【C++】使用哈希表模拟实现STL中的unordered_set和unordered_map
文章目录
- 前言
- 一.哈希表模板改造+封装unordered_set和unordered_map
-
- 1. 哈希表结构修改
- 2. unordered_set和unordered_map增加KeyOfT仿函数
- 3. insert封装及测试
- 4. 哈希表迭代器的实现
- 5. begin和end
- 6. unordered_set和unordered_map的迭代器封装
- 7. unordered_map的[]重载
- 8. 补充完善:find、erase
- 9. 存储自定义类型元素
- 10. const迭代器的实现及unordered_set元素可以修改问题的解决
- 11. unordered_map const迭代器的封装
- 二. 源码
-
- 1. HashTable.h
- 2. UnorderedSet.h
- 3. UnorderedMap.h
- 4. Test.cpp
前言
前面的文章我们学习了unordered_set和unordered_map的使用以及哈希表,并且我们提到了unordered_set和unordered_map的底层结构其实就是哈希表。
那这篇文章我们就对之前我们实现的哈希表(拉链法实现的那个)进行一个改造,并用它模拟实现一下unordered_set和unordered_map。
那在模拟实现之前要声明一下:
我们这里的模拟实现里面所做的操作和前面红黑树模拟实现mapset基本上是一样的,增加和改造的那些模板参数的意义基本都是一样的。
所以这里有些地方我们就不会特别清楚的去说明了,如果某些地方大家看的不能太明白,建议先搞懂这篇文章——使用红黑树模拟实现STL中的map与set
这里面我们是讲的比较清楚的。
一.哈希表模板改造+封装unordered_set和unordered_map
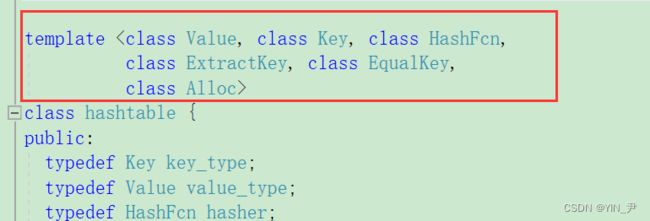
首先可以带大家再来简单看一下库里面的哈希表的源码:
我们来看一下这几个模板参数
第一个value就决定了哈希表里面每个data里面存的数据类型,第二个参数key就是用来获取单独的键值key,因为unordered_map进行查找这些操作的时候是用key进行散列的,需要比较的话也是用key,但他里面存的是pair。
第三个这个HashFcn就是接收一个仿函数,用来将比如字符串这些类型转换为整型的。
第四个的作用就和红黑树封装那里的KeyOfT一样,用来提取key的。
那我们先看这么多。
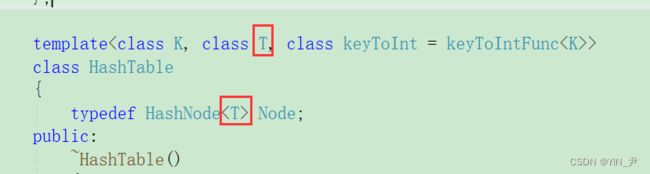
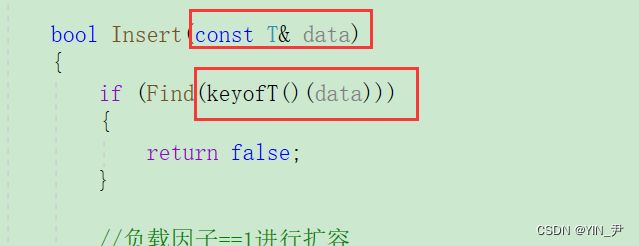
接下来我们对我们的拉链法的哈希表进行一些改造,因为我们当时是按照KV模型实现的,而现在要变成通用的。
