当流计算邂逅数据湖:Paimon 的前生今世
序言
笔者从事流计算多年,真名叫李劲松,简写 LJS,Apache ID 也是 lzljs (泸州李劲松),而流计算简写也是 LJS,算是一种缘分吧。
一直在分布式计算与存储的领域工作,也参与了多个开源项目,希望通过笔者以下的经历,回顾流计算一步一步扩大场景的过程,并引出 Apache Paimon 的前生今世。
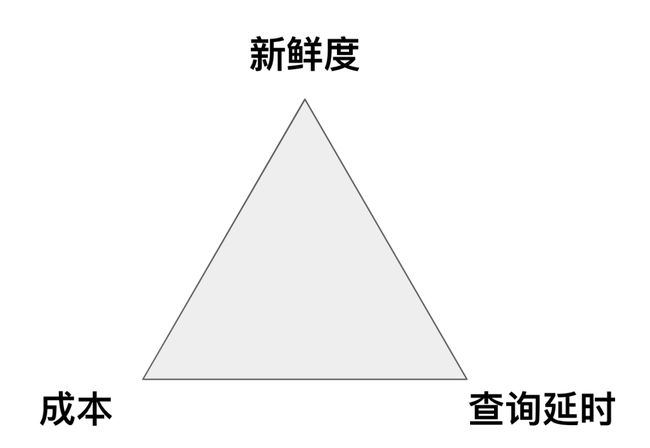
很久之前写过一篇文章引用了这个图,原图来自 Napa: Powering Scalable Data Warehousing with Robust Query Performance at Google
大数据系统都是有着不同侧重的考虑,甚至还要加上开发人员的精力,构建了一系列的权衡 (Trade-off),这个世界上目前并没有 Silver Bullet (具有极端有效性的解决方法),没有大一统的系统,每个场景有对应的解决方案。
文中涉及到的各个系统也有各自的优势和场景。
■ 内容结合过往的经历,难免有一些主观色彩,如有冒犯还请海涵
流计算+存储 场景 1:实时预处理
大概 10 年前,Storm 开源,8000 行 Clojure 代码组成一个完整的流计算系统,惊艳的设计,巧妙的 Ack 机制解决 At-least-once 的问题,解决流计算的基本诉求:
1、数据流起来。
2、数据不丢。但是随着业务的发展,流计算越来越需要 Exactly-once 的保证和 SQL API。
在还没有分布式流计算时,人们往往想通过批的调度来达到实时计算的效果,比如最早使用 Hive 进行分钟级的调度,但是调度和进程启停的成本比较高,所以调度时延并不能太低。Spark 凭借 RDD 优秀的设计,在其之上提供了 Spark Streaming,进程常驻,数据每批次调度过去进行一次 mini-batch 的计算,完全复用了批计算的能力,达到了流计算的能力,以此来提供了 Exactly-once 的一致性保障,但是它并不是常驻进程的流计算,由于调度的开销,最低延时只能到分钟级。
Apache Flink 在 2014 年横空出世,通过内置状态存储和全局一致性快照设计,很好的解决了纯流(early-fire) 模式下保证 Exactly-once 的问题,实现了数据一致性和低延迟的兼顾。
同年笔者加入阿里 Galaxy 团队支撑阿里内部的流计算业务(Galaxy 系统的架构跟 Flink 有很多相似之处,限于篇幅不做展开),并且负责流计算入 Tair (阿里自研的一种 KV 存储,类似 Redis + HBase)的工作。当时的流计算可以说等同于 流计算 + 在线 KV 服务:
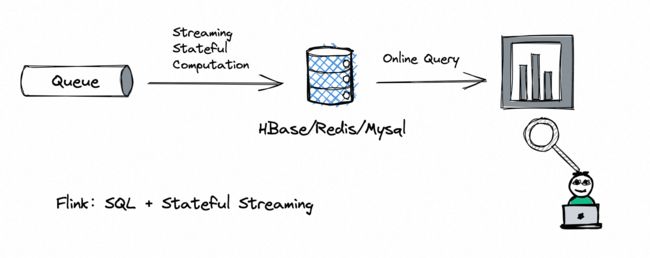
本质上是一种将数据进行多维预处理的技术,预处理后的数据写入模式简单的 KV 系统(HBase 或 Redis)中,或者写入数据存储量较小的关系型数据库中。流计算在此中的作用是 计算流动的数据、并维护状态、把结果输出到 KV 系统中。
这个架构的优缺点分别是:
1、查询速度超快:业务需要查询到的数据都是已经准备好的,KV 系统和关系型数据库作为在线服务,提供毫秒级查询延时。
2、灵活性低、开发成本高:数据集有限(关系型数据库),或者数据模式受限(KV 系统),新增业务需要新增开发一条完整的链路。
它利用了KV系统或关系型数据库的可更新性,能够以幂等更新的方式在达到秒级实时的同时实现最终一致(类Exactly-once)的效果。
当然这个架构也是目前实时数仓比较主流的架构,对于重要业务来说,这是不二之选。
那有没有系统可以更灵活一点,不用为了业务的新增定制一条链路?
