《数据挖掘——概念与技术》笔记
主要是对《数据挖掘——概念与技术》这本书中的知识点做部分总结,内容都是书上的。
目录
第2章 认识数据
2.1 数据对象与属性类型
2.2 数据的基本统计描述
2.4 度量数据的相似性与相异性
第3章 数据预处理
3.2 数据清理
3.3 数据集成
3.4 数据归约
3.5 数据变换与数据离散化
第4章 数据仓库与联机分析处理
4.1 数据仓库:基本概念
4.2 数据仓库建模:数据立方体与 OLAP
4.3 数据仓库的设计
4.4 数据仓库的实现
4.5 数据泛化:面向属性的归纳
第5章 数据立方体技术
5.1 数据立方体计算:基本概念
5.2 数据立方体计算方法
补充
粒度
2章 认识数据
2.1 数据对象与属性类型
一个数据对象代表一个实体,如在大学的数据库中,对象可以是学生、教授和课程。数据对象用属性描述,属性是一个数据字段,表示数据对象的一个特征,如学生的年龄(age)这样的。属性可以分为以下五种类型。
标称属性:与名称相关,值是一些事物的名称,如hair_color,值是黑色、棕色、红色等等;二元属性:是一种标称属性,只有两种状态,0或1。二元属性可以是对称的(同等价值,相同权重),也可以是不对称的。序数属性:值之间的排序是有意义的,如小、中、大,但相邻值之间的差是未知的。数值属性:是定量的可度量的量,用整数或实数值表示,大多属性都是标称属性或数值属性。离散属性和连续属性:离散指属性有有限或无限个可数的值,不是离散的属性就是连续属性,可与数值属性互换使用。
2.2 数据的基本统计描述
这部分是比较基础的概率与统计的知识。
中心趋势度量:均值、中位数和众数。数据散布度量:极差、四分位数和四分位极差;五数概括,盒图和离群点;方差和标准差。数据的基本统计描述的图形显示:分位数图、分位数-分位数图、直方图、散点图与数据相关。
2.4 度量数据的相似性与相异性
簇是数据对象的集合,是的同一个簇中的对象互相相似,而与其他簇中的对象相异。相似性和相异性都称近邻性。
数据矩阵:(i, j) 表示对象 i 的第 j 个属性的值。相异性矩阵:(i, j) 表示对象i和对象j之间的相异性。相异性的度量,包含了以下几个方面的内容(不同类型的属性,度量方式不同):
标称属性的邻近性度量:![]() ,p是标称属性总数,m是对象 i 和对象 j 相同的属性数;二元属性的邻近性度量:
,p是标称属性总数,m是对象 i 和对象 j 相同的属性数;二元属性的邻近性度量:![]() ,其中q是对象 i 和对象 j 状态都为 1 的属性数,其他可类推。非对称的二元属性相异性为
,其中q是对象 i 和对象 j 状态都为 1 的属性数,其他可类推。非对称的二元属性相异性为![]() ;数值属性的相异性:闵可夫斯基距离
;数值属性的相异性:闵可夫斯基距离![]() ,h 为 2 时就是直线距离,为 1 时就是曼哈顿距离;
,h 为 2 时就是直线距离,为 1 时就是曼哈顿距离;
第3章 数据预处理
现实世界的数据一般是脏的、不完整的和不一致的,数据预处理技术可以改进数据的质量。数据预处理的主要步骤包括,数据清理、数据集成、数据规约和数据变换。
3.2 数据清理
数据清理例程试图填充缺失的值、光滑噪声并识别离群点、纠正数据中的不一致。
3.2.1 缺失值
填充缺失值的方法:使用一个全局变量填充;使用属性的中心度量(均值或中位数)填充;使用最可能的值填充(用回归、使用贝叶斯形式化方法的基于推理的工具、决策树归纳???)。
3.2.2 噪声数据
噪声是被测量的变量的随机误差或方差,减小噪声即光滑数据。
光滑数据的方法:分箱:将所有数据排序后分到若干个大小都为 k 的箱中,用箱的均值光滑,则箱中所有的数被替换为该箱的均值。同理也可用中位数。用箱的边界来光滑,则箱中的数被替换为离它更近的那一个边界。回归:用一个函数拟合数据来光滑数据???离群点分析:可以通过聚类来检测离群点???