1. 哈希表结构修改
首先结点的结构要改一下:
这样对于unordered_setT就是单独一个key,对于unordered_map就是一个pair。

然后哈希表的结构:
之前Node里面是KV,现在由T决定结点里面存什么
那下面相关的地方都要改一下
那大家看这个地方是不是就需要使用keyOfT那个仿函数了
因为data有可能是单独一个key,也有可能是一个pair,而像查找这些地方要使用Key去查找。
增加一个模板参数
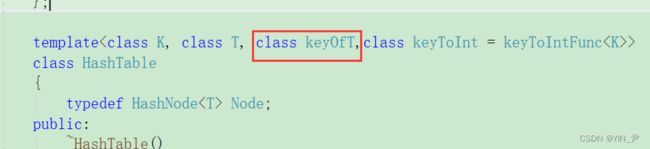
2. unordered_set和unordered_map增加KeyOfT仿函数
然后我们把unordered_set/map能写的先写一写:
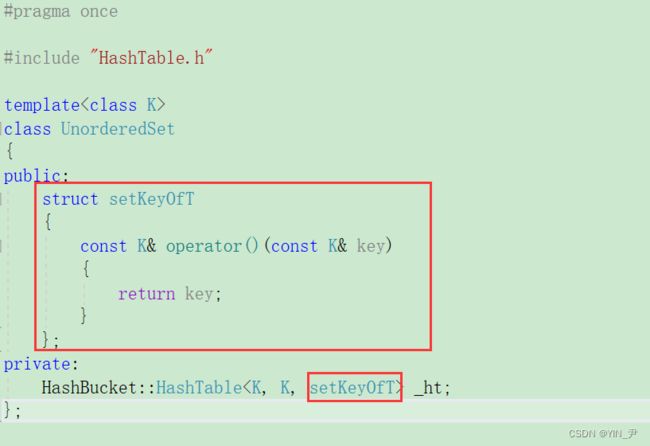
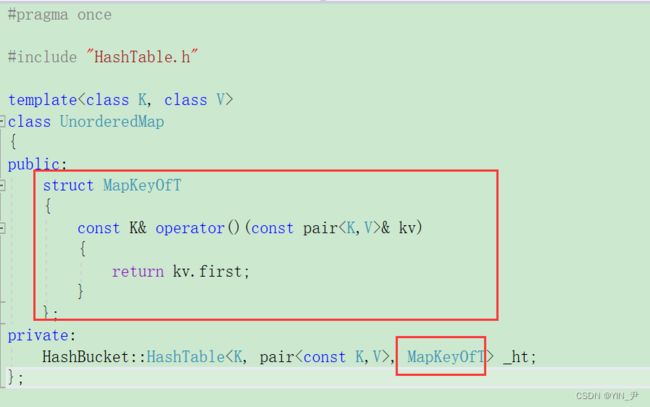
3. insert封装及测试
那我们先把insert搞一下,然后测试一下
unordered_map


测试一下:
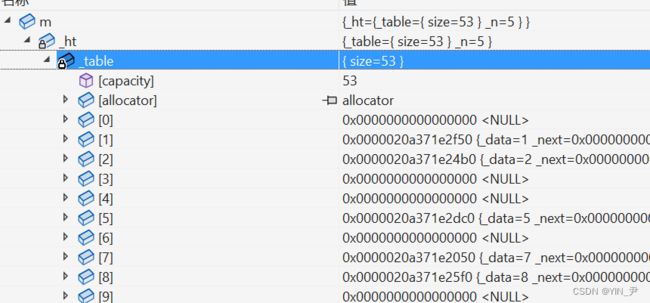
unordered_set的插入
没问题
然后,unordered_map的插入
没问题。
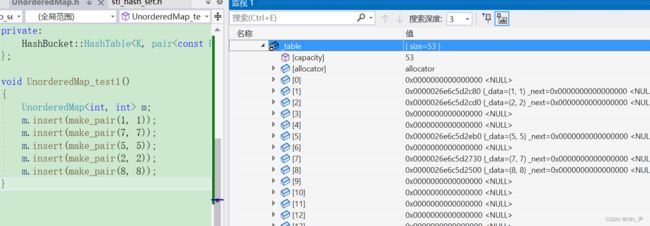
4. 哈希表迭代器的实现
接着我们来实现一下哈希表的迭代器
我们来思考一下它的迭代器应该怎么搞:
那按照我们以往的经验,它的迭代器应该还是对结点指针的封装,然后顺着每个不为空的哈希桶(链表)进行遍历就行了。
那大家思考一下:
比如现在底层的哈希表是这样的,it在2这个结点的位置。
那++it怎么走?
,其实很简单嘛,node->next不为空,就直接走到下一个结点就行了。
那如果为空呢?比如走到1002这个结点
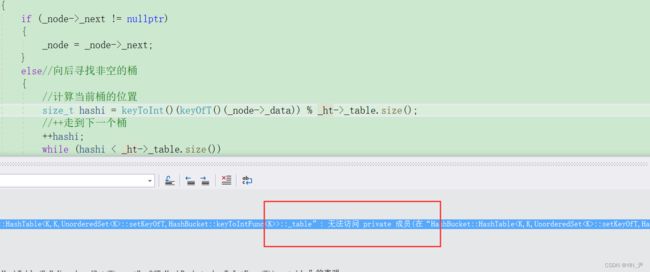
如果node->next为空,就说明当前这个桶遍历完了,所以就往后寻找下一个不为空的桶,然后it指向这个桶的第一个结点。
库里面其实也是这样搞的。
所以,对于哈希表的迭代器来说,还是结点指针的封装,但是还要包含另一个成员即哈希表。
因为我们遍历哈希表去依次找桶。
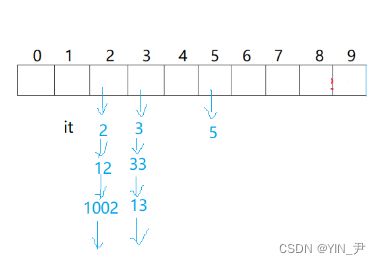
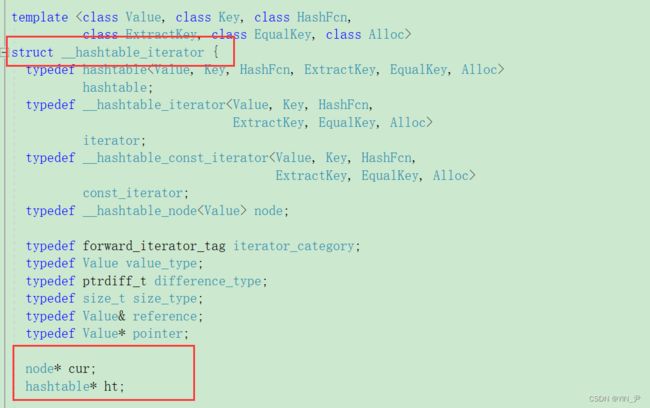
那我们自己来实现一下
先定义一下结构:

然后常用成员函数我们实现一下:
这些都没什么难度

然后++我们实现一下:
思路我们上面分析过了,来写一下代码

5. begin和end
迭代器搞的差不多,我们把begin和end搞一下
首先begin是返回第一个位置的迭代器,那第一个位置怎么找?
