of event",
user_id INT COMMENT "id of user",
device_code INT COMMENT "device of ",
channel INT COMMENT ""
)
DUPLICATE KEY(event_time, event_type)
DISTRIBUTED BY HASH(user_id) BUCKETS 8;
INSERT INTO detail VALUES('2022-05-13 20:00:00.00',1,1000,1,1);
INSERT INTO detail VALUES('2022-05-13 20:00:00.00',2,1000,1,1);
INSERT INTO detail VALUES('2022-05-13 20:00:00.00',1,1000,1,1);
聚合模型
- 适用场景:在数据分析领域,有很多需要对数据进行统计和汇总操作的场景,就需要使用聚合模型(Aggregate Key)。
- 比如:
- 分析网站或APP访问流量,统计用户的访问总时长、访问总次数;
- 广告厂商为广告主提供的广告点击总量、展示总量、消费统计等;
- 分析电商的全年的交易数据, 获得某指定季度或者月份的, 各人口分类(geographic)的爆款商品。
- 适合采用聚合模型来分析的场景具有如下特点:
- 业务方进行的查询为汇总类查询,比如sum、count、max等类型的查询;
- 不需要召回原始的明细数据;
- 老数据不会被频繁更新,只会追加新数据。
- 比如:
- 原理
- StarRocks会将指标列按照相同维度列进行聚合。当多条数据具有相同的维度时,StarRocks会把指标进行聚合。从而能够减少查询时所需要的处理的数据量,进而提升查询的效率。
- 使用
- 聚合表中数据会分批次多次导入,每次导入会形成一个版本。相同排序键的数据行聚合有三种触发方式:
- 数据导入时,数据落盘前的聚合;
- 数据落盘后,后台的多版本异步聚合;
- 数据查询时,多版本多路归并聚合。
- 数据查询时,指标列采用先聚合后过滤的方式,把没必有做指标的列存储为维度列。
- 聚合模型所支持的聚合函数列表请参考 [Create Table 语句说明](https://docs.starrocks.com/zh-cn/main/sql-reference/sql-statements/data-definition/CREATE TABLE)。
- 聚合表中数据会分批次多次导入,每次导入会形成一个版本。相同排序键的数据行聚合有三种触发方式:
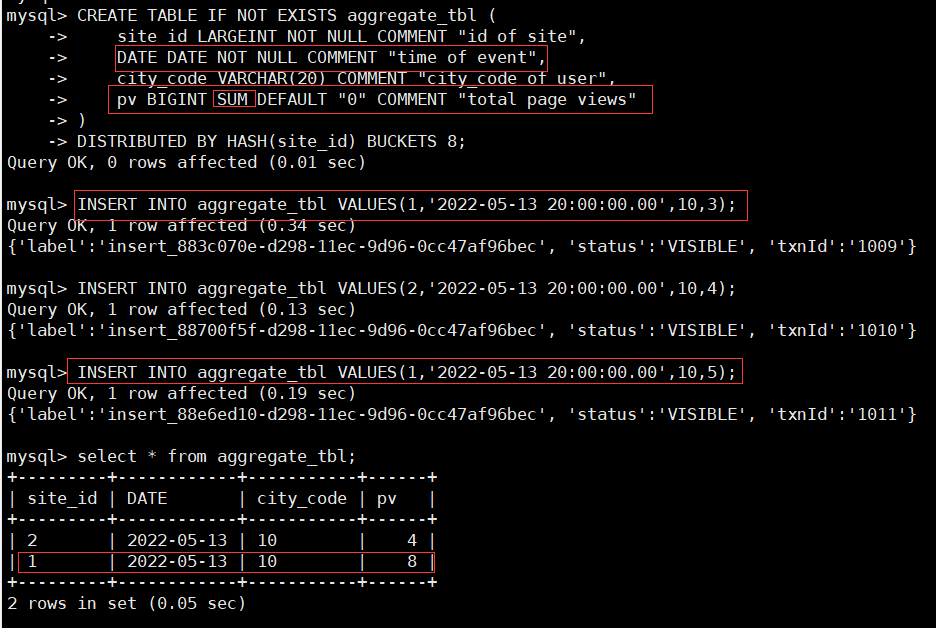
在建表时, 只要给指标列的定义指明聚合函数, 就会启用聚合模型; 用户可以使用AGGREGATE KEY显式地定义排序键。如下表site_id, date, city_code为排序键,pv为指标列, 使用聚合函数SUM。