3.2.3 数据处理作为一个过程
第一步偏差检测:首先用到元数据(数据的数据,如类型、定义域、值域等)和数据的基本统计描述,发现噪声和离群点等;注意不一致和字段过载问题???;使用唯一性规则、连续性规则、空值规则考察数据;商用的数据清洗工具、数据审计工具???
第二步数据变换(纠正偏差):商用的数据迁移工具、ETL(Extraction/Transformation/Loading)工具???
3.3 数据集成
数据集成指合并来自多个数据存储(数据库、数据立方体或一般文件等)的数据,好的集成有助于减少结果数据集的冗余和不一致。
3.3.1 实体识别问题
实体识别问题:来自多个信息源的,现实世界中等价的实体,如何匹配?例如,如何确定一个数据库中的 customer_id 与另一个数据库中的 cust_number 是相同的属性;以及一个系统中的 discount 与另一个系统中的 discount 是对不同的对象打折。
3.3.2 冗余和相关分析
一个属性(如年收入)能由另一个或另一组属性导出,则这个属性可能是冗余的。属性或维命名的不一致也可能导致结果数据集中的冗余。有些冗余可以由相关分析检测到,标称属性使用卡方检验,数值属性用相关系数和协方差检验。
1. 标称数据的![]() (卡方)相关检验:假设两属性 A 有 c 个不同值,B 有 r 个不同值,
(卡方)相关检验:假设两属性 A 有 c 个不同值,B 有 r 个不同值,![]() 表示属性分别取值
表示属性分别取值  、
、 的联合事件。则
的联合事件。则 ![]() ,其中
,其中 ![]() 是联合事件
是联合事件 ![]() 的实际个数,
的实际个数,![]() 。
。
2. 数值数据的相关系数:![]() ,这个值越大相关性越强。
,这个值越大相关性越强。
3. 数值数据的协方差:![]() ,对于趋向于一起变化的 A 和 B,其协方差为正。
,对于趋向于一起变化的 A 和 B,其协方差为正。
3.3.4 数据值冲突
对于现实世界的同一实体,来自不同数据源的属性值可能不同,这可能是因为表示、尺度或编码的不同。例如,不同学校交换信息时,一所大学用 A ~ F 打分,另一所大学用 1 ~ 10 打分。属性也可能在不同的抽象层,如 total_sale 可能涉及一个分店,而另一个数据库中涉及整个公司。
3.4 数据归约
数据归约技术用来得到数据集的归约表示,它小的多,但接近于保持原始数据完整性。
3.4.1 数据归约策略
数据归约策略包括维归约、数量归约和数据压缩。维归约:减少随机变量或属性的个数。可使用小波变换、主成分分析、属性子集选择等技术;数量归约:用替代的、较小的数据表示形式替换原数据。可使用直方图、聚类、抽样、数据立方体聚集等技术。数据压缩:维归约和数量归约都可以视为某种形式的数据压缩。压缩分为无损和有损的。
3.4.2 数据归约技术
离散小波变换:将每个元组看做一个 n 维数据向量,通过一定的步骤迭代得到小波系数???还需要用到信号处理技术;主成分分析:搜索 k 个最能代表数据的 n 维正交向量,其中 k <= n 。PCA 通过创建一个替换的、较小的变量集 “组合” 属性的基本要素,使原数据可以投影到该较小的集合中。这部分需了解更多内容。属性子集选择:找出最小属性自己,且接近原分布,使用贪心算法,每次做局部最优选择。在初始属性集中用逐步向前选择、逐步向后删除或决策树归纳???