,是不是第一个非空的哈希桶的第一个结点啊
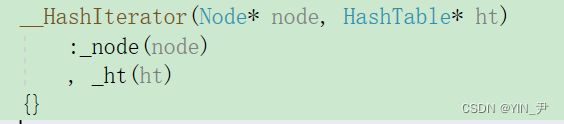
注意我们这里的迭代器的构造
是用结点的指针和表的指针,而this就是当前哈希表的指针。
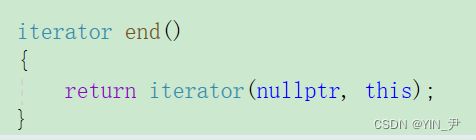
然后end用空构造就行了
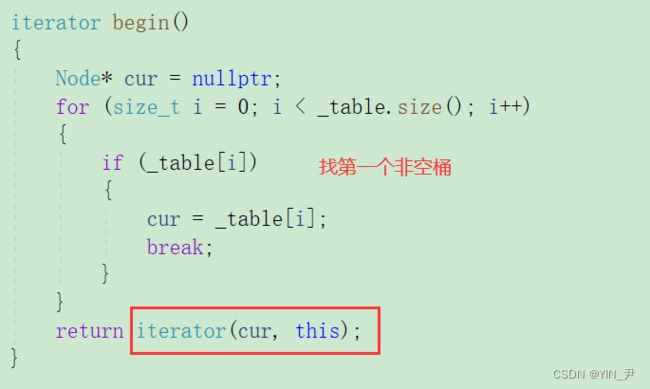
6. unordered_set和unordered_map的迭代器封装
那哈希表的迭代器实现好,我们就可以封装unordered_set和unordered_map的迭代器了
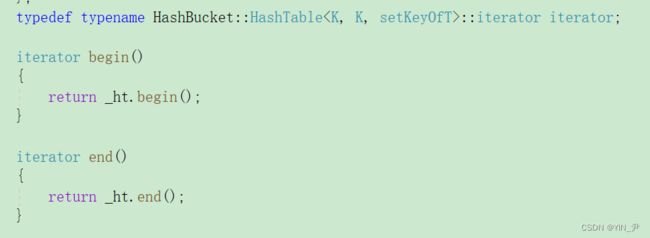
先来unordered_set:
来试一下
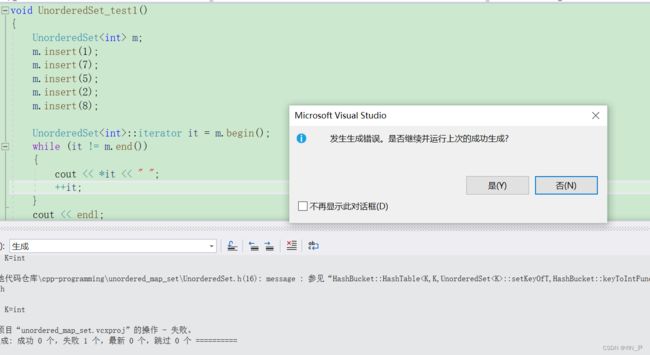
报了好多错误。
我们来解决一下:
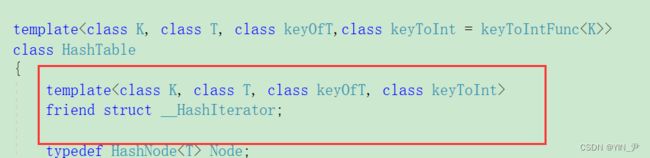
第一个迭代器的类里面无法访问私有成员_table
那解决方法呢我们可以写Get方法,当然这里也可以用友元解决。
那我们用一下友元吧
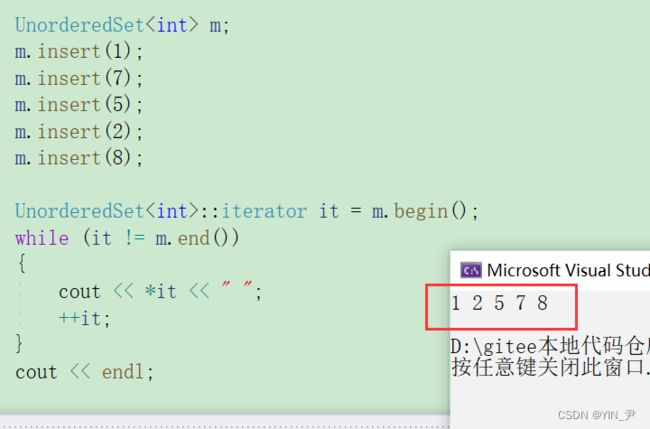
然后再运行
就可以了。
当然范围for肯定也支持了。
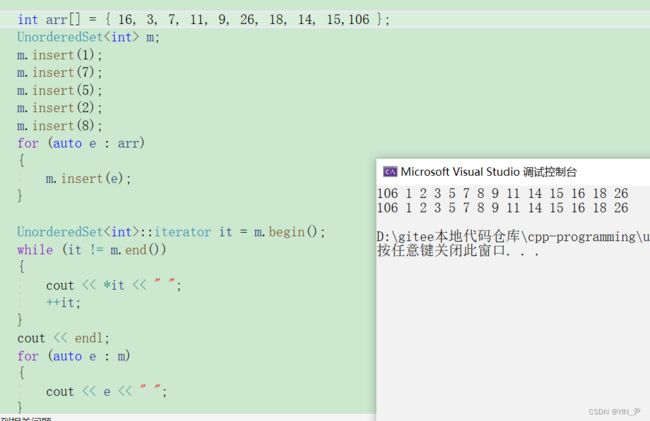
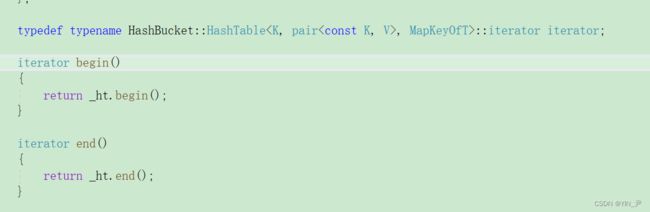
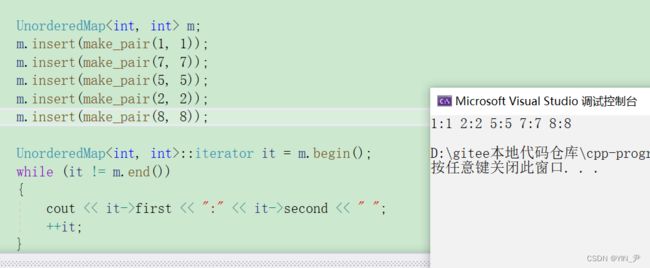
那unordered_set搞好了,unordered_map的迭代器我们也来封装一下:
来测试一下
没有问题。
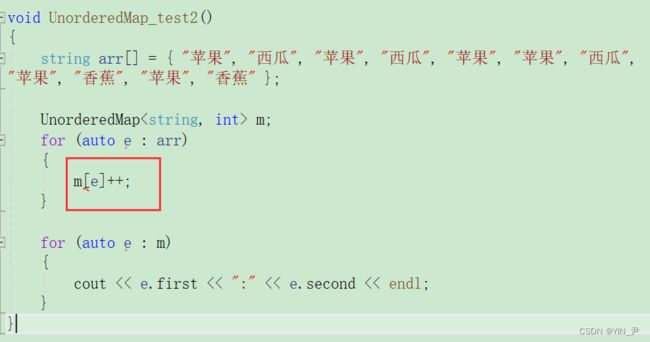
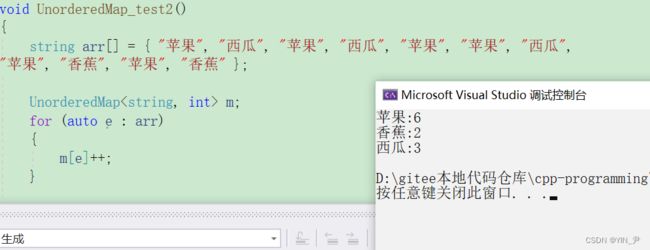
然后我们可以再用统计次数那个测试一下:
但是我们还没给unordered_map重载[]
7. unordered_map的[]重载
来写一下:
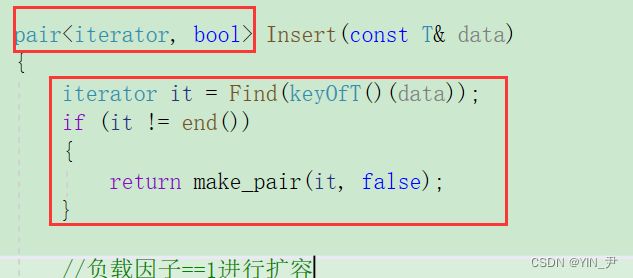
那通过前面的学习我们知道要实现[]的话,关键在于insert的返回值。
insert要返回一个pair
插入有成功和失败两种情况,因为键值不允许冗余;它返回的是一个pair,第一个模板参数为迭代器,第二个为bool。
当插入成功的时候,pair的first为指向新插入元素的迭代器,second为true,当插入失败的时候(其实就是插入的键已经存在了),那它的first为容器中已存在的那个相同的等效键元素的迭代器,second为false。
所以后面这个bool其实是标识插入成功还是失败。
这都是我们前面讲过的。
那我们前面实现的insert返回bool,所以我们要修改一下:
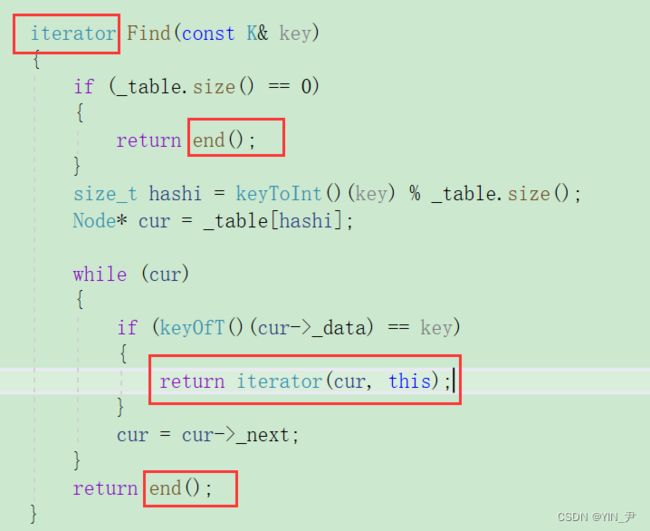
首先find我们先改一下,我们之前返回NOde*,现在应该返回对应位置的迭代器
然后insert返回一个pair
还有unordered_map/set里面的insert我们也改一下
