Spark Streaming任务中的容错机制盘点
前言
互联网场景下,经常会有各种实时的数据处理,这种处理方式也就是流式计算,延迟通常也在毫秒级或者秒级,比较有代表性的几个开源框架,分别是Storm,Spark Streaming和Filnk。
刚好最近我负责一个实时流计算的项目,由于对接Spark比较方便,所以采用的是Spark Steaming。在处理流式数据的时候使用的数据源搭档是kafka,这在互联网公司中比较常见。由于存在一些不可预料的外界因素的故障,比如断电,系统故障,或者JVM崩溃等,Spark Streaming需要一套容错机制,以便能任务失败的时候能及时恢复(特别是前后依赖关系的数据,长时间数据中断会导致计算结果出错)。
对于使用kafka作数据源搭档的SparkStreaming任务目前有两种方式保证数据不丢失:
1)自己维护kafka偏移量
2)使用checkpoint
接下来的篇幅介绍这两种方式的原理以及如何使用
使用Checkpoint从中断处恢复任务
checkpoint是使用spark streaming自带的一种容错机制,由于checkpoint实践中会涉及到一些Streaming Contex关键组件,所以在介绍checkpoint原理前有必要先了解Streaming Context关键组件。下图是Streaming Context关键组件的结构图。

DstreamGraph:表示各个Dstream之间的依赖关系
JobGenerator:根据DstreamGraph定义的算子和各个Dstream之间的依赖关系去生成一个job
JobScheduler:调度job,底层走的逻辑,跟离线job一样
ReceiverTracker:获取一次时间间隔内的数据信息
checkpoint生成
checkpoint任务从产生到实现,全部流程靠事件队列中的消息触发牵引。消息处理逻辑负责处理如下事件消息,详见下面processEvent的源代码。
private def processEvent(event: JobGeneratorEvent) {
logDebug("Got event " + event)
event match {
case GenerateJobs(time) => generateJobs(time)
case ClearMetadata(time) => clearMetadata(time)
case DoCheckpoint(time, clearCheckpointDataLater) =>
doCheckpoint(time, clearCheckpointDataLater)
case ClearCheckpointData(time) => clearCheckpointData(time)
}
}
checkpoint执行前需要生成一个任务,jobGenerator通过一个定时器来定期触发每个批次任务的生成,即每个批次会往事件处理队列中发布一个GenerateJobs的任务完成jobs的生成。jobs生成成功即可通过submitJobSet来进行任务提交,然后会往eventLoop事件队列中发布一个DoCheckpoint的事件。具体实现可以看下面generateJobs源代码。
private def generateJobs(time: Time) {
ssc.sparkContext.setLocalProperty(RDD.CHECKPOINT_ALL_MARKED_ANCESTORS, "true")
Try {
jobScheduler.receiverTracker.allocateBlocksToBatch(time) // allocate received blocks to batch
graph.generateJobs(time) // 生成jobs,通过time来定位需要处理的block
} match {
case Success(jobs) => // jobs生成成功
val streamIdToInputInfos = jobScheduler.inputInfoTracker.getInfo(time)
jobScheduler.submitJobSet(JobSet(time, jobs, streamIdToInputInfos)) // 提交jobs进行处理
case Failure(e) =>
jobScheduler.reportError("Error generating jobs for time " + time, e)
PythonDStream.stopStreamingContextIfPythonProcessIsDead(e)
}
eventLoop.post(DoCheckpoint(time, clearCheckpointDataLater = false))
}
如果当前任务中设置了使用checkpoint,且当前批次时间满足设置的checkpoint时间则可对DoCheckpoint的事件进行处理。处理时会先调用DStreamGraph的updateCheckpointData,然后才是将checkpoint的执行对象写入外存(这部分后面有介绍),具体逻辑可以参考doCheckpoint源码。
private def doCheckpoint(time: Time, clearCheckpointDataLater: Boolean) {
// 先判断是否设置了checkpoint,然后判断当前批次时间是否满足设置的checkpoint时间(官方推荐的设置checkpoint频率是5-10个批次执行一次)
if (shouldCheckpoint && (time - graph.zeroTime).isMultipleOf(ssc.checkpointDuration)) {
logInfo("Checkpointing graph for time " + time)
ssc.graph.updateCheckpointData(time)
checkpointWriter.write(new Checkpoint(ssc, time), clearCheckpointDataLater)
} else if (clearCheckpointDataLater) { // 不满足checkpoint设置的时间间隔,记录最近一次批处理的时间
markBatchFullyProcessed(time)
}
}
updateCheckpointData是DStreamGraph中的操作,实现了对DAG中的每一个outputStream的备份操作,同时斩断进行checkpoint操作的rdd和DAG链路上的上游DStream/rdd的关系。这部分操作可以参考DStreamGraph.scala和DStream.scala源码。