CREATE TABLE IF NOT EXISTS aggregate_tbl (
site_id LARGEINT NOT NULL COMMENT "id of site",
date DATE NOT NULL COMMENT "time of event",
city_code VARCHAR(20) COMMENT "city_code of user",
pv BIGINT SUM DEFAULT "0" COMMENT "total page views"
)
DISTRIBUTED BY HASH(site_id) BUCKETS 8;
更新模型
- 适用场景
- 有些分析场景之下,数据会更新, StarRocks采用更新模型来满足这种需求。比如在电商场景中,定单的状态经常会发生变化,每天的订单更新量可突破上亿。在这种量级的更新场景下进行实时数据分析,如果在明细模型下通过delete+insert的方式,是无法满足频繁更新需求的; 因此, 用户需要使用更新模型来满足数据分析需求。如用户需要更加实时/频繁的更新功能,建议使用主键模型。
- 适合更新模型的场景特点
- 已经写入的数据有大量的更新需求;
- 需要进行实时数据分析。
- 原理
- 更新模型中, 排序键满足唯一性约束, 成为主键。
- StarRocks存储内部会给每一个批次导入数据分配一个版本号, 同一主键的数据可能有多个版本, 查询时最大(最新)版本的数据胜出。通过这种机制,StarRocks可以支持对于频繁更新数据的分析。
- 使用
- 导入数据时需要将所有字段补全才能够完成更新操作,即下述例子中的create_time、order_id、order_state和total_price四个字段都需必须存在。
- 对于更新模型的数据读取,需要在查询时完成多版本合并,当版本过多时会导致查询性能降低。所以在向更新模型导入数据时,应该适当降低导入频率,从而提升查询性能。建议在设计导入频率时以满足业务对实时性的要求为准。如果业务对实时性的要求是分钟级别,那么每分钟导入一次更新数据即可,不需要秒级导入。
- 在查询时,对于value字段的过滤通常在多版本合并之后。将经常过滤字段且不会被修改的字段放在主键上, 能够在合并之前就将数据过滤掉,从而提升查询性能。
- 因为合并过程需要将所有主键字段进行比较,所以应该避免放置过多的主键字段,以免降低查询性能。如果某个字段只是偶尔会作为查询中的过滤条件存在,不需要放在主键中。
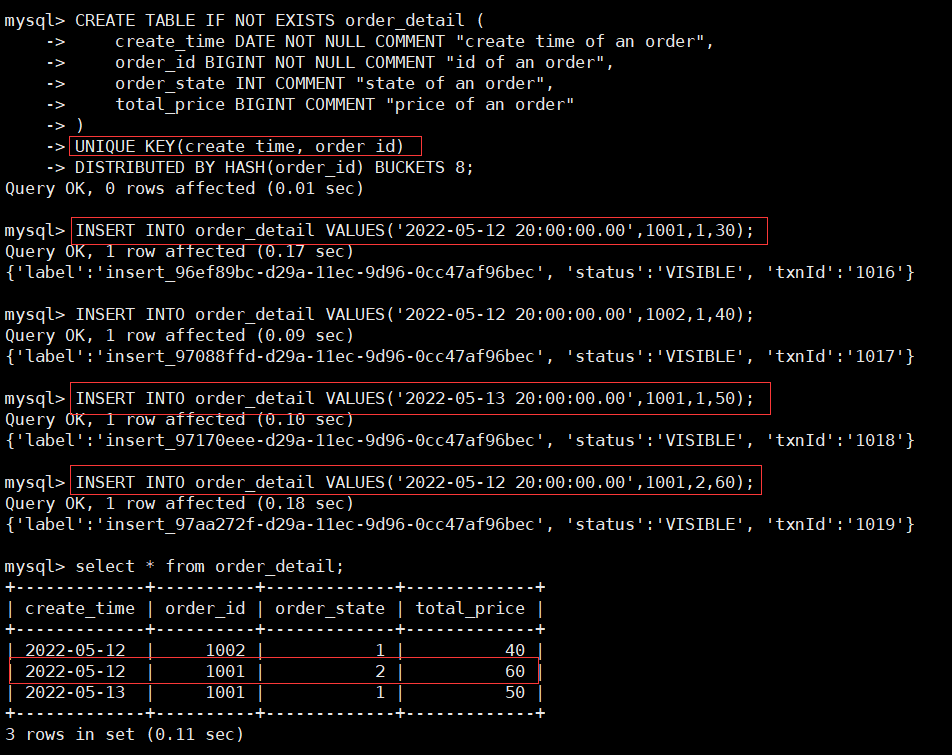