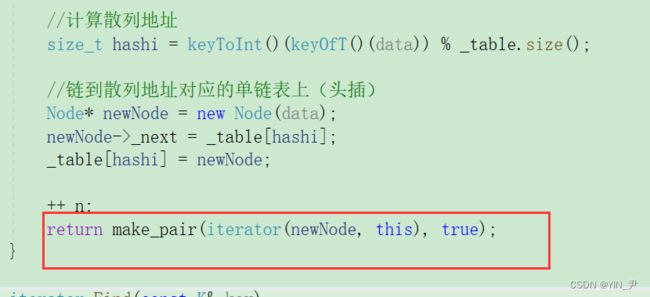


然后我们给unordered_map封装一个[]:

再来测试:
就可以了。
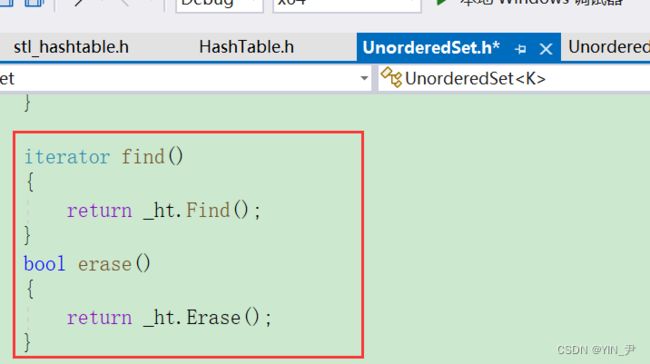
8. 补充完善:find、erase
unordered_set和unordered_map的find和erase我们也搞一下吧,其实就是套一层壳嘛:
9. 存储自定义类型元素
如果我们现在想让unordered_map里面的key为日期类
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
bool operator<(const Date& d)const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
friend ostream& operator<<(ostream& _cout, const Date& d);
private:
int _year;
int _month;
int _day;
};
ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
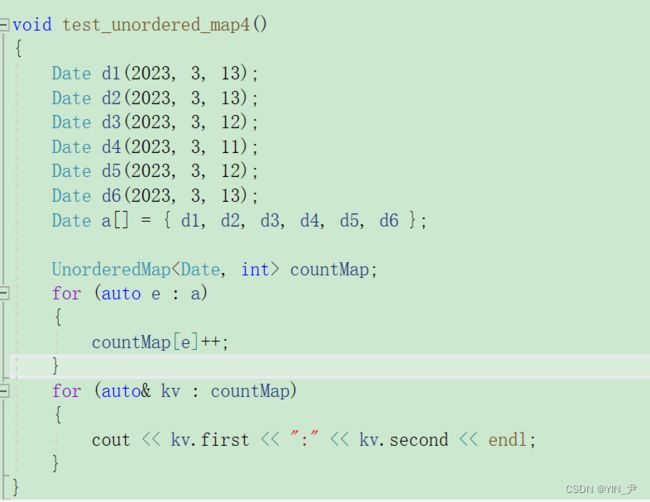
我们写这样一段代码:
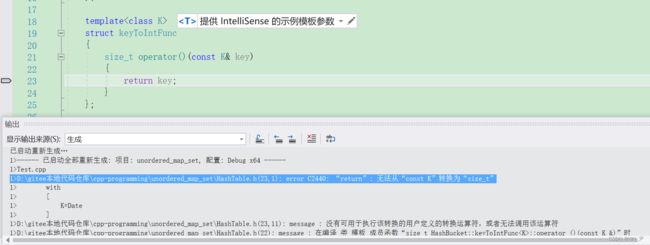
我们现在直接运行肯定是有问题的
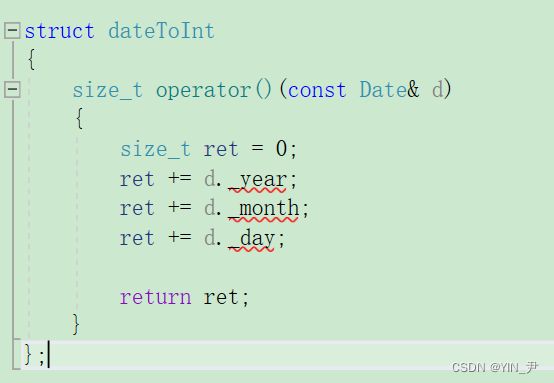
因为date类的数据无法转换成整型,所以我们要传那个keyToInt的仿函数。
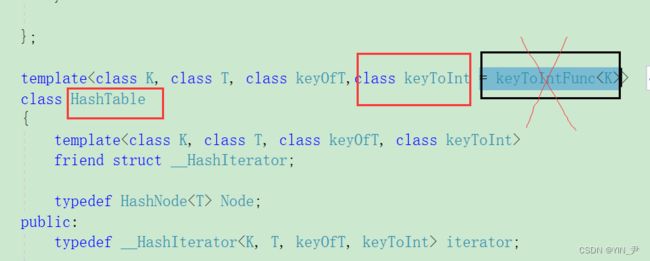
那我们的哈希表是有这个模板参数的,但是我们现在得给unordered_set和unordered_map增加这个模板参数:
那哈希表里面这个缺省参数我们就不用传了。
而是搞到unordered_set和unordered_map这里
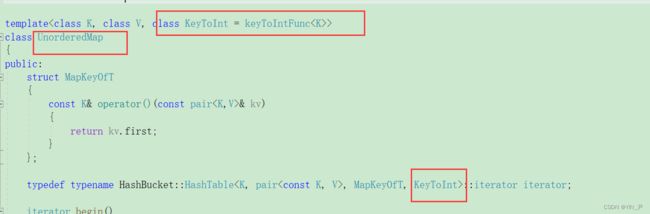

现在我们增加了这个模板参数,也有缺省值,但是对于date还是不行,因为它无法转换为整型,所以我们要自己写一个针对date类的仿函数:
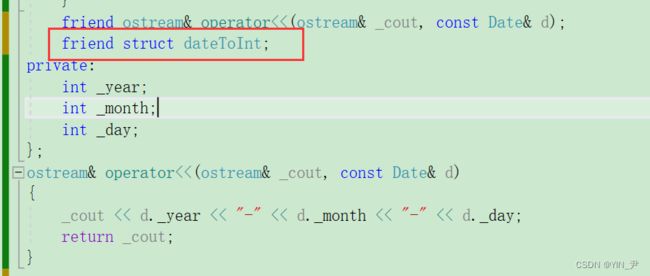
但是这里类外无法访问date的私有成员,那我们还用友元解决吧
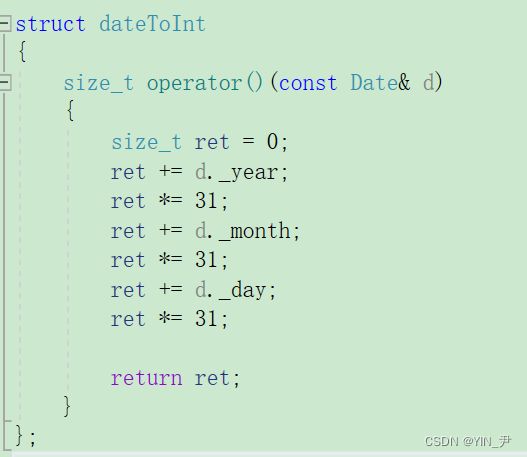
然后我们也可以用个BKDR哈希
然后我们再运行
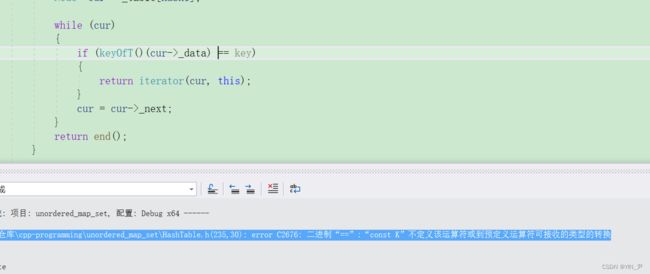
会发现这里又有一个报错。
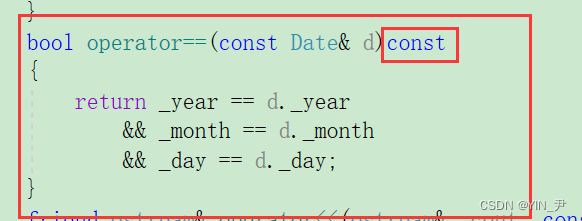
是因为我们的日期类没有重载==,我们加一下
然后再运行
就没问题了
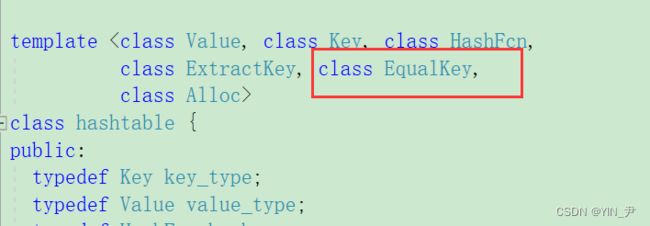
另外呢我们看到:
最开始的时候带大家看库里面的源码,它的哈希表还有一个模板参数我们没有介绍
