【论文阅读】ReaLiSe:Read, Listen, and See: Leveraging Multimodal Information Helps Chinese Spell Checking
文章目录
- 本篇论文所需基础
- 论文内容
- 摘要(Abstract)
- 1. 介绍(Introduction)(略)
- 2. 相关工作
- 3. 模型部分(The REALISE Model)
-
- 3.1 语义编码器(The Semantic Encoder)
- 3.2 语音编码器(The Phonetic Encoder)
- 3.3 图像编码器(The Graphic Encoder)
- 3.4 特征融合模块(Selective Modality Fusion Module)
- 3.5 预训练编码器(Acoustic and Visual Pretraining)
- 4. 实验(Experiments)
-
- 4.1 数据集(Data and Metrics)
- 4.2 实现细节(Implementation Details)
- 4.3 Baselines(略)
- 4.4 实验结果(Main Result)
- 4.5 消融实验(Ablation Study)
- 5. 结论(略)
本篇论文所需基础
- 深度学习基础知识(卷积神经网络、循环神经网络)
- LSTM、GRU、Transformer、BERT、ResNet、Hugging Face
论文内容
使用多模态,包括文本信息、听觉信息(拼音)、和图像信息(字形状),来完成中文拼写矫正(Chinese Spell Checking,CSC) 。
论文地址:https://arxiv.org/abs/2105.12306
论文源码地址:https://github.com/DaDaMrX/ReaLiSe
摘要(Abstract)
Chinese Spell Checking(CSC)任务描述:找出中文文本中的错字并进行修正。
常见错误类型:
- 语义相似(semantically)例,深度学习真的是探案了。常见于打错字,将tainan打成了tanan。
- 语音相似(phonetically):例, 给我拿一平红酒。 常见于拼音打字
- 形状相似(graphically):例,师傅你是做什么王作的。常见于五笔打字
数据集(作为Benchmark):SIGHAN
1. 介绍(Introduction)(略)
略
2. 相关工作
NTOU Chinese Spelling Check System in Sighan-8 Bake-off :为不同的错误设计不同的规则
Word Vector/Conditional Random Field-based Chinese Spelling Error Detection for SIGHAN-2015 Evaluation :条件随机场和隐马尔可夫模型(Conditional Random Field and Hidden Markov Model)
A Hybrid Approach to Automatic Corpus Generation for Chinese Spelling Check : 双向LSTM(bidirectional LSTM)
FASPell: A Fast, Adaptable, Simple, Powerful Chinese Spell Checker Based On DAE-Decoder Paradigm : 基于BERT
Spelling Error Correction with Soft-Masked BERT : 使用GRU检测出错位置,BERT来预测正确的词
Chinese Spelling Error Detection and Correction Based on Language Model, Pronunciation, and Shape :