3.5 数据变换与数据离散化
3.5.1 数据变换策略
数据变换中,数据被变换或统一成适合于挖掘的形式。数据变换策略包括以下几种。
光滑:去掉数据中的噪声(数据清理);属性构造:构造新的属性并添加到数据集中(数据归约);聚集:对数据进行汇总或聚集(数据归约);规范化:把属性数据按比例缩放,使之落入一个特定的区间;离散化:数值属性(年龄)的原始值用区间标签(1 ~ 10,11 ~ 20)或概念标签(老、中、青)替换。由标称数据产生概念分层:标称属性(street)可以泛化到较高的概念层(city),可以自动定义产生标称属性的概念分层。
3.5.2 通过规范化变换数据
最大最小规范化:![]() 。
。
z分数规范化:![]() ,其中
,其中 ![]() 和
和 ![]() 是属性 A 的均值和标准差。
是属性 A 的均值和标准差。
3.5.3 离散化
通过分箱离散化;通过直方图分析来离散化;通过聚类、决策树和相关分析来离散化???
3.5.4 标称数据的概念分层产生
标称数据的数据变换中,一个重点是标称属性的概念分层产生。有四种产生的方法:由用户或专家在模式级显式说明属性的部分序;通过显式数据分组说明分层结构的一部分?;说明属性集但不说明他们的偏序(组合数学概念);只说明部分属性集???。
第4章 数据仓库与联机分析处理
4.1 数据仓库:基本概念
4.1.1 什么是数据仓库
数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理者的决策过程。面向主题的:数据仓库通常排除对于决策无用的数据,提供特定主题的简明试图;集成的:构造数据仓库是将多个异构数据源,如关系数据库、一般文件和联机事务处理记录集成在一起。时变的:数据存储提供过去的信息,显式或隐式包含时间元素。非易失的:数据仓库总是物理地分离存放数据,与操作环境下的应用分离,不需要事务处理、恢复和并发控制机制。通常只需要两种数据访问操作:数据的初始化装入和数据访问
4.1.2 数据库系统与数据仓库的区别
数据库系统的主要任务是执行联机事务和查询处理,称作联机事务处理(OLTP)系统。数据仓库系统在数据分析和决策方面维用户或知识工人提供服务,称作联机分析处理(OLAP)系统。
