mysql知识汇总
查看数据库
show databases;
创建一个数据库
create database database_name;#创建一个数据库,database_name为所要创建的数据库名称
create database if not exists database_name;#创建一个数据库,如果该数据库不存在
create database database_name character set utf8;#创建一个数据库,该数据库为utf-8
修改数据库
alter database database_name character set charset;#charset为字符集
删除一个数据库
drop database database_name;#删除一个数据库,database_name为所要创建的数据库名称
drop database if exists database_name;#删除一个数据库,如果该数据库存在
选择使用某一个数据库
use database_name;
创建表
create table table_name(field1 type,field2 type,...);
删除表
drop table table_name;
修改表类型及名称
alter table table_name modify field type(size);
alter table table_name modify c char(10);#这是一个例子
alter table table_name change field field_another_name type;
修改数据默认值
alter table table_name modify field type not null default value;
alter table table_name modify field type not null default 100;#将值默认设置为100
alter table table_name alter field set default value;
修改引擎
alter table table_name engine=new_engine;
修改表名
alter table table_name rename to new_table_name;
向表中插入数据
insert into table_name values(corresponded_data_type);#corresponded_data_type为相应的数据类型
从表中查询数据
select * from table_name;#查询所有的field元素的行
select field1field2,... from table_name;#依据field查询行
select * from database_name where field1=...,field2=...;
更新数据
update table_name set field1=new_value1,field2=new_value2... where field=value;
删除数据
delete from table_name;#这个操作将删除表中的所有数据
delete from table_name where field1=value1...;#删除指定的数据
alter table table_name drop field_value#删除指定的数据
如果只剩余一个字段则无法使用drop删除
增加数据
alter table table_name add field_value type;#表尾添加数据
alter table table_name add field_value type first;#在表头添加数据
alter table table_name add field_value type after field_value_another;#在另一个数据后添加
like语句
select field1,field2... from table_name where field1 like field1='xxx%xxx';#模糊查询,%的位置可变
'%a' //以a结尾的数据
'a%' //以a开头的数据
'%a%' //含有a的数据
'_a_' //三位且中间字母是a的
'_a' //两位且结尾字母是a的
'a_' //两位且开头字母是a的
%:表示任意 0 个或多个字符。可匹配任意类型和长度的字符,有些情况下若是中文,请使用两个百分号(%%)表示。
_:表示任意单个字符。匹配单个任意字符,它常用来限制表达式的字符长度语句。
[]:表示括号内所列字符中的一个(类似正则表达式)。指定一个字符、字符串或范围,要求所匹配对象为它们中的任一个。
[^] :表示不在括号所列之内的单个字符。其取值和 [] 相同,但它要求所匹配对象为指定字符以外的任一个字符。
查询内容包含通配符时,由于通配符的缘故,导致我们查询特殊字符 “%”、“_”、“[” 的语句无法正常实现,而把特殊字符用 “[ ]” 括起便可正常查询。
union
union操作符用于连接两个及以上的select语句的结果组合到一个集合中。
select expression1,... from table_name1 condition1 union select expression2,... from table_name2 condition2;
排序
order by排序
select * from table_name order by field1,field2... asc/desc;#asc升序,desc降序,默认升序
tips:如果字符集为gbk可直接使用order by,如果字符集为utf-8,使用order by convert(table_name using gbk)
with rollup
select field1,sum(field2),... as field_another_name from table_name froup by field3 with rollup;
coalesce语法
select coalesce(field1,'总数') from table_name group by field2 with rollup;#这里如果field1为NULL,则替换为总数
join
从多个表中组合数据
inner join
select table_name1.field1,table_name1.field2,table_name2.field3 from table_name1 inner join table_name2 on condition1...;
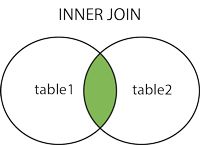
left join
在相同的位置替换inner join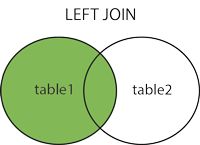
right join
在相同的位置替换inner join
对null的处理
| is null | 当列的值是null,返回TRUE |
|---|---|
| is not null | 当列的值不是null,返回TRUE |
| <=> | 当比较的两个值相等或者都为null是返回TRUE |
不能使用=null或者!=null这样的运算。null=null返回null。
ifnull(field,0)将field中null的值转为0
