
一、素数的概念
素数又称质数。一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数。
(素数是数论中很重要的部分,所以对于一些素数的操作,需要十分的熟练)
二、判断素数的方法
1.最基础的方法(初学者经常用的方法)
bool isprime(int n)
{
for(int i=2; i<n; i++)
if(n%i==0)
return false;
return true;
}
//直接从2遍历到 n,如果之间可以被 n整除,则 n为合数,反之为素数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.试除法(相当于上个方法的优化)
bool isprime(int n)
{
for(int i=2; i<=sqrt(n); i++)//写成 i*i<=n可以稍微快一点,
if(n%i==0) //因为每次循环都会计算sqrt一次,也可以用变量存起来
return false;
return true;
}
/*
如果是合数的话,那么他的因数一定会有分布在sqrt(n)的范围内的,
就是说一个大于sqrt(n)的数要是可以被 n整除了,它的商肯定是要小于sqrt(n)的,
这时我们就不需要遍历 n个数字,而直接遍历sqrt(n)个数字就可以了
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
上述两种方法完全运用了素数的概念,好理解,但是效率不高。
优化后的第二种方法也是初学者经常用的,虽然比第一种方法时间复杂度小不少,但是也是有O(n1/2),对于一般的题目只能判断到1012,所以对一些再大的数就很不友好
3.六素数法(这是在翻博客的时候发现的一种方法,在百度百科上也有提到,先放到这里)
建议看一下>>百度百科的“六素数偶”部分<<便于理解以下代码
bool isprime(int n)
{
if(n==1)
return false;
if(n==2||n==3)
return true;//1,2,3的情况特殊判断
if(n%6!=1&&n%6!=5)
return false;
int k=sqrt(n)+1;
for(int i=5; i<k; i+=6)//这一部分和试除法类似
if(n%i==0||n%(i+2)==0)
return false;
return true;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
这个的时间复杂度应该是 O(n1/2/3),相比上两种方法,效率还是提高了一些。
三、区间上的素数数量
一般来说,一个和素数相关的问题都是求[2,n]内的素数。如果用上边的方法一个一个来判断,时间复杂度为O(n*n1/2),如果n比较大,可能计算机要跑几分钟。所以这种方法难免会超时,下面说一下可以解决一个区间上素数问题的算法。
1.埃式筛法(埃拉托斯特尼筛法)
基本思想:素数的倍数一定不是素数
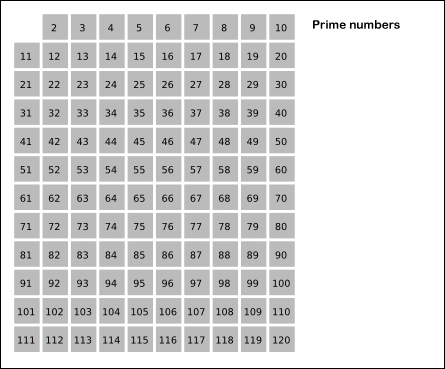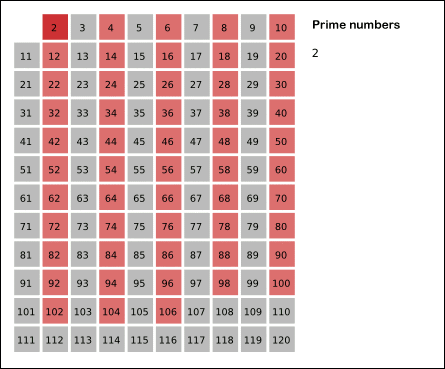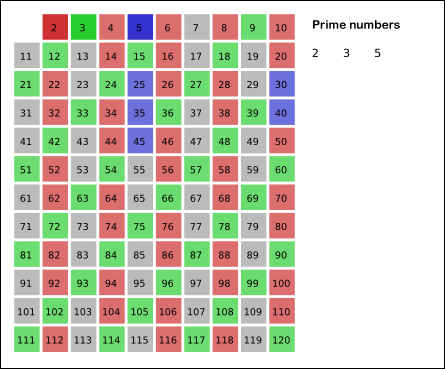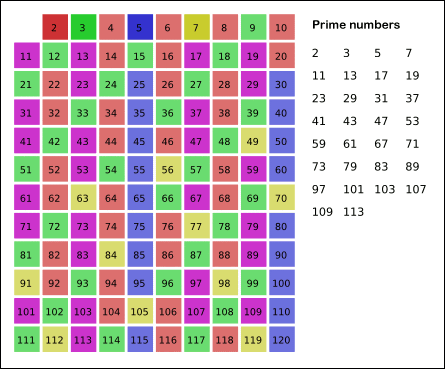
(动图出处: https://www.cnblogs.com/findwg/p/4901219.html)
const int maxx=1e7;//定义空间大小,1e7大约10MB