就是这个EqualKey,他其实就是接收一个仿函数或函数指针去实现比较key是否相等的,必要的时候我们可以自己传。
我们这里没有用,因为这里的date类我们可以自己手动给它重载==,但是如果一个类不支持但是我们不能修改它或者某种类型的key可以比较==,但是不是我们想要的,比如date*,那像这种情况我们就可以写一个仿函数去传这个参数,不过我们这里没加。
10. const迭代器的实现及unordered_set元素可以修改问题的解决
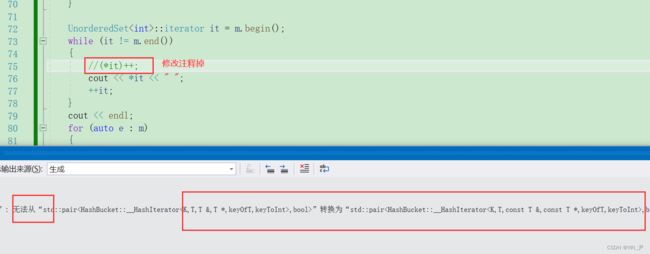
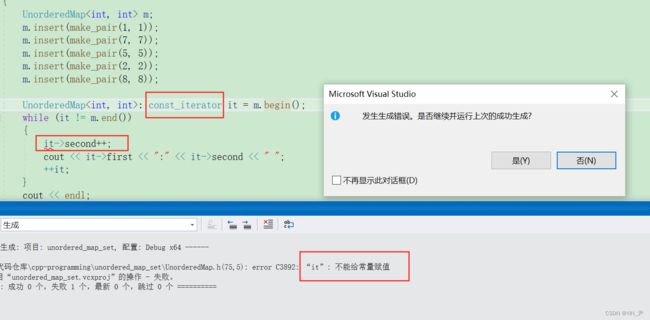
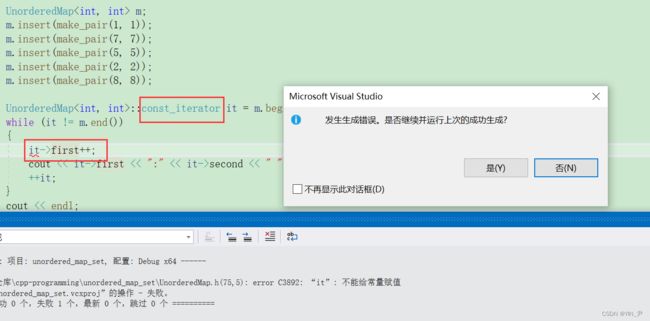
还有一个问题就是我们的unordered_set里面的元素现在是可以修改的,但是正常情况key是不能修改的,而且他是哈希函数里面的操作数,随意改散列就出问题了:
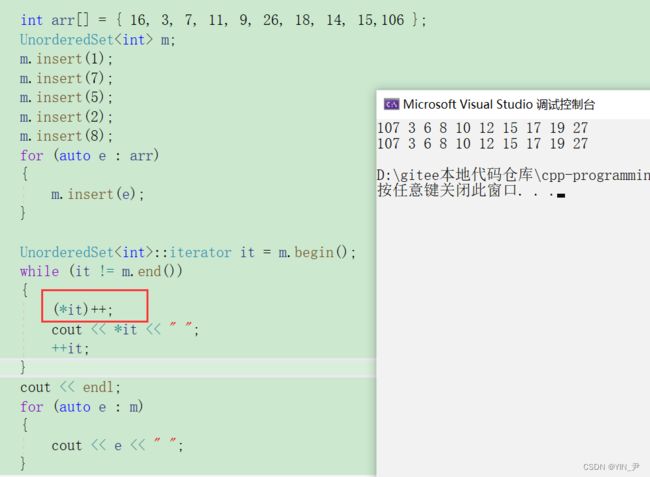
那我们来处理一下:
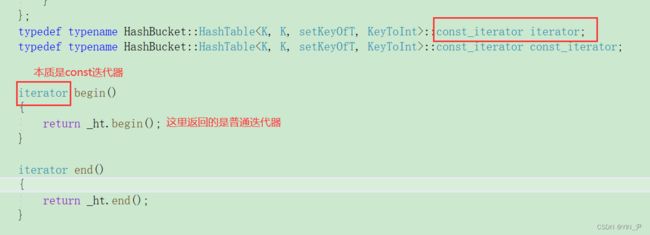
那其实解决方法和set那里是一样的,库里面也是一样的方法,让unordered_set的迭代器都是哈希表的const迭代器。
那首先我们得实现一下const迭代器:
先得给哈希表实现一下,还是之前的方法,通过增加两个模板参数
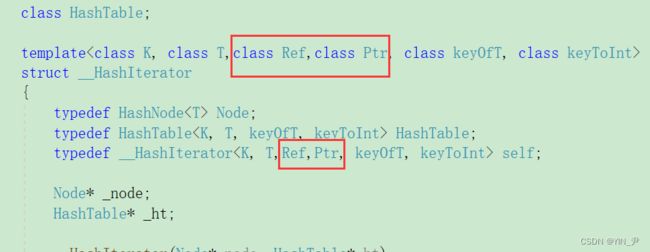

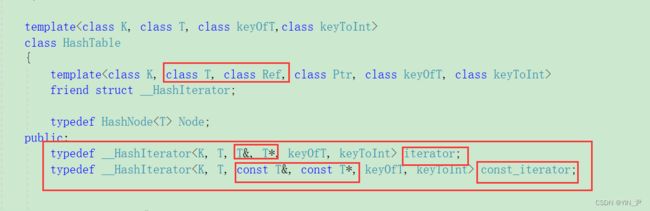
然后const版本的begin和end:

那然后我们把set的迭代器重新封装一下:
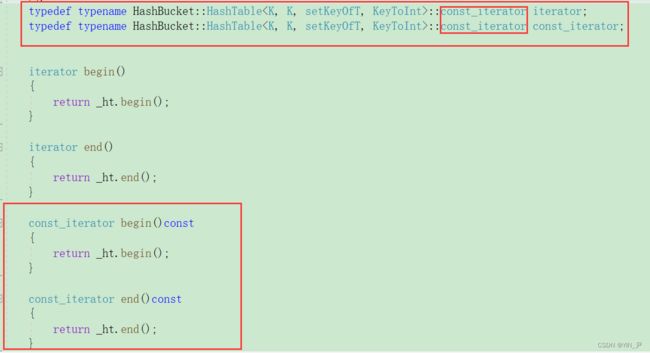
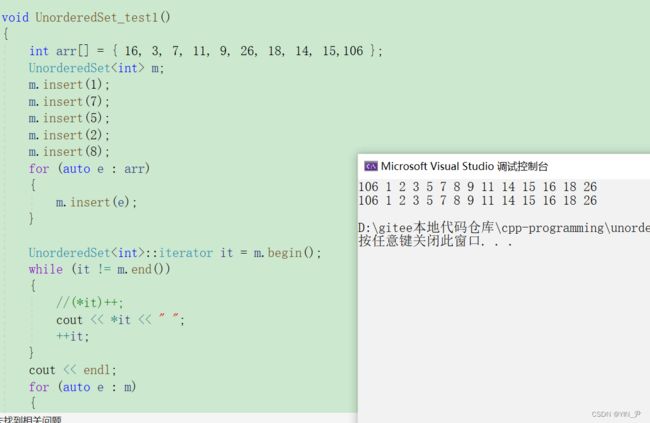
然后再运行:
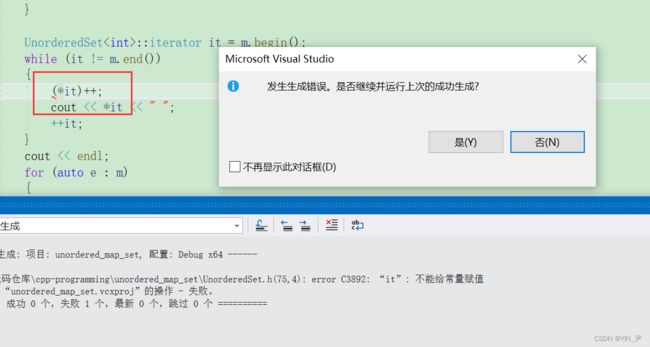
就不能修改了
但是
又有了新的问题。
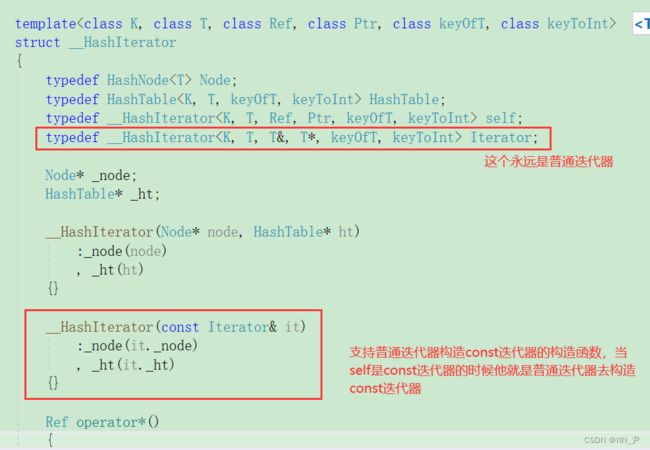
那这个问题其实还是跟我们之前封装mapset那里一样,因为这里不支持普通迭代器构造const迭代器
所以要解决的话加一个可以支持普通迭代器构造const迭代器的构造函数就行了
同样的方法
然后
就可以了。
如果大家有地方看不太懂的还是建议去看一下之前红黑树模拟实现map与set那里,那里讲的比较仔细,它们的逻辑是一样的。
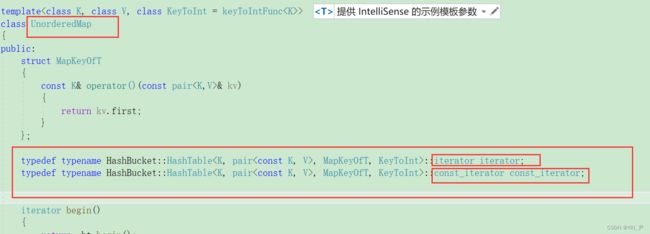
11. unordered_map const迭代器的封装
而对于unordered_map:
它的普通迭代器就是普通迭代器,const迭代器器就是const迭代器,区别在于value是否可以修改,而key是无论如何不能修改的
这个通过传模板参数就可以控制。

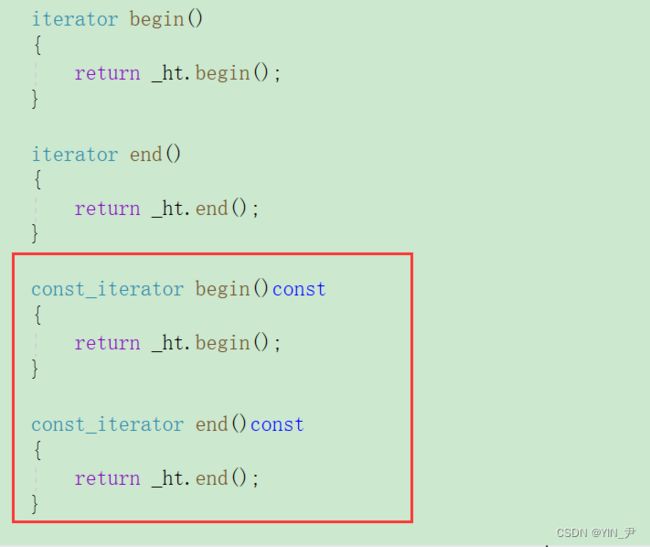
那我们把它的const迭代器也搞一下吧:
const版本的begin和end:
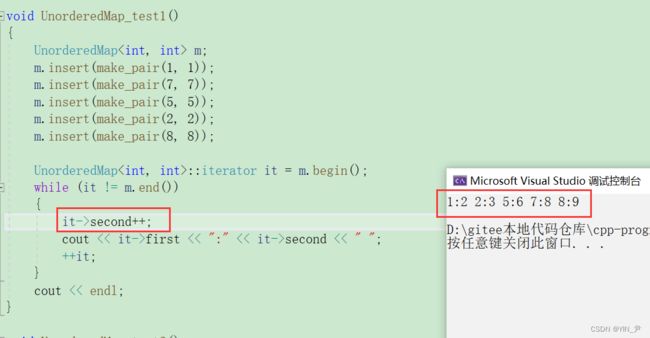
来试一下:
,我们看到普通迭代器可以修改value
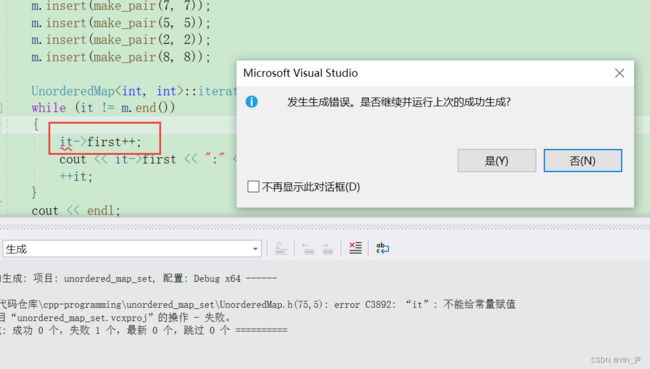
key是不行的。
如果换成const迭代器,value也不能修改。
key肯定依然不能修改。
二. 源码
1. HashTable.h
#pragma once
#include 2. UnorderedSet.h
#pragma once
#include "HashTable.h"
template<class K, class KeyToInt = keyToIntFunc<K>>
class UnorderedSet
{
public:
struct setKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
typedef typename HashBucket::HashTable<K, K, setKeyOfT, KeyToInt>::const_iterator iterator;
typedef typename HashBucket::HashTable<K, K, setKeyOfT, KeyToInt>::const_iterator const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin()const
{
return _ht.begin();
}
const_iterator end()const
{
return _ht.end();
}
pair<iterator,bool> insert(const K& key)
{
return _ht.Insert(key);
}
iterator find()
{
return _ht.Find();
}
bool erase()
{
return _ht.Erase();
}
private:
HashBucket::HashTable<K, K, setKeyOfT, KeyToInt> _ht;
};
void UnorderedSet_test1()
{
int arr[] = { 16, 3, 7, 11, 9, 26, 18, 14, 15,106 };
UnorderedSet<int> m;
m.insert(1);
m.insert(7);
m.insert(5);
m.insert(2);
m.insert(8);
for (auto e : arr)
{
m.insert(e);
}
UnorderedSet<int>::iterator it = m.begin();
while (it != m.end())
{
//(*it)++;
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : m)
{
cout << e << " ";
}
cout << endl;
}
3. UnorderedMap.h
#pragma once
#include "HashTable.h"
template<class K, class V, class KeyToInt = keyToIntFunc<K>>
class UnorderedMap