在数据内容上,OLTP 系统管理当前数据,OLAP 系统管理大量历史数据,提供汇总和聚集机制;在数据库设计上,OLTP 系统采用实体-联系(E-R)数据模型,OLAP 系统通常采用星形或雪花模型和面向主题的数据库设计??;其他方面 OLTP 和 OLAP 也有区别。
4.1.4 数据仓库:一种多层体系结构
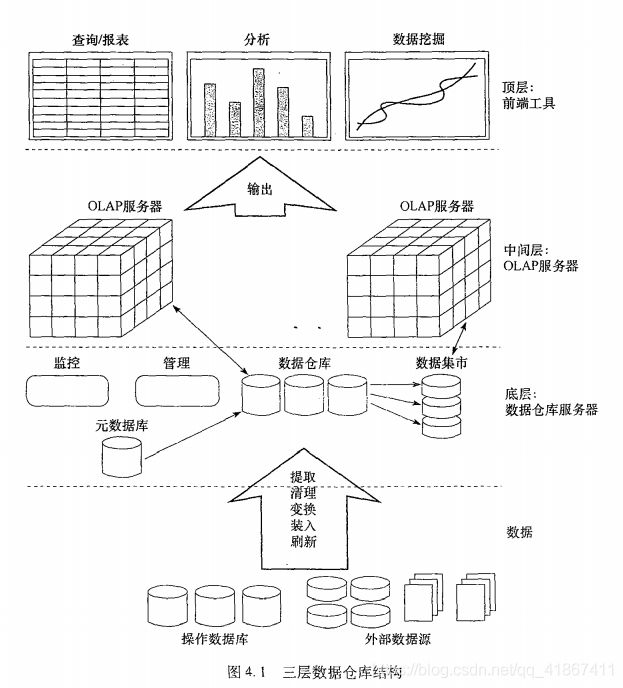
4.1.5 数据仓库模型:企业仓库、数据集市和虚拟仓库
企业仓库搜集了关于主题的所有信息,跨越整个企业。它包含细节数据和汇总数据,数据规模大,需要的硬件平台也大;数据集市包含企业范围数据的一个子集,对于特定的用户群是有用的;虚拟仓库是操作数据库上视图的集合。
4.1.6 数据提取、变换和装入
数据变换是将数据由遗产或宿主格式转换成数据仓库格式。数据装入包括排序、汇总、合并、计算视图、检查完整性,并建立索引和划分。
这部分这本书没有详细介绍,需要查阅专门讲数据仓库的书籍。
4.1.7 元数据库
元数据是数据的数据,在数据仓库中,元数据是定义仓库对象的数据。对于给定的数据仓库的数据名和定义,创建元数据。其他元数据包括对提取数据添加的时间标签、提取数据的源、被数据清理或集成处理添加的缺失字段等。
元数据库应当包括:数据仓库结构的描述、操作元数据、用于汇总的算法、由操作环境到数据仓库的映射、关于系统性能的数据、商务元数据。以上几点各自包含的内容有很多也很重要。
4.2 数据仓库建模:数据立方体与 OLAP
数据仓库和 OLAP 工具基于多维数据模型,这种模型将数据看作数据立方体 形式。
4.2.1 数据立方体:一种多维数据模型
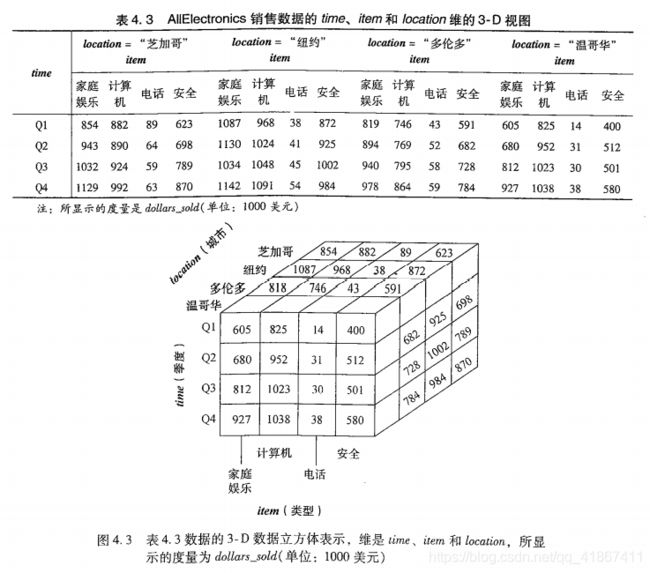
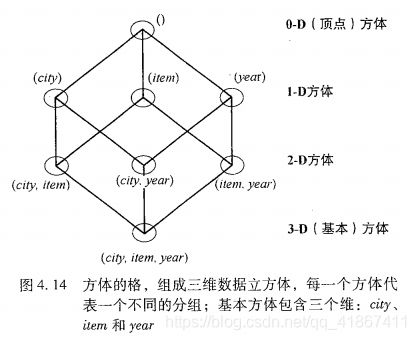
此外,我们可以把任意 n 维数据立方体显示成(n - 1)维数据立方体的序列。
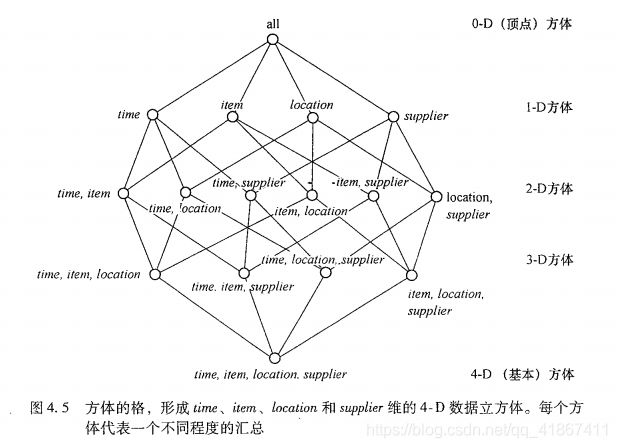