在电商订单分析场景中,经常根据订单状态进行的统计分析。因为订单状态经常改变,而create_time和order_id不会改变,并且经常会在查询中作为过滤条件。所以可以将 create_time和order_id 两个列作为这个表的主键(即,在建表时用UNIQUE KEY关键字定义),其中create_time, order_id为排序列, 其定义在其他列定义之前出现;order_state和total_price为指标列, 其聚合类型为REPLACE。这样既能够满足订单状态的更新需求,又能够在查询中进行快速过滤。
CREATE TABLE IF NOT EXISTS order_detail (
create_time DATE NOT NULL COMMENT "create time of an order",
order_id BIGINT NOT NULL COMMENT "id of an order",
order_state INT COMMENT "state of an order",
total_price BIGINT COMMENT "price of an order"
)
UNIQUE KEY(create_time, order_id)
DISTRIBUTED BY HASH(order_id) BUCKETS 8;
INSERT INTO order_detail VALUES('2022-05-12 20:00:00.00',1001,1,30);
INSERT INTO order_detail VALUES('2022-05-12 20:00:00.00',1002,1,40);
INSERT INTO order_detail VALUES('2022-05-13 20:00:00.00',1001,1,50);
INSERT INTO order_detail VALUES('2022-05-12 20:00:00.00',1001,2,60);
主键模型
- 适用场景:主键模型的表要求有唯一的主键,支持对表中的行按主键进行更新和删除操作。相较更新模型,主键模型可以更好地支持实时和频繁更新等场景。
- 实时对接 TP 数据至 StarRocks
- 利用部分列更新轻松实现多流 JOIN。
- 由于存储引擎会为主键建立索引,而在导入数据时会把主键索引加载在内存中,所以主键模型对内存的要求比较高,还不适合主键特别多的场景目前primary主键存储在内存中,为防止滥用造成内存占满,限制主键字段长度全部加起来编码后不能超过127字节
- 数据有冷热特征,即最近几天的热数据才经常被修改,老的冷数据很少被修改。
- 大宽表(数百到数千列);主键只占整个数据的很小一部分,其内存开销比较低。比如用户状态/画像表,虽然列非常多,但总的用户数不大(千万-亿级别),主键索引内存占用相对可控。
- 原理:主键模型是由StarRocks全新设计开发的存储引擎支持的,其元数据组织、读取、写入方式和原有的表模型完全不同。