流计算+存储 场景 2:实时数仓
ClickHouse 由 Yandex 开发,在 2016 年开源,ClickHouse 看来只是一个单机的 OLAP 引擎,需要一些功夫也能拼出分布式的 OLAP,它的核心亮点是通过向量化的计算带来了超快的查询性能。这带来了一个可能性,可以将业务数据放到 Clickhouse 中,能提供比较灵活的业务查询,而不仅仅只能预定义计算。
随着 ClickHouse 的逐渐流行,国内也涌现出很多优秀的 OLAP 项目,包括 Doris、StarRocks,也包括笔者所在阿里云的 Hologres,同时阿里内部 JStorm、Galaxy、Blink 合并成一个团队,大力发展 Blink,Blink 基于开源的 Flink,有着更新的架构、优秀的设计、高质量的代码和活跃的开源社区。
Flink + Hologres (OLAP 系统) 形成了一个新的场景:通过 Flink 流计算做一些预处理,但是不用形成直接的业务数据,输出到 Hologres,这样 Hologres 保存相对更加完整的数据,提供给业务方高性能的查询,解决了部分 KV 系统不灵活的问题。

这个架构的好处是:
1、查询速度很快:OLAP 系统使用向量化计算,结合固态 SSD 磁盘,高性能机型,提供毫秒级的计算。
2、灵活性较高:OLAP 系统保存 Schema 化的数据,可以根据业务场景使用不同的查询模式。 (OLAP 系统有个通病是 分布式 Join 远不如 聚合,所以一般更多使用大宽表来满足查询性能。)
这个架构也不是完全通用的,有个主要的问题是:OLAP 的存储很贵。(OLAP 也做了一些工作来避免过高的成本,比如存算分离,但是它需要保证查询的实时性,所以从架构上仍然是高成本的设计)
1、其中 Flink 不仅仅只是做一些数据的打宽,也需要做一些数据ETL来确保最后落到 OLAP 系统的数据不会太多,这会带来额外的成本。
2、另外 OLAP 系统也不能保存太久的历史数据,比如一般情况下,保存最近7天的数据,7天前的数据通过 TTL 被淘汰掉。
所以这里就有一个 Trade-Off,是预处理(流计算)多一些,还是把更多的数据放入 OLAP 系统,不同的业务有不同的选择。
■ 那有没有办法可以再灵活一点,以比较低的成本保存所有数据?