def updateCheckpointData(time: Time) {
logInfo("Updating checkpoint data for time " + time)
this.synchronized {
outputStreams.foreach(_.updateCheckpointData(time))
}
logInfo("Updated checkpoint data for time " + time)
}
private[streaming] def updateCheckpointData(currentTime: Time) {
logDebug(s"Updating checkpoint data for time $currentTime")
checkpointData.update(currentTime)
dependencies.foreach(_.updateCheckpointData(currentTime))
logDebug(s"Updated checkpoint data for time $currentTime: $checkpointData")
}
更进一步,如果我们想知道每一个outputStream中备份的数据,详情可见DStreamCheckpointData。备份数据包括持久化数据名称,构建时间戳。
private[streaming]
class DStreamCheckpointData[T: ClassTag](dstream: DStream[T])
extends Serializable with Logging {
protected val data = new HashMap[Time, AnyRef]()
// 每个批次checkpoint到外部系统中的rdd对应文件的文件名
@transient private var timeToCheckpointFile = new HashMap[Time, String]
// 记录每个批次checkpoint存储的rdd数据中最早的数据时间
@transient private var timeToOldestCheckpointFileTime = new HashMap[Time, Time]
@transient private var fileSystem: FileSystem = null
protected[streaming] def currentCheckpointFiles = data.asInstanceOf[HashMap[Time, String]]
...
而在对接kafka数据源时,DirectKafkaInputDStream重写checkpointData的update等接口,它能把正在运行的kafkaRDD对应的topic,partition,fromoffset,untiloffset全部存储到checkpointData里面data这个HashMap的属性当中,用于写checkpoint时进行序列化。具体实现可以参考DirectKafkaInputDStreamCheckpointData。
class DirectKafkaInputDStreamCheckpointData extends DStreamCheckpointData(this) {
def batchForTime: mutable.HashMap[Time, Array[(String, Int, Long, Long)]] = {
data.asInstanceOf[mutable.HashMap[Time, Array[OffsetRange.OffsetRangeTuple]]]
}
override def update(time: Time): Unit = {
batchForTime.clear()
generatedRDDs.foreach { kv =>
val a = kv._2.asInstanceOf[KafkaRDD[K, V]].offsetRanges.map(_.toTuple).toArray
batchForTime += kv._1 -> a
}
}
override def cleanup(time: Time): Unit = { }
override def restore(): Unit = {
batchForTime.toSeq.sortBy(_._1)(Time.ordering).foreach { case (t, b) =>
logInfo(s"Restoring KafkaRDD for time $t ${b.mkString("[", ", ", "]")}")
generatedRDDs += t -> new KafkaRDD[K, V](
context.sparkContext,
executorKafkaParams,
b.map(OffsetRange(_)),
getPreferredHosts,
// during restore, it's possible same partition will be consumed from multiple
// threads, so dont use cache
false
)
}
}
}
做完CheckpointData数据备份后即可将checkpoint数据写入外存。通过Checkpoint.CheckpointWriter内部类的write方法即可实现Checkpoint对象写入。
def write(checkpoint: Checkpoint, clearCheckpointDataLater: Boolean) {
try {
val bytes = Checkpoint.serialize(checkpoint, conf)
executor.execute(new CheckpointWriteHandler(
checkpoint.checkpointTime, bytes, clearCheckpointDataLater))
logInfo(s"Submitted checkpoint of time ${checkpoint.checkpointTime} to writer queue")
} catch {
case rej: RejectedExecutionException =>
logError("Could not submit checkpoint task to the thread pool executor", rej)
}
}
被序列化的Checkpoint对象封装的数据字段:
private[streaming]
class Checkpoint(ssc: StreamingContext, val checkpointTime: Time)
extends Logging with Serializable {
