餐饮数据统计分析---泰迪云课程大作业
餐饮数据统计分析
饮食乃人们生活之本,对于上班一族通常需要点外卖进行就餐,那么就需要在餐饮平台上进行购物。餐饮平台上的商家需要保障食物安全,据《中华人民共和国食品安全法》第十章附则第九十九条规定,食品安全,指食品无毒、无害,符合应当有的营养要求,对人体健康不造成任何急性、亚急性或者慢性危害。商家需要诚信经营,切勿贪图蝇头小利,做违法犯罪之事。
某餐饮外卖平台向广大用户提供网上订餐服务,其市场占有量在近年不断增加。当用户在该平台订餐完成后,平台会引导用户对于品尝过的菜品进行评价打分,因此得到一份菜品评分数据文件mealrating.parquet,该数据包含5个字段,字段说明如表1-1所示。餐饮平台还提供了一份菜单数据meal_list.txt,包含3个字段,字段说明如表1-2所示。
基于两份数据,将实现任务内容如下。
(1) 创建数据库和表并导入数据。
(2) 数据清洗(缺失值、异常值等)。
(3) 数据探索(探索字段间的关系)。
(4) 数据统计分析(如:统计热门菜品和用户评分等)。
通过对餐饮平台提供的数据进行相应的处理,分析用户和菜品信息,为餐饮平台提供营销策略。
开始操作
参考:hive大作业
我和他的区别在于:
- 我的其中一个表格是.parquet格式的;他的两个都是txt格式
- 字段名有点区别
两个表格:


1. 创建两张表
先创建hive数据库:
hive>create database meal;
hive>use meal;
1》创建mealrating表:
hive> create table mealrating (
> userid string,
> mealid string,
> rating double,
> review string,
> reviewtime string)
> stored as parquet;
导入数据:(表格mealrating.parquet在/data里面)
hive>load data local inpath '/data/mealrating.parquet' overwrite into table mealrating;
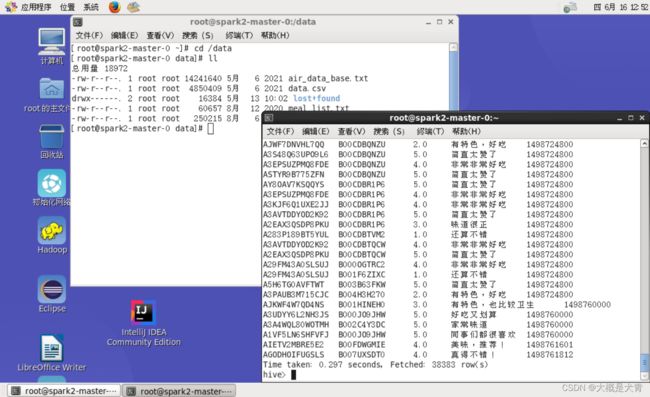
简单验证一下:
hive>select * from mealrating;
2》创建meal_list表格:(这里我手打的没检查对不对)
hive>create table meal_list(
>id int,
>mealid string,
>mealname string)
>row format delimited
>fields terminated by ',';
hive>load data local inpath '/data/meal_list.txt' overwrite into table meal_list;
hive>select * from meal_list;

数据清洗
meal_list表格从1686行开始,字段mealid缺少,这部分数据不需要。(hive删除表格的部分数据)
hive删除参考:hive表格的部分数据
思路:因为是没有分区的表,所以可以用覆盖的方式清洗
代码:
hive> insert overwrite table meal_list
> select * from meal_list limit 1685;
效果截图:虽然是倒叙 但是不影响meal_list后续查询相关操作。

2.分析
1.根据用户评分数据统计日销售量:
hive>select count(1) from mealrating where reviewtime between 1496100000 and 1496200000;
–538
2.日用户量
select count(distinct userid)from mealrating where reviewtime between 1497100000 and 1497200000;
–408
3.统计同时有评分和评分内容的记录
select count(1) from mealrating where rating is not null and review is not null;
–38383
4.分析用户的评分分布情况
select * ,cast(rating/(sum(rating)over())as decimal(8,2)) as rat_percent
> from(
> select rating,
> count(1) rat_num,
> cast(sum(rating)/count(1)as decimal(8,2))avg_rat
> from mealrating group by rating
> )as p order by rat_percent desc;

5.统计10大热销菜品
select name ,count(name)as frequency from mealrating jon meal_list on mealrating.mealid=meal_list.mealid group by name order by frequency desc limit 10;
FAILED: ParseException line 1:57 missing EOF at 'meal_list' near 'jon'

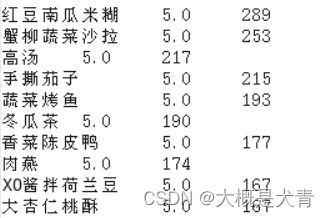
6.十大评分为5.0 的菜
select mealname,rating,count(mealname) as frequency from mealrating join meal_list on mealrating.mealid=meal_list.mealid where rating=5 group by mealname ,rating order by frequency desc limit 10 ;
7.单日评分超过两次的用户数量
select count(*) from (select reviewtime,userid,count(*) from mealrating group by reviewtime,userid having count(*)>2)as tmp;
–2038
8. 找出评分次数超过两次的用户中,每个用户评分最高的记录
select UserID,max(Rating) from mealrating group by UserID having UserID in (select UserID from mealrating group by UserID HAVING count(MealID)>2);