流计算+存储 场景 3:实时湖仓
流计算+存储 场景 3.1:Hive 实时化
既然 OLAP 存储比较贵,那我们就将流计算的结果写入到一个不那么贵的存储里,通过存储所有数据,提供灵活的 Ad-hoc 查询 (虽然没 OLAP 那么快)。
另外笔者加入 Blink 团队后,最开始的主要工作是 Blink 的批计算上,随着后续的发展,也在思考流批一体不仅仅只是计算的一体,计算的一体本质上并不能带来足够的业务价值。
所以笔者和小伙伴开启了 Flink + Hive 存储 (流批融合) 的一些工作:

之前的文章:基于 Flink + Hive 构建流批一体准实时数仓
Flink Hive Sink 支持写入 Parquet、ORC、CSV 等格式,提供 Exactly-once 的写入一致性保证,也支持配置分区提交的能力。这解决日志数据流入 Hive 离线数仓的能力,它的优缺点有:
1、离线数仓近实时化,为了一致性保证,延时是 Checkpoint 级别的,一般在分钟级。
2、存储成本低,存储大部分原始数据,非常灵活。
3、查询性能差,数据只是列存,存储到便宜的机器和便宜的磁盘上,读取较慢。
流计算+存储 场景 3.2:Iceberg 实时化
随着国外 Snowflake 和 Databricks 的崛起,湖存储成为了取代传统 Hive 数仓的新兴力量。
Apache Iceberg 是比较典型的湖存储,它作为替代 Hive 的方案有着以下好处:
1、提供 ACID 一致性保证:
a. 数据更安全了,这意味着你可以做一些小数据的操作:比如 INSERT INTO 一些数据,DELTE \ UPDATE \ MERGE_INTO 有着更好的支持。
b. 而不是像 Hive 一样,要安全的动数据只能 INSERT OVERWRITE 整个分区。
2、易扩展的元数据管理:
a. 对象存储的 list 文件非常慢,使用 Iceberg 的元数据管理,可以避免 list 文件带来的性能瓶颈。(为什么要上对象存储,因为存储可分级便宜啊)
b. 这意味着你可以摆脱 Hive Metastore 里面保存 Partition 信息的各种瓶颈问题 (HMS 的 Mysql 又挂了)。
c. 基于元数据的 Data Skipping,可以在离线数仓近实时化场景下,除了提升数据新鲜度,还能(基于排序字段的过滤)降低查询的延迟,也给进一步的索引加速带来了可能。
3、流读流写更容易和自然。
所以笔者和小伙伴参与了 Iceberg 社区,给 Iceberg 社区带来了 Flink 的集成:
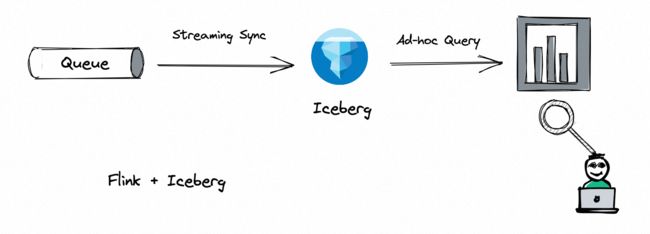
数据可以实时入湖,甚至 Iceberg 的数据也可以被实时流读。在 Hive 离线数仓的基础上增强了可用性。
但是,该解决方案缺乏对 Upsert 场景的支持,存在以下问题:
1、离线数仓最头疼的场景是 CDC 入仓,传统的全量表 + 增量表的方案,不仅存储成本高,计算成本也高,操作还繁琐。
2、流计算过程产生的 CDC 数据无法很好的处理。
CDC 入仓:全量与增量
传统的 Hive 数仓在解决 CDC 入仓时使用了 全量表 + 增量表的技术,具体如图:

具体步骤如下:
1、等到 24 点后,同步当天的 Binlog 数据产出一份增量数据,形成增量表的一个分区。
2、将当天的增量表分区与前一天的全量表分区进行合并,产出全量表的当天分区。
3、全量表分区面向全量查询,增量表分区面向增量查询。
可以看出,这个过程的成本非常高,特别对于大全量少增量的表:
1、存储成本非常高,每天一个全量,每天一个增量,完全没有复用。
2、计算成本非常高,每天都需要全量的读写合并。
3、延时 T + 1,只能用作离线查询。
4、离线表的准备时间也很长,需要等待全增量合并。
那假设有一个能够更好支持 Upsert 更新的数据湖系统,数据直接 Upsert 写进去怎么样?那此时数据湖里面的这张表就是业务数据库那张表的镜像,流 + 湖存储 需要一个支持按主键更新的数据湖!