val master = ssc.sc.master
val framework = ssc.sc.appName
val jars = ssc.sc.jars
val graph = ssc.graph
val checkpointDir = ssc.checkpointDir
val checkpointDuration = ssc.checkpointDuration
val pendingTimes = ssc.scheduler.getPendingTimes().toArray
val sparkConfPairs = ssc.conf.getAll
从checkpoint恢复服务
使用StreamingContext.getOrCreate方法进行初始化,在CheckpointReader.read找到checkpoint文件并且成功反序列化出checkpoint对象。如果程序是第一次启动会通过createContext初始化StreamingContext,否则createContext不被调用,任务会使用反序列化checkpoint对象的StreamingContext。下面的源代码是getOrCreate读取checkpoint对象的源码。
def getOrCreate(
checkpointPath: String,
creatingFunc: () => StreamingContext,
hadoopConf: Configuration = SparkHadoopUtil.get.conf,
createOnError: Boolean = false
): StreamingContext = {
val checkpointOption = CheckpointReader.read(
checkpointPath, new SparkConf(), hadoopConf, createOnError)
checkpointOption.map(new StreamingContext(null, _, null)).getOrElse(creatingFunc())
}
def read(
checkpointDir: String,
conf: SparkConf,
hadoopConf: Configuration,
ignoreReadError: Boolean = false): Option[Checkpoint] = {
val checkpointPath = new Path(checkpointDir)
val fs = checkpointPath.getFileSystem(hadoopConf)
在checkpoint恢复的过程中恢复DStreamGraph,接下来向消息队列发送各种事件信息,后续流程与生成chekpoint一样。最后,在restart的过程中,JobGenerator通过当前时间和上次程序停止的时间计算出程序重启过程中共有多少batch没有生成,加上上一次程序死掉的过程中有多少正在运行的job,全部进行Reschedule,补跑任务。
checkpoint实践
基于业务,给定一个checkpoint实践样例:
def startStreamingContext(self, timeWindow, consumerName, topicName, checkpointDirectory):
"""
streaming初始化配置
:param timeWindow: 每一批数据的时间间隔
:param consumerName:
:param topicName:
:param checkpointDirectory:
:return:
"""
def functionToCreateContext():
context = StreamingContext(self.sc, timeWindow)
context.checkpoint(checkpointDirectory)
return context
print("[INFO] run startStreamingContext")
_zkQuorum = 'localhost1:2181,localhost2:2181' # 1.0版kafka
self.ssc = StreamingContext(self.sc, timeWindow).getOrCreate(checkpointDirectory, functionToCreateContext)
topicStream = KafkaUtils.createStream(self.ssc, _zkQuorum,
consumerName, {topicName: 12})
topicStream.checkpoint(timeWindow * 6) # 定时持久checkpoint到hdfs上(推荐时间为batch duration 的5~10倍)
self.lines_topic = topicStream.map(lambda x: x[1])
return self.ssc, self.lines_topic
# 启动Streaming任务
checkpointDirectory = "hdfs://cluster/spark/checkpoint/test"
ssc, lines_event = s.startStreamingContext(timeWindow, event_usedconsumer, topic_usedevent, checkpointDirectory)
lines_event.foreachRDD(process_batch)
ssc.start()
ssc.awaitTermination()
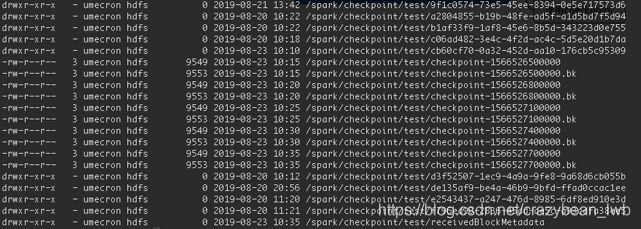
checkpoint任务启动后即可以从外存上(例如hdfs)看到checkpoint Metadata信息:
• Configuration(配置信息) : 创建streaming应用程序的配置信息
• Dstream operations : 在streaming应用程序中定义的DStreaming操作
• Incomplete batches : 在队列中没有处理完的作业
如下图所示:
checkpoint弊端
• 每次更新迭代代码后重启工程会报错
checkpoint的元数据会记录jar的序列化的二进制文件,修改代码、重新编译,新的序列化jar文件,在checkpoint的记录中并不存在,所以就导致了上述错误
解决:
删除checkpoint开头的的文件即可,不影响数据本身的checkpoint
hadoop fs -rm /spark/checkpoint/test/checkpoint-*
• 每隔固定时间都要向HDFS上写入checkpoint数据,会造成checkpointDirectory下小文件较多