维time、item、location 和 supplier 的数据立方体的方体格,有点像组合数学里偏序关系那里。
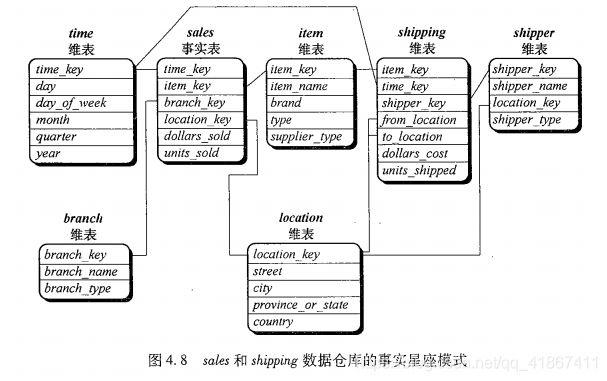
4.2.2 多维数据模型的模式:星形、雪花形和事实星座
星形模式:一个大的中心表(事实表),它包含大量数据且不含冗余 + 一组小的附属表(维表),每个维一个。
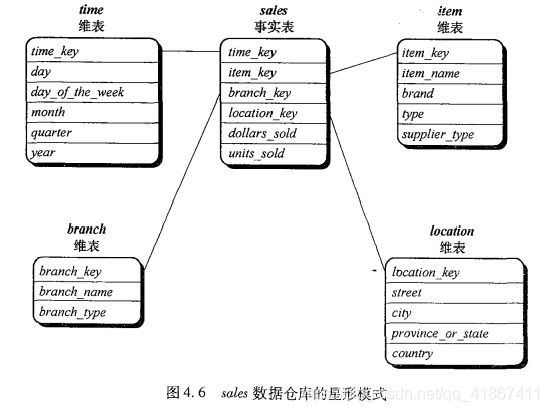
雪花模式:与星形模式的主要差别是维表,雪花模式的为表可能是规范化形式,以便减少冗余???但并不如星形模式流行。
事实星座:复杂的应用可能需要多个事实表共享维表。
4.2.3 维:概念分层的作用
形成数据库模式中属性的全序或偏序的概念分层称作模式分层,许多应用共有的概念分层可以在数据挖掘系统中预先定义。概念分层允许我们在各种抽象层处理数据。

4.2.4 度量的分类和计算
数据立方体空间的多维点可以用维 - 值对的集合来定义,如< time = "Q1", location = "温哥华", item = "计算机" >。数据立方体的度量是一个数值函数,该函数可以对数据立方体空间的每个点求值。
度量根据其所用的聚集函数可以分成三类:分布的、代数的和整体的。分布的:聚集函数用于多个部分计算结果之和与用于整体的结果相同,如 sum()、count()、min()、max() 等;代数的:分布聚集函数的代数式???如 avg = sum() / count()、min_N()、max_N() 等;整体的:不存在这样一个分布聚集函数的代数式能够计算的,如 median()、mode()、rank() 等。
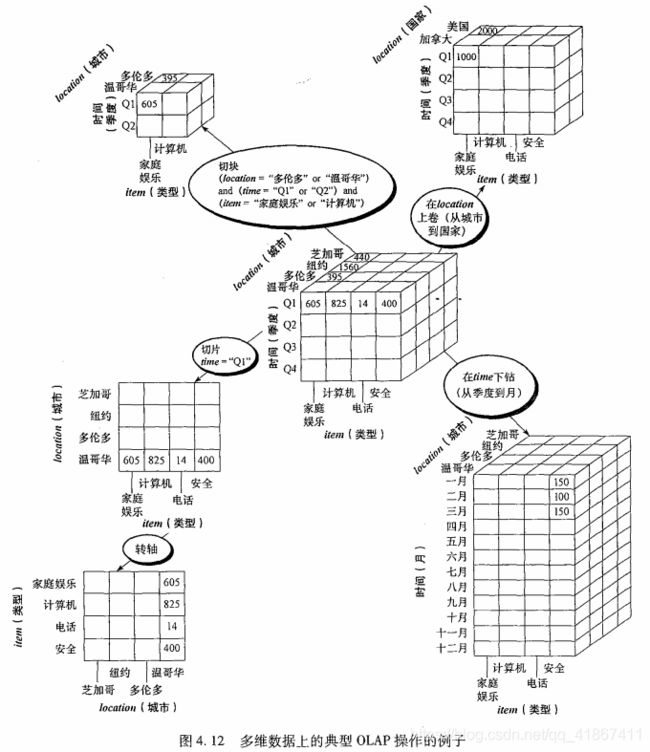
4.2.5 典型的 OLAP 操作
上卷、下钻、切片和切块、转轴。
4.3 数据仓库的设计
4.3.1 数据仓库的设计过程
从软件工程的角度看,数据仓库的设计和构造包括:规划、需求研究、问题分析、仓库设计、数据集成和测试、最后部署数据仓库。大型软件系统可以用两种方法开发:瀑布式方法和螺旋式方法。