流计算+存储 场景 3.3:Upsert 的探索
2020 年,笔者所在阿里云团队调研了三大数据湖:Iceberg、Hudi、Delta,当时阿里云的胡争 (后面的 Iceberg PMC 成员) 写了一篇非常好的文章:深度对比 Delta、Iceberg 和 Hudi 三大开源数据湖方案 里面的总结非常有趣:
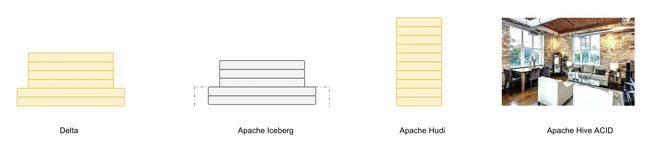
如果用一个比喻来说明 Delta、Iceberg、Hudi、Hive-ACID 四者差异的话,可以把四个项目比做建房子。
1、 Delta 的房子底座相对结实,功能楼层也建得相对高,但这个房子其实可以说是 Databricks 的 。
(笔者补充:今天 Delta 依然是 Databricks 的,也对接了其它引擎,但成熟度不高,开源版本距离 Databricks 商业版也有一定差距)
2、Iceberg 的建筑基础非常扎实,扩展到新的计算引擎或者文件系统都非常的方便,但是现在功能楼层相对低一点
(笔者补充:今天 Iceberg 建筑扎实,北美数仓 SAAS 强者众多,各个批数仓对接 Iceberg,在北美风生水起)
3、Hudi 的情况有所不同,它的建筑基础设计不如 iceberg 结实,举个例子,如果要接入 Flink 作为 Sink 的话,需要把整个房子从底向上翻一遍,同时还要考虑不影响其他功能;但是 Hudi 的楼层是比较高的,功能是比较完善的 。
(笔者补充:Hudi 功能多,各种功能都有,目前在中国流行起来,Upsert 写入在中国打开了局面)
4、Hive-ACID 的房子,看起来是一栋豪宅,绝大部分功能都有,但是细看这个豪宅的墙面是其实是有一些问题的 。
(笔者补充:Hive-ACID 国内应用案例较少)
扎实的房子对我们来说更具有诱惑力,我们坚信能基于 Iceberg 打造出属于 Streaming 的 Lakehouse,所以选取了 Iceberg 作为后续主要的方向来突破,胡争和笔者在 Iceberg 社区突破两个方向:
1、Flink 集成:如何基于 Flink 和 Iceberg 构建云原生数据湖?
2、CDC 入湖:Flink 如何实时分析 Iceberg 数据湖的 CDC 数据

一个阶段性产出是 Flink + Iceberg 进入生产可用,Flink 入湖成为主流应用,CDC 入湖基本可用。
但是,CDC 只是基本可用,离我们的想象还差的较远,大规模更新与近实时延时都有距离,更别说流读的增强了,主要的原因有如下:
1、Iceberg 社区基本盘还是在离线处理,它在国外的应用场景主要是离线取代 Hive,它也有强力的竞争对手 Delta,很难调整架构去适配 CDC 流更新。
2、Iceberg 扩展性强,对其它计算引擎也暴露的比较多的优化空间,但是这也导致后续的发展难以迅速,涉及到众多已经对接好的引擎。
这并没有什么错,后面也证明了 Iceberg 主打离线数据湖和扩展性是有很大的优势,得到了众多国外厂商的支持。
Upsert 探索的另一个方向是 Flink + Hudi,当时阿里云的陈玉兆 (后面的 Hudi PMC 成员) 加入 Hudi 社区一起推出 Flink + Hudi Connector。