由于ckeckpoint存在一些弊端,所以接下来的篇幅会介绍一些候选方案,候选方案结合具体的场景能带来比较符合预期的效果。
使用ZooKeeper存储偏移量
Spark用户在直接使用kafka消费者api时是没有执行更新offset操作的,如果当前任务中断后,重启任务消费者 将会从队列的末尾消费,导致消费数据的丢失。zookeeper不仅是基于分布式的高可靠文件系统,而且特别适合记录存储记录偏移量信息。接下来介绍zookeeper如何保证streaming任务的容错。
spark streaming中集成的kafka获取数据有Receiver和Direct两种方式,其中Receiver方式使用zookeeper连接kafka队列同时实现offset信息更新。Received使用Kafka高级Consumer API实现,从Kafka通过Receiver接收的数据存储在Spark Executor的内存中,然后由Spark Streaming启动的job来处理数据,而预写日志(Write Ahead Log, WAL)机制会同步地将接收到的Kafka数据保存到分布式文件系统(比如HDFS)上的预写日志中,以便在系统出错时恢复数据、确保零数据丢失。下图是Receiver方式下spark streaming的工作流程原理。

下面是Receiver方式下使用Zookeeper托管消费者offset代码实践:
def startStreamingContext(self, timeWindow, consumerName, topicName):
"""
streaming初始化配置
:param timeWindow: 每一批数据的时间间隔
:param consumerName:
:param topicName:
:return:
"""
print("[INFO] run startStreamingContext")
_zkQuorum = 'localhost1:2181,localhost2:2181' # 1.0版kafka
self.ssc = StreamingContext(self.sc, timeWindow)
topicStream = KafkaUtils.createStream(self.ssc, _zkQuorum, consumerName, {topicName: 12})
self.lines_topic = topicStream.map(lambda x: x[1])
return self.ssc, self.lines_topic
ssc, lines_event = s.startStreamingContext(timeWindow, event_usedconsumer, topic_usedevent)
lines_event.foreachRDD(process_batch)
ssc.start()
ssc.awaitTermination()
使用Zookeeper托管offset的方式简单方便,但是容错效果依然存疑,接下来针对这个问题特意做了一个任务中断实验。实验结果可以参考下图:
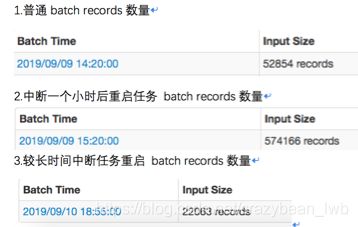
• 短时间中断,能从断点offset处重启任务
• 超过一定数据量或时间offset将置为最新
结论:
在任务中断的一段时间内Zookeeper能保留中断处kafka的offset信息(与Zookeeper的管理机制有关,主要目的是为了节省数据占用磁盘空间),当然在现有的任务监控机制下能及时发现异常任务或者中断任务,所以用Zookeeper托管的方式能满足任务容错的需求。当出现兼容任务较长时间中断的需求时,使用Zookeeper托管就不是一个好的容错方案。接下来的篇幅介绍能解决任务长时间中断的容错机制。
自行维护kafka偏移量
接下来介绍的几种自行维护kafka偏移量的方法都是基于spark streaming的另一种名为Direct接收kafka数据的方法,所以在此先介绍Direct接收方式的原理。
Direct方式自Spark 1.3引入旨在确保更健壮的机制。这种方式会周期性地查询Kafka,来获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。下图是Direct方式下spark streaming的工作流程原理。
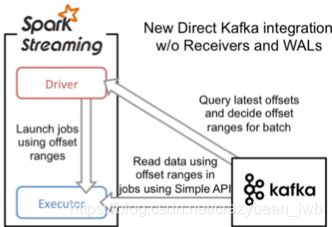
相对Receiver方式,Direct方式有如下优势:
• 创建跟Kafka partition一样多的RDD partition,并且会并行从Kafka中读取数据
• 不需要预写日志机制,能直接从kafka中做数据恢复
• 自动追踪消费的offset并保存在checkpoint,且数据仅消费一次
下面是Direct方式下spark streaming自行追踪消费者offset代码并存checkpoint实践:
def startStreamingContext(self, timeWindow, topicName, checkpointDirectory):
"""
streaming初始化配置
:param timeWindow:
:param topicName:
:param checkpointDirectory:
:return:
"""
def functionToCreateContext():
context = StreamingContext(self.sc, timeWindow)
context.checkpoint(checkpointDirectory)
return context
print("[INFO] run startStreamingContext")
brokers = "localhost1:9092,localhost2:9092" # Partitions by Broker
self.ssc = StreamingContext(self.sc, timeWindow).getOrCreate(checkpointDirectory, functionToCreateContext)
topicStream = KafkaUtils.createDirectStream(self.ssc, [topicName],
kafkaParams={"metadata.broker.list": brokers})
topicStream.checkpoint(timeWindow * 6) # 定时持久checkpoint到hdfs上(推荐时间为batch duration 的5~10倍)
self.lines_topic = topicStream.map(lambda x: x[1])
return self.ssc, self.lines_topic