- 主键模型通过主键约束,保证同一个主键下仅存在一条记录,这样就完全避免了Merge操作。具体实现步骤:
- StarRocks收到对某记录的更新操作时,会通过主键索引找到该条记录的位置,并对其标记为删除,再插入一条新的记录。相当于把Update改写为Delete+Insert。
- StarRocks收到对某记录的删除操作时,会通过主键索引找到该条记录的位置,对其标记为删除。这样在查询时不影响谓词下推和索引的使用, 保证了查询的高效执行。
- 可见,相比更新模型,主键模型通过牺牲微小的写入性能和内存占用,极大提升了查询性能。
- 主键模型通过主键约束,保证同一个主键下仅存在一条记录,这样就完全避免了Merge操作。具体实现步骤:
在建表时通过PRIMARY KEY指定最前的若干列为主键,即可启用主键模型,与更新模型结果一致,当user_id发生冲突时会覆盖。
create table users (
user_id bigint NOT NULL,
name string NOT NULL,
email string NULL,
address string NULL,
age tinyint NULL
) PRIMARY KEY (user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 4
PROPERTIES("replication_num" = "3");
排序键
- 原理:StarRocks中为加速查询,在内部组织并存储数据时,会把表中数据按照指定的列进行排序,这部分用于排序的列(可以是一个或多个列),可以称之为Sort Key。明细模型中Sort Key就是指定的用于排序的列(即 DUPLICATE KEY 指定的列),聚合模型中Sort Key列就是用于聚合的列(即 AGGREGATE KEY 指定的列),更新模型中Sort Key就是指定的满足唯一性约束的列(即 UNIQUE KEY 指定的列)。
- 注意
- 排序列的定义必须出现在建表语句中其他列的定义之前。
- 排序列的顺序是由create table语句中的列顺序决定的。
- 排序键类似mysql最左前缀原则,满足则可以加速查询。
- 当Sort Key列数非常多时,会占用大量内存, 为了避免这种情况, 对shortkey index索引项做了限制。如shortkey 列数不超过3、字节数不超过36字节。
物化视图
- 使用场景:在实际的业务场景中,通常存在两种场景并存的分析需求:对固定维度的聚合分析 和 对原始明细数据任意维度的分析。
- 限制
- 分区列必须存在于创建物化视图的group by聚合列中
- 目前只支持对单表进行构建物化视图,不支持多表JOIN
- 聚合类型表(Aggregation),不支持对key列执行聚合算子操作,仅支持对value列进行聚合,且聚合算子类型不能改变。
