Hive3第三章:DML数据操作
系列文章目录
Hive3第一章:环境安装
Hive3第二章:简单交互
Hive3第三章:DML数据操作
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 系列文章目录
- 前言
- 一、数据导入
-
- 1. 向表中装载数据(load)
- 2. 通过查询语句导入(insert)
- 二、数据导出
-
- 1.hadoop导出
- 2.insert导出
- 3.shell导出
- 4.Export 导出到 HDFS 上
- 总结
前言
这一次学习DML数据操作的导入和导出数据。
一、数据导入
1. 向表中装载数据(load)
语法
load data [local] inpath ‘数据的 path’ [overwrite] into table student [partition (partcol1=val1,…)];
(1)load data:表示加载数据
(2)local:表示从本地加载数据到 hive 表;否则从 HDFS 加载数据到 hive 表
(3)inpath:表示加载数据的路径
(4)overwrite:表示覆盖表中已有数据,否则表示追加
(5)into table:表示加载到哪张表
(6)student:表示具体的表
(7)partition:表示上传到指定分区
创建一张表
create table student(id string,name string) row format delimited fields terminated by '\t';
简单说一下,创建一张空表,里面含有两个字段,分别是id和name。用’\t’也就是tab做分隔符。


load data local inpath ‘/opt/module/hive/datas/student.txt’ into table default.student;
然后本地随便写点数据做测试,注意格式要一致。
mkdir /opt/module/hive/datas
vim /opt/module/hive/datas/student.txt

然后加载到hive。
load data local inpath '/opt/module/hive/datas/student.txt' into table default.student;

这里的local代表着从本地上传,如果文件以及在hdfs之中就把local去掉,路径换成hdfs路径即可。
现在我们修改修改一下测试文件,然后将其上传到hdfs。

hadoop fs -put /opt/module/hive/datas/student.txt /student.txt

这次我们覆盖式的导入。
load data inpath '/student.txt' overwrite into table default.student;

2. 通过查询语句导入(insert)
这个情况更使用于,要将一张表的一部分内容导出到另一张表中。
先创建一张新表,student1,之后我们把student表中的第二行插入到新表中。
create table student1(id string,name string) row format delimited fields terminated by '\t';

insert into table student1
select id, name from student where id=1002;
为了逻辑清晰,建议分行写,因为hql是以 ; 为结尾所以回车随便用。

这里会调用MR时间会长一点,稍等一下。

这里和上边一样 insert into 是追加,insert overwrite是覆盖。
导入数据还有一些,但是剩下的不太常用,就不说了,以后用到再说。
示例:pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。
二、数据导出
1.hadoop导出
这个就不演示了,用 -put就行。
2.insert导出
insert overwrite local directory '/opt/module/hive/data/student3.txt'
select * from student;


可以看到,这里的导出结果并不规范,现在我们进行规范化的导出。
insert overwrite local directory '/opt/module/hive/data/student4.txt'
REPLACE RESOURCE REWRITE
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
select * from student;
可以看到,命令很长,尽量多用Tab键。

还是把local去掉,路径换成hdfs就可以导出到hafs了。
3.shell导出
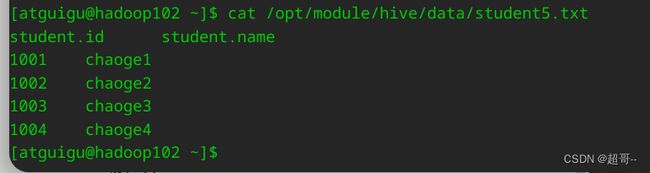
bin/hive -e 'select * from default.student;' >> /opt/module/hive/data/student5.txt
这个和前边的命令行交互有点像,-e + 命令 -f 加脚本
4.Export 导出到 HDFS 上
export table default.student to '/student2';
 注:export 和 import 主要用于两个 Hadoop 平台集群之间 Hive 表迁移。
注:export 和 import 主要用于两个 Hadoop 平台集群之间 Hive 表迁移。
总结
这次的内容就到这里,比较少,主要是下次的查询的内容比较重要,所以准备单写一次博客。