Confusionset-guided Pointer Networks for Chinese Spelling Check :
SpellGCN: Incorporating Phonological and Visual Similarities into Language Models for Chinese Spelling Check : 图卷积网络(Graph Convolution Network, GCNs)
Building a Confused Character Set for Chinese Spell Checking
3. 模型部分(The REALISE Model)
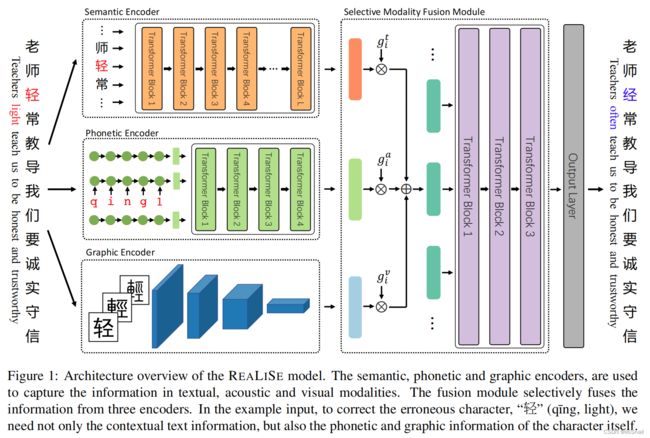
模型包含如下模块:
- Semantic Encoder : 负责对文本语义信息进行编码
- Phonetic Encoder :负责对文本的语音信息(拼音)进行编码
- Graphic Encoder:负责对文本的图像信息(单字图片)进行编码
- Selective Modality Fusion Module:负责将上述的三种特征进行融合
- Output Layer: 预测层,输出修改后的结果。
3.1 语义编码器(The Semantic Encoder)
就是个BERT。作者使用的是 hfl/chinese-roberta-wwm-ext
3.2 语音编码器(The Phonetic Encoder)
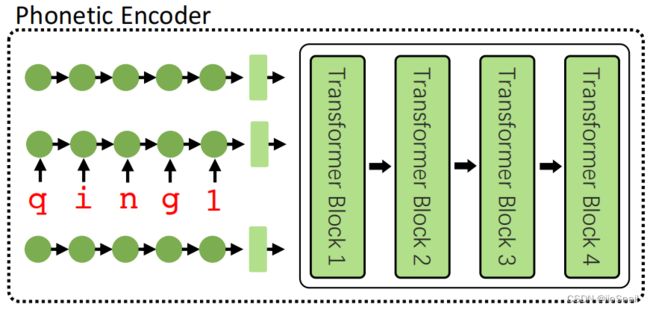
Phonetic Encoder分两部分,前面的圆点是一个单向GRU,称为Character-level Encoder,后面的4层Transformer称为Sentence-level Encoder
Character-level Encoder:作者将每个字都转换成拼音序列,例如将“轻”字转换成 {q, i, n, g, 1},其中1指的是发音为一声。之后将编码后的序列送进GRU,输出对该“字”的编码。该模型会对一个句子的每个字都做这个事情,然后会将所有的字编码送进后面的Sentence-level Encoder。
Sentence-level Encoder:前面的GRU对每个字都进行编码后,使用4层Transformer提取句子的特征表示。
3.3 图像编码器(The Graphic Encoder)
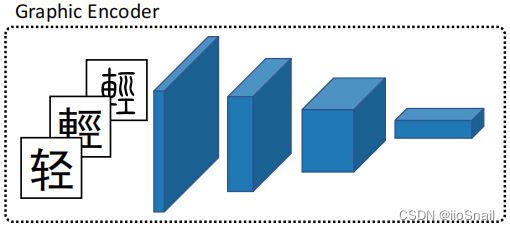
Graphic Encoder将字一个个的送进卷积神经网络,然后提取该字的特征。
卷积神经网络使用的是ResNet5,最终的输出height和width都为1,通道数与Semantic Encoder输出的字编码大小一样,便于后面融合。
字体图片使用的是黑体和小篆,大小为32x32
3.4 特征融合模块(Selective Modality Fusion Module)
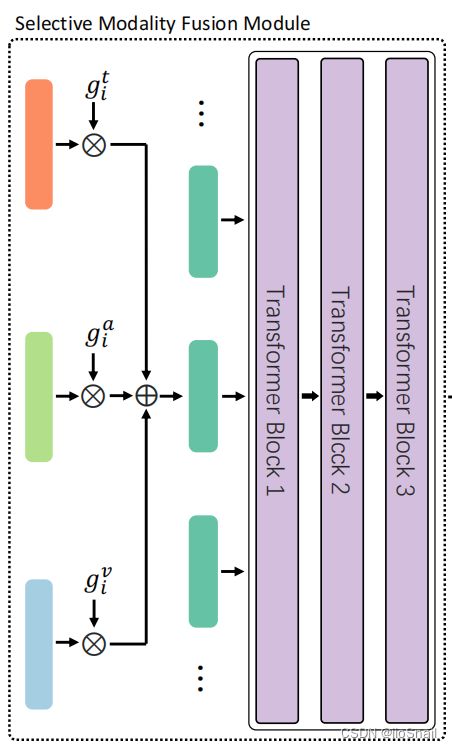
在最后的特征融合层,作者并不是使用简单的相加,而是定义了三个线性层来对三种模态特征进行进一步过滤,类似LSTM的遗忘门,使用公式表示为:
h ˉ t = 1 N ∑ i = 1 N h i t g i t = σ ( W t ⋅ [ h i t , h i a , h i v , h ˉ t ] + b t ) g i a = σ ( W a ⋅ [ h i t , h i a , h i v , h ˉ t ] + b a ) g i v = σ ( W v ⋅ [ h i t , h i a , h i v , h ˉ t ] + b v ) \begin{aligned} \bar{h}^t &=\frac{1}{N} \sum_{i=1}^N h_i^t \\ g_i^t &=\sigma\left(\mathbf{W}^t \cdot\left[h_i^t, h_i^a, h_i^v, \bar{h}^t\right]+b^t\right) \\ g_i^a &=\sigma\left(\mathbf{W}^a \cdot\left[h_i^t, h_i^a, h_i^v, \bar{h}^t\right]+b^a\right) \\ g_i^v &=\sigma\left(\mathbf{W}^v \cdot\left[h_i^t, h_i^a, h_i^v, \bar{h}^t\right]+b^v\right) \end{aligned} hˉtgitgiagiv=N1i=1∑Nhit=σ(Wt⋅[hit,hia,hiv,hˉt]+bt)=σ(Wa⋅[hit,hia,hiv,hˉt]+ba)=σ(Wv⋅[hit,hia,hiv,hˉt]+bv)
其中 h i t h_i^t hit 是Semantic Encoder的第 i i i 个输出。 σ \sigma σ 是sigmoid函数。
使用上述方式得到 g i t g_i^t git, g i a g_i^a gia, g i v g_i^v giv 三个权重,然后对三种特征进行加权:
h ~ i = g i t ⋅ h i t + g i a ⋅ h i a + g i v ⋅ h i v \tilde{h}_i=g_i^t \cdot h_i^t+g_i^a \cdot h_i^a+g_i^v \cdot h_i^v h~i=git⋅hit+gia⋅hia+giv⋅hiv
最终将 { h ~ 1 , h ~ 2 , ⋯ , h ~ n } \{\tilde{h}_1, \tilde{h}_2, \cdots,\tilde{h}_n\} {h~1,h~2,⋯,h~n} 送给后面的Transformer。
3.5 预训练编码器(Acoustic and Visual Pretraining)
Sematic Encoder的预训练:之间使用别人预训练好的BERT(hfl/chinese-roberta-wwm-ext)
Phonetic Encoder的预训练:将拼音转换为汉字,即输入为拼音序列,输出为汉字序列。
Graphic Encoder的预训练:将文字图片转换为汉字,即输入文字图片,预测这个图片是什么字。
4. 实验(Experiments)
4.1 数据集(Data and Metrics)
训练数据集:SIGHAN training data 和 自己造的假数据。
测试数据集:SIGHAN test sets.
数据集地址:
SIGHAN Bake-off 2013: http://ir.itc.ntnu.edu.tw/lre/sighan7csc.html
SIGHAN Bake-off 2014: http://ir.itc.ntnu.edu.tw/lre/clp14csc.html
SIGHAN Bake-off 2015: http://ir.itc.ntnu.edu.tw/lre/sighan8csc.html
Wang271K(自己造的假数据): https://github.com/wdimmy/Automatic-Corpus-Generation
数据集描述如下表:

- #Sent: Sentence数量
- Avg.Lenght: 句子的平均长度
- #Errors:错字的数量
4.2 实现细节(Implementation Details)
Optimizer: AdamW
epochs: 10
learning rate: 5e-5
batch size: 32
learning shcedule: warm up and linear decay
4.3 Baselines(略)
4.4 实验结果(Main Result)

- Acc:Accuracy,准确率
- Pre:Precision,精准率
- Rec:Recall,召回率
- F1:F1 Score
4.5 消融实验(Ablation Study)
去掉部分Encoder后,performance下降了