2021 年 12 月 FFA 的分享:使用 Flink Hudi 构建流式数据湖平台
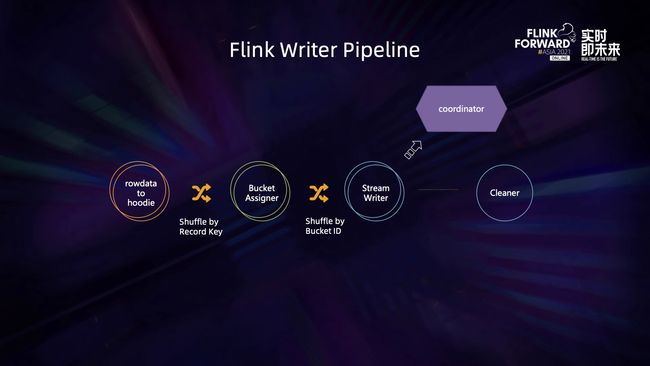
Hudi 默认使用 Flink State 来保存 Key 到 FileGroup 的 Index,这是一套和 Spark 完全不同的玩法:
1、好处是全自动,想 Scale Up 只用调整并发就行了
2、坏处是性能差,直接让湖存储变成了实时点查,超过5亿条数据性能更是急剧下降。
3、存储成本也高,RocksDB State 保存所有索引。
4、数据非常容易不一致,甚至再也不能有别的引擎来读写,因为一旦读写就破坏了 State 里面的 Index。
针对 Flink State Index 诸多问题,字节跳动的工程师们在 Hudi 社区提出了 Bucket Index 的方案 Hudi Bucket Index 在字节跳动的设计与实践
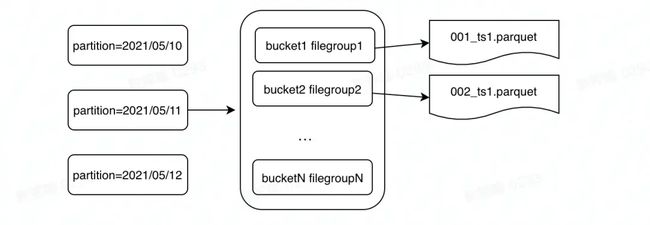
此方案非常简单,但又解决问题:“给定 n 个桶, 用 Hash 函数决定某个记录属于哪个桶。最终所有分区被分成 N 个桶,每个桶对应一个 File Group。”
1、好处是去除了 Index 带来了诸多性能问题。
2、坏处是需要手动选取非常合适的 Bucket Number,多了小文件操作很多,少了性能不行。
这套方案也是目前 Hudi 体量较大的用户的主流方案。
Hudi 在阿里云上也有不少的用户,但是随着用户的增多,问题浮现出来了:
1、Hudi 众多的模式让用户难以选择。
a. 使用 Flink State 还是 Bucket Index?一个易用性好但是性能不行,一个难以使用。
b. 使用 CopyOnWrite 还是 Merge On Read?一个写入吞吐很差,一个查询性能很差。
2、更新效率低,1-3 分钟 Checkpoint 容易反压,默认 5 次 Checkpoint 合并,一般业务可接受的查询是查询合并后的数据;全增量一体割裂,难以统一。
3、系统设计复杂,Bugs 难以收敛,工单层出不穷 (笔者也当过半年 Hudi 负责人);各引擎之间的兼容性也非常差;参数众多。
Hudi 天然面向 Spark 批处理模式设计而诞生,不断在面向批处理的架构上进行细节改造,无法彻底适配流处理更新场景,在批处理架构上不断强行完善流处理更新能力,导致架构越来越复杂,可维护性越来越差。
Hudi 的稳定性随着近几个版本已经好很多了,我觉得这可以归功于来自中国的开发者和使用者们,他们解决 Hudi 各种各样的稳定性和正确性的漏洞,一步一步踩坑探索实时数据湖。
但是,看看最新的 Hudi Roadmap:Roadmap | Apache Hudi
你会发现 Flink 相关,流相关依然少的可怜,往往 Hudi 社区做了一个新 Feature,只有 Spark 支持,Flink 支持不了,如果 Flink 要支持,需要天翻地覆的重构,大重构又会诞生很多的 Bugs,还不一定能支持的很好。Hudi 是个好系统,但它不是为实时数据湖而生的。
那我们需要什么?