{
public:
struct MapKeyOfT
{
const K& operator()(const pair<K,V>& kv)
{
return kv.first;
}
};
typedef typename HashBucket::HashTable<K, pair<const K, V>, MapKeyOfT, KeyToInt>::iterator iterator;
typedef typename HashBucket::HashTable<K, pair<const K, V>, MapKeyOfT, KeyToInt>::const_iterator const_iterator;
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
const_iterator begin()const
{
return _ht.begin();
}
const_iterator end()const
{
return _ht.end();
}
pair<iterator,bool> insert(const pair<K,V>& kv)
{
return _ht.Insert(kv);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
iterator find()
{
return _ht.Find();
}
bool erase()
{
return _ht.Erase();
}
private:
HashBucket::HashTable<K, pair<const K,V>, MapKeyOfT, KeyToInt> _ht;
};
void UnorderedMap_test1()
{
UnorderedMap<int, int> m;
m.insert(make_pair(1, 1));
m.insert(make_pair(7, 7));
m.insert(make_pair(5, 5));
m.insert(make_pair(2, 2));
m.insert(make_pair(8, 8));
UnorderedMap<int, int>::const_iterator it = m.begin();
while (it != m.end())
{
//it->first++;
cout << it->first << ":" << it->second << " ";
++it;
}
cout << endl;
}
void UnorderedMap_test2()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜",
"苹果", "香蕉", "苹果", "香蕉" };
UnorderedMap<string, int> m;
for (auto e : arr)
{
m[e]++;
}
for (auto e : m)
{
cout << e.first << ":" << e.second << endl;
}
}
class Date
{
public:
Date(int year = 1900, int month = 1, int day = 1)