int prime[maxx+1];//存放素数
bool visit[maxx+1];//true表示被筛掉,表示素数
int E_sieve(int n)//埃式筛,计算[2,n]内的素数
{
for(int i=0; i<=n; i++)
visit[i]=false;
for(int i=2; i*i<=n; i++)//核心代码
if(!visit[i])
for(int j=i*i; j<=n; j+=i)
visit[j]=true;//标记成非素数
int k=0;//作为统计个数的变量
for(int i=2; i<=n; i++)
if(!visit[i])
prime[k++]=i;//储存素数
return k;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
时间复杂度:可以看出来,在核心代码的那部分,一共要进行的循环次数为O(n/2+n/2+n/5+…),即O(nloglog2n),有时候也近似看成O(n)
可以看出,埃式筛法还不错,但是也做了一些无用功,某个数字会被筛选多次,比如12这个数字,在2和3的时候就筛选了两次。
既然有可优化的地方,那必然有更好的算法
2.欧拉筛法(欧拉线性筛)
原理:由于所有合数都有一个最小质因子,所以在埃氏筛法的基础上,让每个合数只被它的最小质因子筛选一次,以达到不重复的目的。
int Oula_gprime()
{
int get=0;
memset(v,0,sizeof(v));
v[0]=v[1]=1;
for(int i=2; i<=maxx; i++)
{
//cout<<"# i = "<
if (!v[i])
prime[get++]=i;
for (int j=0; j<get&&i*prime[j]<=maxx; j++)
{
//cout<<"j = "<
//cout<<"i * prime[j] = "<
v[i*prime[j]]=1;
if (i%prime[j]==0)
break;
}
//cout<
}
return get;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
精华部分(也算是对埃式筛法的优化部分):
for (int j=0; j<get&&i*prime[j]<=maxx; j++)
{
v[i*prime[j]]=1;
if (i%prime[j]==0)
break;
}
/*
我们知道任何合数都能表示成多个素数的积。
所以,任何的合数肯定有一个最小质因子。
我们通过这个最小质因子就可以判断什么时候不用继续筛下去了。
当 i是 prime[j]的整数倍时,i*prime[j+1]肯定再次被筛,就跳出循环。
就比如 i=6,prime[j]=2(这时候 prime已经有了2,3,5),
i%prime[j]==0,所以就可以跳出循环。
因为在下面 prime[j]=3的时候,i*prime[j]=18,
在下一次 i=18的时候,会再循环一次,prime[j]=5的时候也一样
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
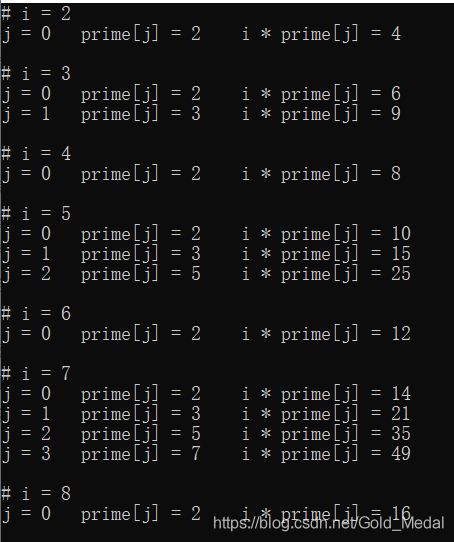
可以发现,在下图的 i:2~8项中,i * prime[j]的值一直没有重复
打表也可以发现,所有的 i * prime[j]一直都不会重复出现
这也就验证了我们一开始的对欧拉筛的另一种叫法:欧拉线性筛,
欧拉筛的时间复杂度也就的确可以做到O(n)的大小。
四、结语
无结语