1、一个湖存储有着类似 Iceberg 良好的建筑基础,功能满足湖存储的基本诉求。
2、一个具有很强 Upsert 能力的存储,需要 OLAP 系统 & 流计算 State & KV 系统 都使用的 LSM 结构。
3、一个 Streaming First,面向 Flink 有最好集成的存储,这座房子的地基应该直接考虑 Streaming & Flink 的场景,而不是在一个复杂的系统上修修补补,越走到后面,越吃力。
4、一个更多面向中国开发者以及使用者的社区,而且社区的主方向应该是长期投入 Streaming + Lake。
Streaming Lakehouse 的路还很长,那就造一个吧。
Apache Paimon 的诞生
FTS 起源:DB 还是数据湖
2021 年末,笔者在 Flink 社区发起了 FLIP-188 的讨论:Introduce Built-in Dynamic Table Storage。FLIP-188: Introduce Built-in Dynamic Table Storage
从零开始打造一个全新的存储 Flink Table Store (FTS),本意是想提供一个 Flink 完全内置的存储,解决实时、近实时、Queue、Table Format 的所有问题,结合 Flink + 这个内置存储,提供 Materialized View 的自动流处理,直接提供查询服务,打造一个完整的 Streaming DB。

理想是美好的,现实是骨感的。理念过于超前,一步到位的工程难度非常大:
1、Streaming DB All in One 的确带来了易用性的提升,但是大数据领域更多的其实是可用性问题。
2、解决实时预处理的场景:面向在线服务的查询需要高 SLA (服务等级协议) 保障,而 Streaming DB 包含了计算、存储、Pipeline,复杂的系统中很难提供高保障,用户的迁移获得了易用性,损失了高稳定性的保障。
3、解决实时数仓的场景:当今的 OLAP 系统发展迅速,实时数仓提供着高性能的查询,重点是在极致的 OLAP 查询性能,而 Streaming DB 的重点在流,而不是 OLAP,用户的迁移获得了易用性,损失了高性能的查询。
Streaming DB 的大一统理念是好的,但是现实是还差的远,投入巨大收益颇低,不如 step-by-step 解决好现有生产的痛点问题。
FTS 成形:湖 + LSM
随着几个月的研发,也逐渐清晰了起来,先从湖存储做起,更好的串联整个实时数据湖的 data pipeline,结合现有生态解决生产使用当中存在的痛点问题。终于在 5 月份发布了 0.1,这是一个基本不可用的 Demo 版本,但是作为一个从零开始的项目,已经不容易了。
2021 年 9 月,发布了 0.2 版本,0.2 打了一个比较好的底子了,也陆续有同学将 Flink Table Store 用到生产环境上。

(和今天 Paimon 的架构相比,Log System 不再被推荐使用,Lake Store 的能力大幅强于 Log System,除了延时)
Flink Table Store 是一个数据湖存储,用于实时流式 Changelog 写入 (比如来自 Flink CDC 的数据) 和高性能查询。它创新性的结合湖存储和 LSM 结构,深度对接 Flink,提供实时更新的系统设计,支撑大吞吐量的更新数据摄取,同时提供良好的查询性能。
Flink Table Store 0.2 发布文章:Apache Flink Table Store 0.2.0 发布
文章中有性能对比,虽然测试 Pattern 比较简单,但基本也让 Flink Table Store 的设计理念,得到了证明,不再是纯技术分析了。也推荐大家结合生产来测试,而不是仅仅是 Benchmark。
接下来,Flink Table Store 0.3 发布了:Flink Table Store 0.3 构建流式数仓最佳实践
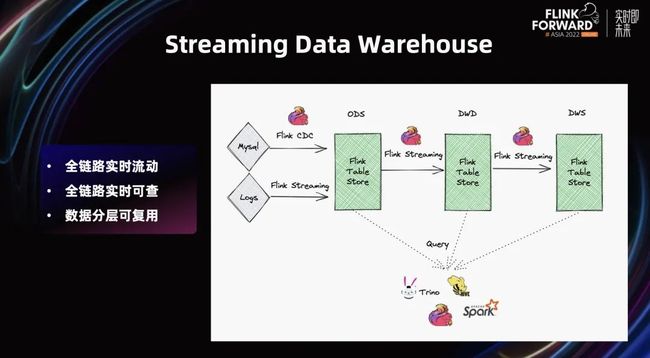
0.3 形成了一个 Streaming Lakehouse 的基本雏形,我们可以比较自信的说出,0.3 可以推荐生产可用了。
基于 Flink Table Store 不仅可以支持数据实时入湖,而且支持 Partial Update 等功能,帮助用户更灵活的在延迟和成本之间做均衡。
Paimon 进入孵化器
在发布了三个版本后,虽然 Flink Table Store 具备了一定的成熟度,但作为 Flink 社区的一个子项目,在生态发展(比如 Spark 用户选择和使用)方面存在比较明显的局限性。为了让 Flink Table Store 能够有更大的发展空间和生态体系, Flink PMC 经过讨论决定将其捐赠 ASF 进行独立孵化。
2023 年 3 月 12 日,Flink Table Store 项目顺利通过投票,正式进入 Apache 软件基金会 (ASF) 的孵化器,改名为 Apache Paimon (incubating)。
进入孵化器后,Paimon 得到了众多的关注,包括 阿里云、字节跳动、Bilibili、汽车之家、蚂蚁 等多家公司参与到 Apache Paimon 的贡献,也得到了广大用户的使用。

(进入 Apache 孵化器后,Paimon 的关注得到了比较大的增长)
并且,Paimon 和 Flink 集成也在继续,Paimon 集成了 Flink CDC,提出了全自动的 数据 + Schema 的同步,整库同步,给你带来 更高性能的入湖、更低的入湖成本、更方便的入湖体验。最新的架构如下:
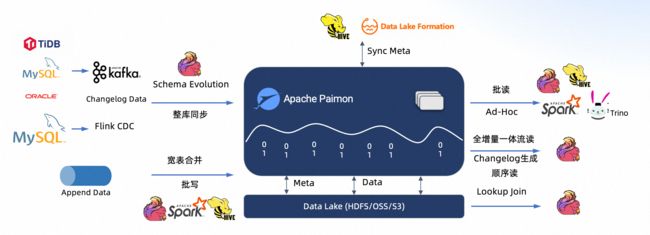
Apache Paimon 到底解决什么问题?
