Pytorch学习:神经网络模块torch.nn.Module和torch.nn.Sequential
文章目录
-
- 1. torch.nn.Module
-
- 1.1 add_module(name,module)
- 1.2 apply(fn)
- 1.3 cpu()
- 1.4 cuda(device=None)
- 1.5 train()
- 1.6 eval()
- 1.7 state_dict()
- 2. torch.nn.Sequential
-
- 2.1 append
- 3. torch.nn.functional.conv2d
1. torch.nn.Module
官方文档:torch.nn.Module
CLASS torch.nn.Module(*args, **kwargs)
- 所有神经网络模块的基类。
- 您的模型也应该对此类进行子类化。
- 模块还可以包含其他模块,允许将它们嵌套在树结构中。您可以将子模块分配为常规属性:
training(bool)-布尔值表示此模块是处于训练模式还是评估模式。
定义一个模型
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
- 以这种方式分配的子模块将被注册,并且当您调用
to()等时也将转换其参数。
to(device=None,dtype=None,non_blocking=False)
device ( torch.device) – 该模块中参数和缓冲区所需的设备to(dtype ,non_blocking=False)
dtype ( torch.dtype) – 该模块中参数和缓冲区所需的浮点或复杂数据类型to(tensor,non_blocking=False)
张量( torch.Tensor ) – 张量,其数据类型和设备是该模块中所有参数和缓冲区所需的数据类型和设备
引用上面定义的模型,将模型转移到GPU上
# 创建模型
model = Model()
# 定义设备 gpu1
gpu1 = torch.device("cuda:1")
model = model.to(gpu1)
1.1 add_module(name,module)
将子模块添加到当前模块。
可以使用给定的名称作为属性访问模块。
add_module(name,module)
主要参数:
- name(str)-子模块的名称。可以使用给定的名称从此模块访问子模块。
- module(Module)-要添加到模块的子模块。

添加一个卷积层
model.add_module("conv3", nn.Conv2d(20, 20, 5))
1.2 apply(fn)
将 fn 递归地应用于每个子模块(由 .children() 返回)以及self。
典型的用法包括初始化模型的参数(另请参见torch.nn.init)。
apply(fn)
主要参数:
- fn( Module -> None)-应用于每个子模块的函数
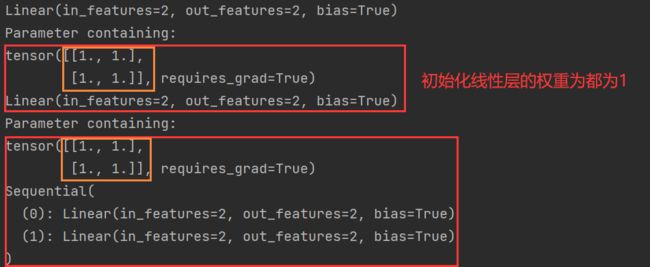
将所有线性层的权重置为1
import torch
from torch import nn
@torch.no_grad()
def init_weights(m):
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0)
print(m.weight)
net = nn.Sequential(nn.Linear(2, 2), nn.Linear(2,2))
net.apply(init_weights)
1.3 cpu()
将所有模型参数和缓冲区移动到CPU。
device = torch.device("cpu")
model = model.to(device)
1.4 cuda(device=None)
将所有模型参数和缓冲区移动到GPU。
这也使关联的参数和缓冲区成为不同的对象。因此,如果模块在优化时将驻留在GPU上,则应在构造优化器之前调用该函数。
cuda(device=None)
主要参数:
- device(int,可选)-如果指定,所有参数将被复制到该设备
转移到GPU包括以下参数:
- 模型
- 损失函数
- 输入输出
# 创建模型
model = Model()
# 将模型转移到GPU上
model = model.cuda()
# 将损失函数转移到GPU上
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()
# 将输入输出转移到GPU上
imgs, targets = data
imgs = imgs.cuda()
targets = targets.cuda()
另一种表示形式(通过 to(device) 来表示)
# 创建模型
model = Model()
# 定义设备:如果有GPU,则在GPU上训练, 否则在CPU上训练
device = torch.device("cuda" if torch.cuda.is_available else "cpu")
# 将模型转移到GPU上
model = model.to(device)
# 将损失函数转移到GPU上
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)
# 将输入输出转移到GPU上
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