: _year(year)
, _month(month)
, _day(day)
{}
bool operator<(const Date& d)const
{
return (_year < d._year) ||
(_year == d._year && _month < d._month) ||
(_year == d._year && _month == d._month && _day < d._day);
}
bool operator>(const Date& d)const
{
return (_year > d._year) ||
(_year == d._year && _month > d._month) ||
(_year == d._year && _month == d._month && _day > d._day);
}
bool operator==(const Date& d)const
{
return _year == d._year
&& _month == d._month
&& _day == d._day;
}
friend ostream& operator<<(ostream& _cout, const Date& d);
friend struct dateToInt;
private:
int _year;
int _month;
int _day;
};
ostream& operator<<(ostream& _cout, const Date& d)
{
_cout << d._year << "-" << d._month << "-" << d._day;
return _cout;
}
struct dateToInt
{
size_t operator()(const Date& d)
{
size_t ret = 0;
ret += d._year;
ret *= 31;
ret += d._month;
ret *= 31;
ret += d._day;
ret *= 31;
return ret;
}
};
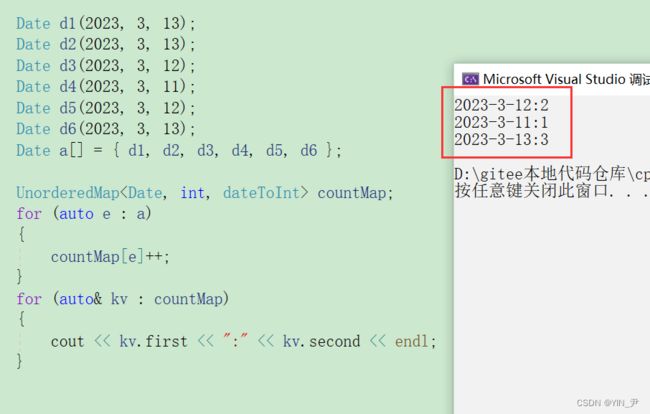
void UnorderedMap_test3()
{
Date d1(2023, 3, 13);
Date d2(2023, 3, 13);
Date d3(2023, 3, 12);
Date d4(2023, 3, 11);
Date d5(2023, 3, 12);
Date d6(2023, 3, 13);
Date a[] = { d1, d2, d3, d4, d5, d6 };
UnorderedMap<Date, int, dateToInt> countMap;
for (auto e : a)
{
countMap[e]++;
}
for (auto& kv : countMap)
{
cout << kv.first << ":" << kv.second << endl;
}
}
4. Test.cpp
#define _CRT_SECURE_NO_WARNINGS
#include 