一般而言,数据仓库的设计过程包括:(1)选取待建模的商务处理。(2)选取商务处理的粒度。对于处理,该粒度是基本的,在事实表中是数据的原子级。(3)选取用于每个事实表记录的维。(4)选取将安放?在每个事实表记录中的度量。
这本书中数据仓库设计内容讲的过简略。
4.4 数据仓库的实现
数据仓库包含海量数据。OLAP 服务器要在数秒内回答决策支持查询。因此,实现中至关重要的是,数据仓库系统要支持高效的数据立方体计算技术、存取方法和查询处理技术。
4.4.1 数据立方体的有效计算:概述
立方体计算的一种方法是扩充SQL, 使之包含 compute cube 操作。compute cube 操作在操作指定的维的所有子集上计算聚集。


预计算:联机分析处理可能需要访问不同的方体,提前计算所有的或者至少一部分方体。维灾难:如果数据立方体中所有的方体都预先计算,所需的存储空间可能爆炸,特别是当立方体包含许多维时。

部分物化:有选择地计算整个可能的方体集中一个适当地子集。
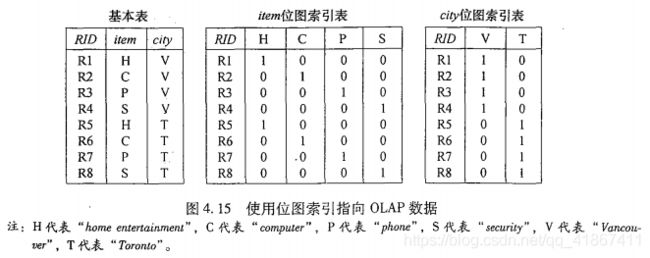
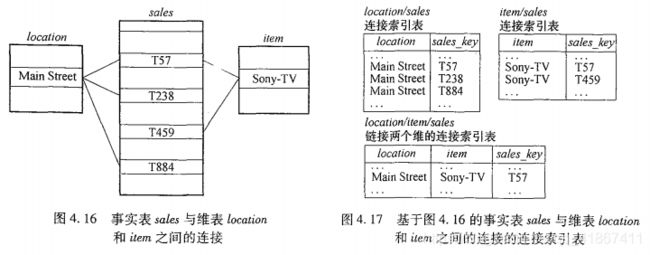
4.2.2 索引 OLAP 数据:位图索引和连接索引
位图索引:是一个 n * m 的 0 - 1 表,对于基数较小的值域特别有用,因为比较、连接和聚集操作都简化成位算数运算。
连接索引:登录来自关系数据库的两个关系的可连接行。
4.4.3 OLAP 查询的有效处理
物化方体和构造 OLAP 索引结构的目的是加快数据立方体查询处理的速度。给定物化的视图,查询处理应按步骤:(1)确定哪些操作应当在可利用的方体上执行。(2)确定相关操作应当使用哪些物化的方体。

4.5 数据泛化:面向属性的归纳
数据立方体可以看作一种多维数据泛化。数据泛化通过把相对低层的用较高层概念替换来汇总数据,或通过减少维数,在少维数概念空间汇总数据。
4.5.1 数据特征的面向属性的归纳
基本思想:通过考察任务相关的数据中每个属性的不同值的个数进行泛化。手段:属性删除或属性泛化(类似于上卷)。

这个数据仓库查询的例子看着和SQL挺像,是专门的语言吗?