- 物化视图中至少包含一个KEY列
- 不支持表达式计算
- 不支持指定物化视图查询
- 不支持 Order By
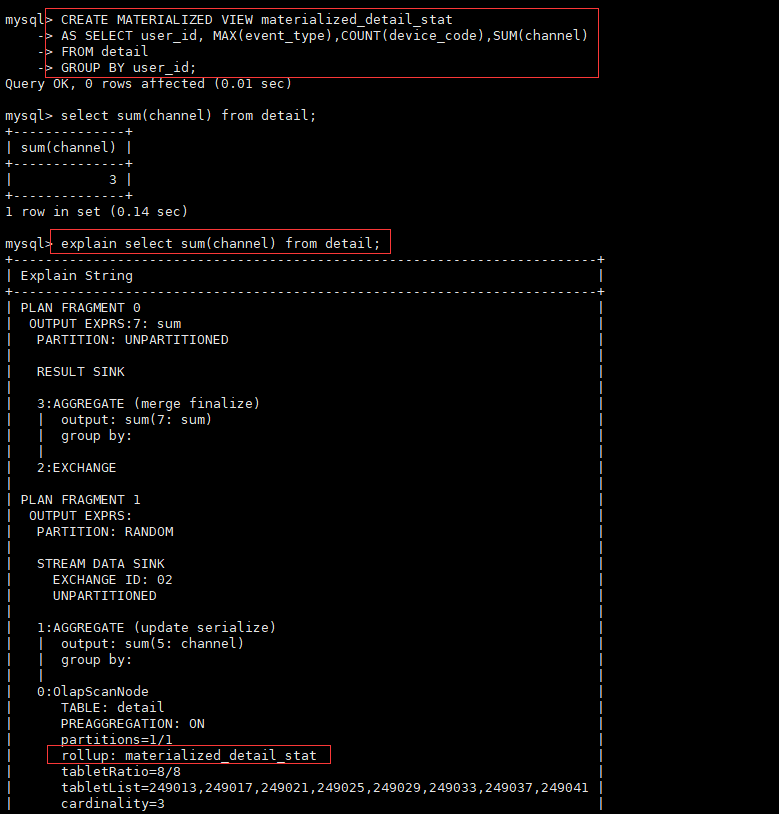
CREATE MATERIALIZED VIEW materialized_detail_stat
AS SELECT user_id, MAX(event_type),COUNT(device_code),SUM(channel)
FROM detail
GROUP BY user_id;
explain select sum(channel) from detail;
Bitmap 索引
StarRocks 支持基于Bitmap索引,对于有Filter的查询有明显的加速效果。
- 原理
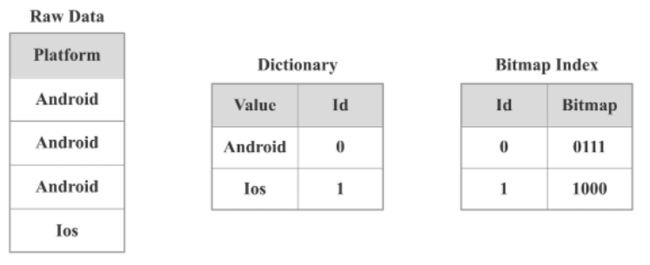
- Bitmap是元素为bit的, 取值为0、1两种情形的, 可对某一位bit进行置位(set)和清零(clear)操作的数组。Bitmap的使用场景有:
- 用一个long型表示32位学生的性别,0表示女生,1表示男生。
- 用Bitmap表示一组数据中是否存在null值,0表示元素不为null,1表示为null。
- 一组数据的取值为(Q1, Q2, Q3, Q4),表示季度,用Bitmap表示这组数据中取值为Q4的元素,1表示取值为Q4的元素, 0表示其他取值的元素。
- Bitmap只能表示取值为两种情形的列数组, 当列的取值为多种取值情形枚举类型时, 例如季度(Q1, Q2, Q3, Q4), 系统平台(Linux, Windows, FreeBSD, MacOS), 则无法用一个Bitmap编码; 此时可以为每个取值各自建立一个Bitmap的来表示这组数据; 同时为实际枚举取值建立词典
- Bitmap是元素为bit的, 取值为0、1两种情形的, 可对某一位bit进行置位(set)和清零(clear)操作的数组。Bitmap的使用场景有:
- 适用场景
- 非前缀过滤。
- 多列过滤Filter。
- 使用注意
- 对于明细模型,所有列都可以建Bitmap 索引;对于聚合模型,只有Key列可以建Bitmap 索引。
- Bitmap索引, 应该在取值为枚举型, 取值大量重复, 较低基数, 并且用作等值条件查询或者可转化为等值条件查询的列上创建。
- 不支持对Float、Double、Decimal 类型的列建Bitmap 索引。
- 如果要查看某个查询是否命中了Bitmap索引,可以通过查询的Profile信息查看。
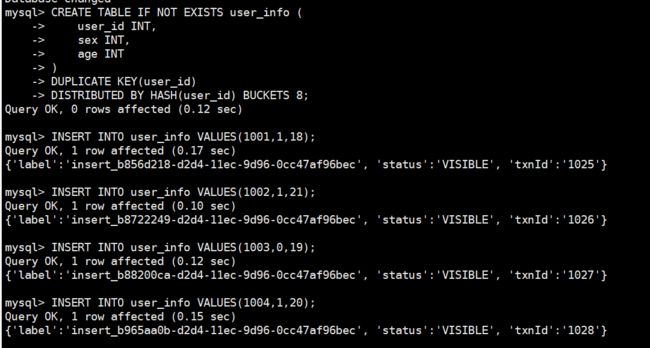
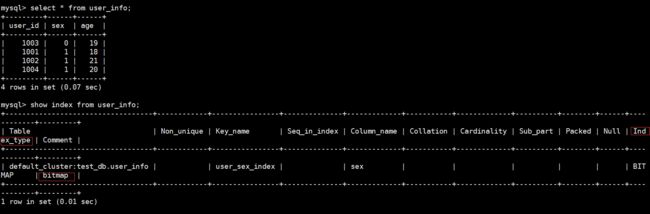