正则表达式
| ^ | 匹配输入字符串的开始位置。如果设置了 RegExp 对象的 Multiline 属性,^ 也匹配 ‘\n’ 或 ‘\r’ 之后的位置。 |
|---|---|
| $ | 匹配输入字符串的结束位置。如果设置了RegExp 对象的 Multiline 属性,$ 也匹配 ‘\n’ 或 ‘\r’ 之前的位置。 |
| . | 匹配除 “\n” 之外的任何单个字符。要匹配包括 ‘\n’ 在内的任何字符,请使用像 ‘[.\n]’ 的模式。 |
| […] | 字符集合。匹配所包含的任意一个字符。例如, ‘[abc]’ 可以匹配 “plain” 中的 ‘a’。 |
| [^…] | 负值字符集合。匹配未包含的任意字符。例如, ‘[^abc]’ 可以匹配 “plain” 中的’p’。 |
| p1|p2|p3 | 匹配 p1 或 p2 或 p3。例如,‘z|food’ 能匹配 “z” 或 “food”。‘(z|f)ood’ 则匹配 “zood” 或 “food”。 |
| * | 匹配前面的子表达式零次或多次。例如,zo_ 能匹配 “z” 以及 “zoo”。_ 等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,‘zo+’ 能匹配 “zo” 以及 “zoo”,但不能匹配 “z”。+ 等价于 {1,}。 |
| {n} | n 是一个非负整数。匹配确定的 n 次。例如,‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o。 |
| {n,m} | m 和 n 均为非负整数,其中n <= m。最少匹配 n 次且最多匹配 m 次。 |
查找name字段中以’st’为开头的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP '^st';
查找name字段中以’ok’为结尾的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP 'ok$';
查找name字段中包含’mar’字符串的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP 'mar';
查找name字段中以元音字符开头或以’ok’字符串结尾的所有数据:
SELECT name FROM person_tbl WHERE name REGEXP '^[aeiou]|ok$';
事务
主要用于处理操作量大,复杂度高的数据。
begin开始事务
commit提交事务
rollback回滚到上一状态
索引
创建索引
create index index_name on table_name (field);
添加索引
alter table table_name add index indexname(field);
直接在创建表的时候添加索引
create table table_name(
field1 type,
field2 type,
...
index indexname(length)
);
删除索引
drop index indexname on table_name;
唯一索引
create unique index indexname on table_name(username(length));
显示索引信息
show index from table_name\g;
临时表
临时表只在当前连接可见,当关闭连接时,mysql会自动删除表并释放所有空间
创建临时表
create temporary table table_name(
field1 type,
field2 type,
...
);
删除临时表
drop table table_name;
用查询创建临时表
create temporary table table_name as
(
select * from old_table_name
limit 0,10000
);
复制表
第一种方式
第一步 获取数据表的完整结构
show create table table_name \g;
第二步 修改SQL语句的数据表名,并执行SQL语句
create table new_table_name(
结构直接复制第一步所得的结构
);
第三步 复制数据
insert into new_table_name(old_field1,old_field2...) select old_field1,old_field2... from old_table_name;
第二种方式
只复制表结构
create table new_table select * from old_table;
create table old_table like new_table;
复制表结构及数据
create table new_table select * from old_table;
元数据
select version();#获取服务器版本信息
select database();#获取当前数据库名
select user();#获取当前用户名
show status;#获取服务器状态
show variables;#获取服务器配置变量
序列
select last_insert_id();#获取最后的插入表中的自增列的值
处理重复数据
在创建的表中设置数据唯一
create table table_name
(
field1 type,
field2 type,
'''
primary key (field1,field2,...)/unique(field1,field2)
);
插入不同的数据
insert ignore into table_name values();
统计重复数据
select count(*) as new_field1,new_field2,... from table_name group by field having condition>1;#重复数大于1的数据
读取不重复数据
select distinct field1,field2 from table_name;
select field1,field2 from table_name group by (field...);
删除重复数据
create table temp select * form table_name group by (field...);#temp为中间的集合
drop table old_table_name;
alter table temp rename to old_table_name;
添加索引和主键删除重复记录
alter ignore table table_name add primary key(field...);
SQL注入
导出数据
select * from table_name into outfile 'address';
导入数据
第一种方式
mysql -u用户名 -p密码 < 要导入的数据库数据
第二种方式
create database new_database;
use new_database;
set names utf8;
source address;#address为要导入的数据库数据的地址
第三种方式
load data local infile 'file.txt' into table table_name;#local制定从当前主机上按路径读取