# 启动Streaming任务
checkpointDirectory = "hdfs://cluster/spark/checkpoint/test"
ssc, lines_event = s.startStreamingContext(timeWindow, event_usedconsumer, topic_usedevent, checkpointDirectory)
lines_event.foreachRDD(process_batch)
ssc.start()
ssc.awaitTermination()
在Direct方式下也可以使用zookeeper记录消费的offset,但是zookeeper不能自动更新offset状态,需要手动维护消费的offset并将offset存入zookeeper。下面是该种方式的实践:
ZOOKEEPER_SERVERS = "localhost1:2181" # 先定义好记录使用的zookeeper
def get_zookeeper_instance():
from kazoo.client import KazooClient
if 'KazooSingletonInstance' not in globals():
globals()['KazooSingletonInstance'] = KazooClient(ZOOKEEPER_SERVERS)
globals()['KazooSingletonInstance'].start()
return globals()['KazooSingletonInstance']
def read_offsets(zk, topics):
from pyspark.streaming.kafka import TopicAndPartition
from_offsets = {}
for topic in topics:
for partition in zk.get_children(f'/consumers/{topic}'):
topic_partion = TopicAndPartition(topic, int(partition))
offset = int(zk.get(f'/consumers/{topic}/{partition}')[0])
from_offsets[topic_partion] = offset
return from_offsets
def save_offsets(rdd):
zk = get_zookeeper_instance()
for offset in rdd.offsetRanges(): #rdd -->partition唯一映射,记录每一个partition的offset信息
path = f"/consumers/{offset.topic}/{offset.partition}"
zk.ensure_path(path)
zk.set(path, str(offset.untilOffset).encode())
def main(brokers="localhost1:9092", topics=['test1', 'test2']):
sc = SparkContext(appName="PythonStreamingSaveOffsets")
ssc = StreamingContext(sc, 2)
zk = get_zookeeper_instance()
from_offsets = read_offsets(zk, topics) # 读取topic下各partition的offset信息
directKafkaStream = KafkaUtils.createDirectStream(
ssc, topics, {"metadata.broker.list": brokers},
fromOffsets=from_offsets) # 以Direct方式访问Kafka
directKafkaStream.transform(save_offsets).foreachRDD(process_batch) # 先存partitions的offsets,再处理业务逻辑
Direct方式下除了以上2种维护offset的方法,也可以采用数据库存储记录offset,由于python的实现没有实现,在此借鉴一篇scala的实践的思路供大家参考:
代码思路:
- 代码第一次执行时直接读取mysql的offset信息
- Direct方式读取当前kafka的offset
- 比较2个offset的大小,如果mysql中的offset小于当前kafka的offset则取mysql中的offset作为当前的offset
- 非第一次执行则直接取kafka的offset即可
- 每读取一个批次的数据更新一次offset到mysql数据库
import kafka.common.TopicAndPartition
import kafka.message.MessageAndMetadata
import kafka.serializer.StringDecoder
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.InputDStream
import org.apache.spark.streaming.kafka.KafkaCluster.Err
import org.apache.spark.streaming.kafka.{HasOffsetRanges, KafkaCluster, KafkaUtils, OffsetRange}
import org.apache.spark.streaming.{Duration, StreamingContext}
import scalikejdbc.{DB, SQL}
import scalikejdbc.config.DBs
/*
将偏移量保存到MySQL中
*/
object SparkStreamingOffsetMySql {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("medd").setMaster("local[2]")
val ssc = new StreamingContext(conf,Duration(5000))
//配置一系列基本配置
val groupid = "GPMMCC"
val topic = "mysqlDemo"
val brokerList = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
// val zkQuorum = "hadoop01:2181,hadoop02:2181,hadoop03:2181"
val topics = Set(topic)