Paimon 实时 CDC 入湖
回顾之前说到 CDC 入湖的那些问题,传统离线数仓需要维护全量分区表和增量分区表,而 Paimon 的 CDC 入湖的方案可以是这样:

具体步骤如下:
1、创建一个无分区的主键表,流式写入 CDC 数据,更新其中的值。
2、最新数据可以被实时查询到。
3、每天的离线视图可以通过 CREATE TAG 创建,Tag 是一个 snapshot 的引用。
4、甚至增量视图可以通过 INCREMTENTAL 视图获取到 (比如支持查询两个 TAG 的 DIFF)。
这个架构的好处是:
1、存储成本不高,基于LSM数据结构的特点,只要增量数据不大,两个 TAG 之间是可以复用大量文件的,某些场景有上百倍的节省!(此处不展开,相关知识可以看看 RocksDb 文档)
2、计算成本不高,主要是实时 Upsert 写入的成本,部分场景相比于 Hive 有10倍以上的节省!
3、数据新鲜度从小时级提升到分钟级,延时近实时可见!
4、离线表准备从 小时级 -> 分钟级,CREATE TAG 返回非常快!
Paimon 在这里需要什么能力?
1、方便的 CDC 入湖,Paimon 0.4 - 0.5 集成了 Flink CDC 入湖,甚至也提供了 Kafka CDC 入湖的能力,相比于 Flink SQL 入湖,Paimon 的 CDC 入湖不但可以将数据和 Schema 的变更一起同步到 Paimon 的表中,而且支持整库同步,大幅降低维护成本和资源使用。
2、很强的主键更新能力,得益于 LSM 的设计和良好的代码细节,Paimon 的更新即使在 1 分钟延时级别也可以有比较好的吞吐和常规的查询性能。
3、大幅降低存储成本,LSM 文件结构避免数据的膨胀。
4、支持 CREATE TAG,支持读取 INCREMENTAL 视图。
Paimon 实时宽表与流读
Paimon 不仅仅只是解决 CDC 入湖的技术,它是一个真正的可以被 Streaming 使用的数据湖,比如解决 近实时宽表问题,提供 Changelog 流读。
Paimon 提供 Partial-Update 表类型,你可以使用多个流作业来写入同一个 Paimon Partial-Update 表,更新不同的字段 (甚至按照不同的版本来更新不同的字段),业务查询可以直接查询到打宽之后的全部列。
后续 Paimon 甚至希望提供外键打宽的能力,进一步增强 Flink + Paimon 的计算能力 (近实时)。希望通过 Paimon 对 Join 的加强,解锁更多的离线数仓实时化场景,对实时来说,不管是流计算还是 OLAP,Join 都是一个非常大的短板,这个短板值得 流式数据湖 往前去探索。
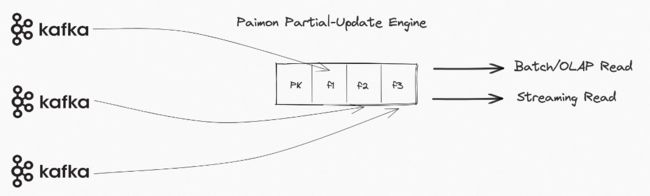
有更新就有 Changelog 生成流读的需求,如果流读下游的计算依赖看到完整的合并后的一行,就需要存储本身生成 Changelog。
Paimon 提供了 full-compaction 的 changelog-producer,你可以理解 full-compaction 可能导致全部数据重写,代价比较大,有的场景甚至使用 Avro 格式 (Avro 全量读写性能更好) 都难以满足。
得益于 Paimon 原生的 LSM 组织结构,在写入时可以通过点查来获取到旧值,从而生成完整的 Changelog:

通过 Lookup 的 Changelog-producer,你可以构建实时的流 Pipeline,且带来完整正确的流处理。