CREATE TABLE IF NOT EXISTS user_info (
user_id INT,
sex INT,
age INT
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 8;
INSERT INTO user_info VALUES(1001,1,18);
INSERT INTO user_info VALUES(1002,1,21);
INSERT INTO user_info VALUES(1003,0,19);
INSERT INTO user_info VALUES(1004,1,20);
SHOW INDEX FROM user_info;
Bloomfilter 索引
- 原理
- Bloom Filter(布隆过滤器)是用于判断某个元素是否在一个集合中的数据结构,优点是空间效率和时间效率都比较高,缺点是有一定的误判率。
- StarRocks建表时, 可通过PROPERTIES{“bloom_filter_columns”=“c1,c2,c3”}指定需要建BloomFilter索引的列,查询时, BloomFilter可快速判断某个列中是否存在某个值。如果Bloom Filter判定该列中不存在指定的值,就不需要读取数据文件;如果是全1情形,此时需要读取数据块确认目标值是否存在。另外,Bloom Filter索引无法确定具体是哪一行数据具有该指定的值。
- 适用场景
- 首先BloomFilter也适用于非前缀过滤。
- 查询会根据该列高频过滤,而且查询条件大多是in和=。
- 不同于Bitmap, BloomFilter适用于高基数列。
- 使用注意
- 不支持对Tinyint、Float、Double、Decimal 类型的列建Bloom Filter索引。
- Bloom Filter索引只对in和=过滤查询有加速效果。
- 如果要查看某个查询是否命中了Bloom Filter索引,可以通过查询的Profile信息查看(TODO:加上查看Profile的链接)。
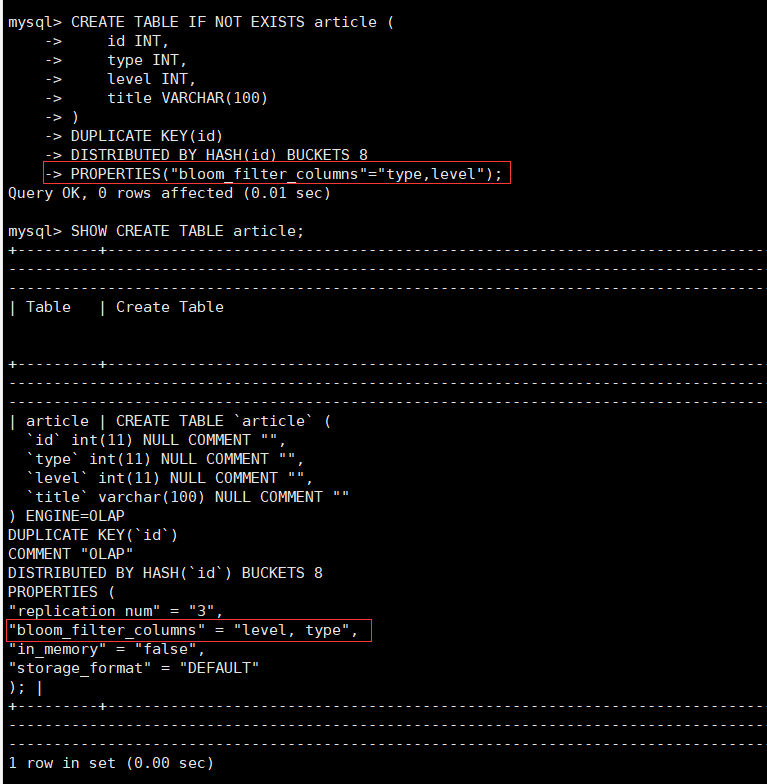
CREATE TABLE IF NOT EXISTS article (
id INT,
type INT,
level INT,
title VARCHAR(100)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES("bloom_filter_columns"="type,level");
SHOW CREATE TABLE article;
ALTER TABLE article SET ("bloom_filter_columns" = "");
**本人博客网站 **IT小神 www.itxiaoshen.com