属性删除:对于没有泛化操作符???的有大量不同值的属性,可以直接删了。属性泛化:属性有大量不同值,属性上存在泛化操作符???,则选个规则泛化。其中控制泛化过程的方法有:属性泛化阈值控制(不同值个数大于阈值,进行属性删除或泛化)或广义关系阈值控制(广义关系中???不同元组的个数超过该阈值则泛化)。
第5章 数据立方体技术
5.1 数据立方体计算:基本概念
5.1.1 立方体物化:完全立方体、冰山立方体、闭立方体和立方体外壳
基本单元和聚集单元概念

祖先和后代单元概念

冰山立方体:稀疏立方体中可以只物化其中度量值???大于某个最小阈值的一部分,这部分物化的立方体称为冰山立方体,这种最小阈值称为最小支持度。形式上来看好像就是一个having子句。

5.1.2 数据立方体计算的一般策略
优化技术1:排序、散列和分组;优化技术2:同时做聚集和缓存中间结果;优化技术3:当存在多个子女方体时,由最小的子女方体聚集。这里要正确理解什么是最小的子女方体;优化技术4:使用先验剪枝方法计算冰山立方体。先验性质:如果给定单元不满足最小支持度,则该单元的后代也不满足最小支持度。
5.2 数据立方体计算方法
5.2.1 完全立方体计算的多路数组聚集
如图,数组立方体计算的最有效次序是块次序 1 ~ 64,这其中为什么是最重要的。当维的基数乘积适中并且数据不是太稀疏是,MultiWay(多路数据聚集)是最有效的。

5.2.2 BUC :从顶点方体向下计算冰山立方体
这个方法的重点是,结合下面的算法,理解什么叫从顶点向下计算、计算的过程是一个递归且 DFS 的过程(像全排列一样)、计算中用先验性质来剪枝。

5.2.3 Star-Cubing:使用动态星树结构计算冰山立方体
这里的星树结构不太能理解,主要对多维数据立方体结构没理解到位。
5.2.4 为快速高维 OLAP 预计算壳片段
计算冰山立方体仍然有一些问题(开销仍高、合适阈值、不能增量更新),一个可能的解是计算一个很薄的立方体外壳。计算立方体外壳需要构造倒排索引,计算了外壳片段后,可用点查询??和子立方体查询??来进行 OLAP 查询。但对这里的外壳结构也不太能理解。
补充
补充内容来自机械工业社的一本叫《数据仓库》的黑皮书,但感觉里面内容比较简略。
粒度
粒度是数据仓库中数据单元的细节程度或综合程度的级别。细节程度越高,粒度级就越低。粒度问题是数据仓库设计的一个重要问题,因其影响到存放在数据仓库中数据量的大小,以及数据仓库所能回答的查询类型。粒度级越低,数据量越大,查询范围越广泛。
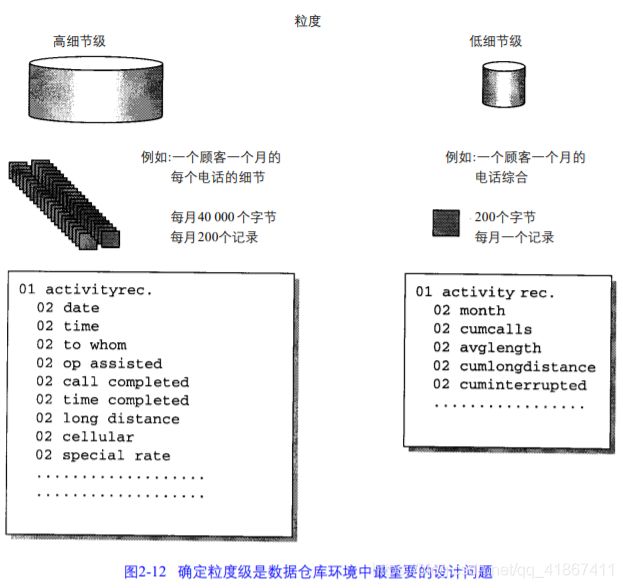
双重粒度:轻度综合数据和“真实档案”细节数据。