流读不仅仅是 Changelog 生成,你甚至可以在 Paimon 里指定类似 Kafka 的 group-id:
SELECT * FROM t /*+ OPTIONS('consumer-id' = 'myid') */;
当流读取 Paimon 表时,消费的 snapshot id 会被记录到对应的文件里。这有几个优点:
1、当上一个作业停止时,新启动的作业可以继续从上一个进度消费,而无需从状态恢复。新的读取作业将从 consumer 文件中找到的下一个 snapshot id 开始读取。
2、在决定 snapshot 是否已过期时,Paimon 会查看文件系统中表的所有 consumers,如果仍有 consumer 依赖于此 consumer,则此 consumer 将不会在过期时删除。
3、通过 Consumer-id,Watermark 会自动传递到下游中,这意味着你可以通过 Snapshot 里面的 Watermark 来判断计算的进度。
Paimon 的优势
Paimon 整体的优势:
1、Paimon 基于 数据湖 + LSM,有很强的 Upsert 更新能力,有天然的 DataSkipping 能力。
2、Paimon 从 Flink 中孵化出来,支持 Flink SQL 所有特性,包括 Flink CDC,Spark 也是生态中必须的一环,所以 Paimon 从一开始就面向多计算引擎。
3、Paimon 原生面向实时数据湖场景进行设计,能够大幅提升数据湖全链路的数据新鲜度,快速迭代,快速发展。
4、Paimon 项目由国人发起和主导,具备更好的本地化支持 (请加钉钉讨论群)。
最大的好处其实还是没有包袱,从零设计的向前走,流式数据湖到今天依然有非常多的问题需要解决,如果是拉着大车往前走,走的很慢,走的很艰难,而 Paimon 的使命只有一个:流式数据湖。
总结与后续
本文通过笔者的经历,大致梳理了流计算 + 湖存储的历史和发展:
1、Storm:流计算 += 不准确的实时预处理。
2、Spark:流计算 += Mini-Batch 预处理。
3、Flink + HBase/Redis/Mysql:流计算 += 准确的实时预处理。
4、Flink + OLAP:流计算 += 实时数仓,预处理和成本的权衡,高性能 OLAP 带来了一定的灵活度。
5、Flink + 数据湖:流计算 += 离线数仓部分实时化。
6、Flink + 流式数据湖:流计算 += CDC 流式增量计算,解决更多痛点。
7、未来:Streaming Lakehouse,通用的 Lakehouse 架构。
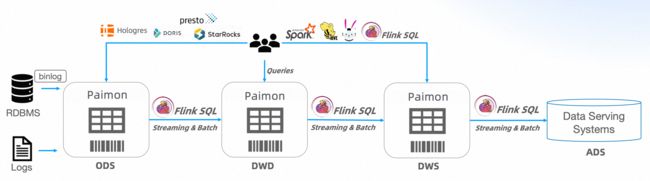
希望达到以下目标:
1、数据全链路实时流动,同时沉淀所有数据,提供 AD-HOC 查询。
2、通用的离线数据实时化,流批融合的一套数仓。
路还长,但是我们正在全力往前跑。
请关注 Paimon
流式数据湖的发展需要你的支持:
1、关注微信公众号:Apache Paimon ,了解行业实践与最新动态。
2、进入 Paimon 交流钉钉群:搜索 10880001919 ,讨论技术并得到实时的支持。
3、Github GitHub - apache/incubator-paimon: Apache Paimon(incubating) is a streaming data lake platform that supports high-speed data ingestion, change data tracking and efficient real-time analytics. 都看到这里了还不点赞支持下。