1.5 train()
将模块设置为训练模式。
这只对某些模块有任何影响。如受影响,请参阅特定模块在培训/评估模式下的行为详情,例如: Dropout 、 BatchNorm 等。
train(mode=True)
主要参数:
- mode(bool)-是否设置训练模式( True )或评估模式( False )。默认值: True 。
1.6 eval()
将模块设置为评估模式。
这只对某些模块有任何影响。如受影响,请参阅特定模块在培训/评估模式下的行为详情,例如: Dropout 、 BatchNorm 等。
在进行模型测试的时候会用到。
1.7 state_dict()
返回一个字典,其中包含对模块整个状态的引用。
返回模型的关键字典。
model = Model()
print(model.state_dict().keys())
![]()
在保存模型的时候我们也可以直接保存模型的 state_dict()
model = Model()
# 保存模型
# 另一种方式:torch.save(model, "model.pth")
torch.save(model.state_dict(), "model.pth")
# 加载模型
model.load_state_dict(torch.load("model.pth"))
2. torch.nn.Sequential
顺序容器。模块将按照它们在构造函数中传递的顺序添加到它。
Sequential 的 forward() 方法接受任何输入并将其转发到它包含的第一个模块。然后,它将输出“链接”到每个后续模块的输入,最后返回最后一个模块的输出。
官方文档:torch.nn.Sequential
CLASS torch.nn.Sequential(*args: Module)
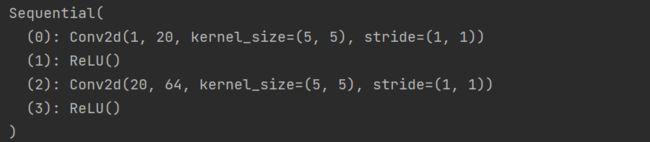
import torch
from torch import nn
# 使用 Sequential 创建一个小型模型。运行 `model` 时、
# 输入将首先传递给 `Conv2d(1,20,5)`。输出
# `Conv2d(1,20,5)`的输出将作为第一个
# 第一个 `ReLU` 的输出将成为 `Conv2d(1,20,5)` 的输入。
# `Conv2d(20,64,5)` 的输入。最后
# `Conv2d(20,64,5)` 的输出将作为第二个 `ReLU` 的输入
model = nn.Sequential(
nn.Conv2d(1, 20, 5),
nn.ReLU(),
nn.Conv2d(20, 64, 5),
nn.ReLU()
)
2.1 append
append 在末尾追加给定块。
append(module)
在末尾追加给定模块。

def append(self, module):
self.add_module(str(len(self)), module)
return self
append(model, nn.Conv2d(64, 64, 5))
append(model, nn.ReLU())
print(model)
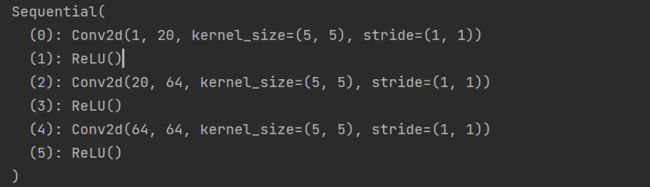
3. torch.nn.functional.conv2d
对由多个输入平面组成的输入图像应用2D卷积。
卷积神经网络详解:csdn链接
官方文档:torch.nn.functional.conv2d
torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1)
主要参数:
- input:形状的输入张量,(minibatch, inchannels, iH, iW)。
- weigh:卷积核权重,形状为 (out_channels, inchannels / groups, kH, kW)
默认参数:
- bias:偏置,默认值: None。
- stride:步幅,默认值:1。
- padding:填充,默认值:0。
- dilation :内核元素之间的间距。默认值:1。
- groups:将输入拆分为组,in_channels 应被组数整除。默认值:1。
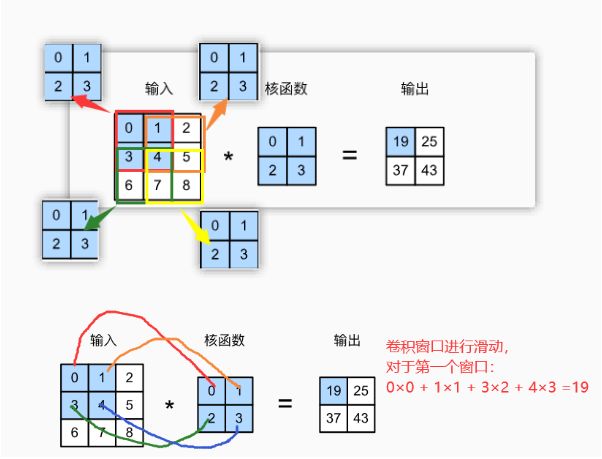
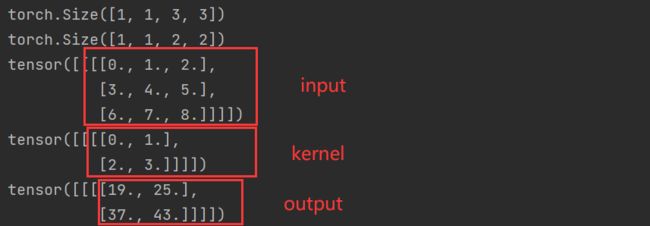
对上图卷积操作进行代码实现
import torch.nn.functional as F
input = torch.tensor([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]], dtype=float32)
kernel = torch.tensor([[0, 1],
[2, 3]], dtype=float32)
# F.conv2d 输入维数为4维
# torch.reshape(input, shape)
# reshape(样本数,通道数,高度,宽度)
input = torch.reshape(input, (1, 1, 3, 3))
kernel = torch.reshape(kernel, (1, 1, 2, 2))
output = F.conv2d(input, kernel, stride=1)
print(input.shape)
print(kernel.shape)
print(input)
print(kernel)
print(output)