//设置kafka的参数
val kafkaParams = Map(
"metadata.broker.list"->brokerList,
"group.id"->groupid,
"auto.offset.reset"->kafka.api.OffsetRequest.SmallestTimeString
)
//加载配置 application.conf
DBs.setup()
//不需要查询zk中的offset啦,直接查询MySQL中的offset
val fromdbOffset:Map[TopicAndPartition,Long]=
DB.readOnly{
implicit session=>{
//查询每个分组下面的所有消息
SQL(s"select * from offset where groupId = '${groupid}'" +
//将MySQL中的数据赋值给元组
s"").map(m=>(TopicAndPartition(m.string("topic"),m.string("partitions").toInt),m.string("untilOffset").toLong))
.toList().apply()
}.toMap //最后toMap ,应为前面的返回值已经给定
}
//创建一个DStream,用来获取数据
var kafkaDStream : InputDStream[(String,String)] = null
//从MySql中获取数据进行判断
if(fromdbOffset.isEmpty){
kafkaDStream = KafkaUtils.createDirectStream[String,String,StringDecoder,
StringDecoder](ssc,kafkaParams,topics)
}else{
//1\ 不能重复消费
//2\ 保证偏移量
var checkOffset = Map[TopicAndPartition,Long]()
//加载kafka的配置
val kafkaCluster = new KafkaCluster(kafkaParams)
//首先获得kafka中的所有的topic和partition Offset
val earliesOffset: Either[Err, Map[TopicAndPartition, KafkaCluster.LeaderOffset]
] = kafkaCluster.getEarliestLeaderOffsets(fromdbOffset.keySet)
//然后开始比较大小,用mysql中的offset和kafka中的offset进行比较
if(earliesOffset.isRight){
//去到需要的 大Map
//物取值
val tap: Map[TopicAndPartition, KafkaCluster.LeaderOffset] =
earliesOffset.right.get
//比较,直接进行比较大小
val checkOffset = fromdbOffset.map(f => {
//取kafka中的offset
//进行比较,不需要重复消费,取最大的
val KafkatopicOffset = tap.get(f._1).get.offset
if (f._2 > KafkatopicOffset) {
f
} else {
(f._1, KafkatopicOffset)
}
})
checkOffset
}
val messageHandler=(mmd:MessageAndMetadata[String,String])=>{
(mmd.key(),mmd.message())
}
//不是第一次启动的话 ,按照之前的偏移量取数据的偏移量
kafkaDStream = KafkaUtils.createDirectStream[String,String,StringDecoder
,StringDecoder,(String,String)](ssc,kafkaParams,checkOffset
,messageHandler)
}
var offsetRanges = Array[OffsetRange]()
kafkaDStream.foreachRDD(kafkaRDD=>{
offsetRanges = kafkaRDD.asInstanceOf[HasOffsetRanges].offsetRanges
val map: RDD[String] = kafkaRDD.map(_._2)
map.foreach(println)
//更新偏移量
DB.localTx(implicit session =>{
//去到所有的topic partition offset
for (o<- offsetRanges){
/*SQL("update offset set groupId=? topic=?,partition=?," +
"untilsOffset=?").bind(groupid,o.topic,o.partition,o.untilOffset).update().apply()*/
SQL("replace into offset(groupId,topic,partitions,untilOffset) values(?,?,?,?)").bind(
groupid,o.topic,o.partition.toString,o.untilOffset.toString
).update().apply()
}
})
})
ssc.start()
ssc.awaitTermination()
}
}
总结
以上的各种容错机制各有利弊,何种场景下使用何种方法需要自己斟酌。
参考链接
- https://blog.csdn.net/u010521842/article/details/78074354
- https://cloud.tencent.com/developer/article/1122403
- https://techvidvan.com/tutorials/spark-streaming-checkpoint/
- https://www.cnblogs.com/ITtangtang/p/8022772.html
- https://blog.csdn.net/kwu_ganymede/article/details/50314901
- https://www.cnblogs.com/frankdeng/p/9308585.html
- https://blog.csdn.net/NepalTrip/article/details/79272646
- https://blog.csdn.net/m0_37637511/article/details/80560173