链表,字符串题,模拟与高精度
文章目录
- 1.字母转换为大写
- 4.24
-
- ① 2.小猴记单词 1125
- ② 3.花生采摘
- 4.25
-
- ①删除链表节点
- ②删除倒数第n个节点
- 4.26
-
- ①反转链表
- 4.27
-
- ①171.转化为26进制,excel表中的字母转数字
- ②蛇形方阵5731
- 4.28
-
- ①外观数列
- ②口算练习题
- 4.29
-
- ①标题统计
- ②P5734 文字处理软件
- ③p1308统计单词数
- 4.30
-
- ①p1765手机
- ②p3741 VK键盘
- 5.1
-
- ①p1553 数字反转
- 5.9
-
- ①括号匹配判断
- 5.10
-
- ①回文链表
- 5.24 模拟与高精度
-
- 一。框架
- 1.[NOIP2003 普及组] 乒乓球
- 2.[NOIP2010 普及组] 接水问题
- 5.25
-
- 1.扫雷游戏P2670
主要记录字符串题,暂时 刷力扣有 逆反 心理,故从洛谷新手着手
1.字母转换为大写
1.小写字母a ~ z的ANSI码范围97~122
大写字母A ~ Z的ANSI码范围65~90
差值32
带引号的’a’(符号)就是97(ANSI码值)
2.也可以使用toupper函数
#include4.24
① 2.小猴记单词 1125
4.24算法1
统计每个字符出现的次数
题目 1125笨小猴

初步想法
//1.统计每个单词出现的次数(这里*有问题* ,想法太过繁琐,创建两个数组做标记,不推荐),找到最大最小值
//2.最值作差,判断质数输出 Lucky Word,并且输出差值:否则输出 No Answer
解决问题:字母转化为数字 a[i]-‘a’ ,作为数组下标,起数组sum[a[i]-‘a’]++作标记,第一个元素表示a
方便:不用定义记录字母有没有在单词中出现过的数组,sum[i]>0
#include② 3.花生采摘
4.24.算法2.
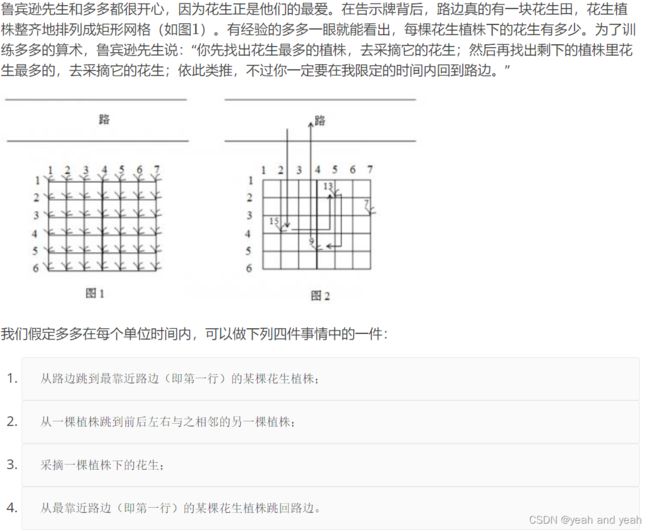

①用到曼哈顿距离算法

想法:
创建一个递归函数,不断存位置加距离,根据与最大路线判断,退出递归,
//按顺序采摘,采摘前要判断剩下的步数够不够走向下一个最大数
#include4.25
①删除链表节点
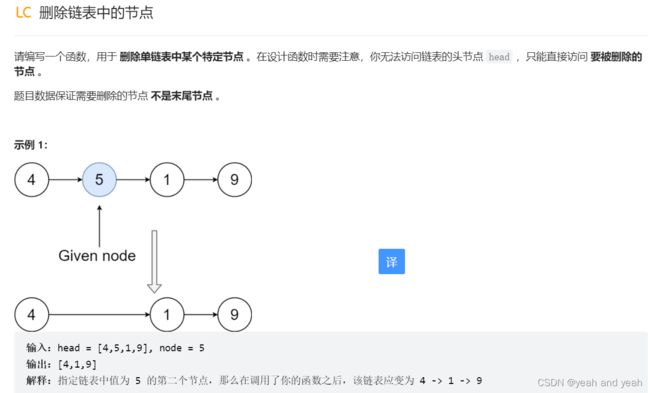
想法
法一:
双链表,
创建一个前驱结点和一个后继结点
通过本结点的前驱结点的后继结点指向本结点的后继点删除本节点
typedef struct node {
int data;
struct node* pre;
struct node* next;
}Node, *Link;
Link Init() {
Node *head;
head = (Node *)malloc(sizeof(Node));
head->pre = NULL;
head->next = NULL;
return head;
}
void Creat(Link head) {
Node *p = head, *q;
int data;
printf("输入链表数据:\n");
while(1) {
scanf("%d",&data);
if(data == 0) {
break;
}
q = (Node *)malloc(sizeof(Node));
q->pre = NULL;
q->next = NULL;
q->data = data;
p->next = q;
q->pre = p;
p = p->next;
}
// p->next = NULL;
}
void Delete(Link head,int n) {
Node *p = head, *q;
while(p) {
if(p->data == n) {
break;
}
p = p->next;
}
if(p && p->next != NULL) {
p->pre->next = p->next;
free(p);
}
}
法二:
单链表:
只创建后继结点
加一个中间变量q做过度,q=p,
p->next = q->next;
void Creat(Link head) {
Node *p = head, *q;
int data;
printf("输入链表数据:\n");
while(1) {
scanf("%d",&data);
if(data == 0) {
break;
}
q = (Node *)malloc(sizeof(Node));
q->data = data;
p->next = q;
p = q;
}
p->next = NULL;
}
void Delete(Link head,int n) {
Node *p = head, *q;
while(p) {
if(p->data == n) {
break;
}
q = p;
p = p->next;
}
if(p && p->next != NULL) {
q->next = p->next;//
free(p);
}
}
简便点:
void Delete(Link head, int a) {
Node *p = head, *q;
if(p->data != a) {
p = p->next;
}
q = p->next;
p->next = q->next;
free(q);
}
无头节点
p->data = p->next->data;
p->next = p->next->next;
②删除倒数第n个节点

思路
想法一:
计算链表总长度,通过传长度以及特定位置,删除节点(1)
int length(Link head) {
int n = 0;
Node *p = head->next;
while(p) {
n++;
p = p->next;
}
return n;
}
void Delete(Link head, int a) {
Node *p = head, *q;
int pos;
while(pos < length(head)-a && p) {
pos++;
p = p->next;
}
if(p) {
q = p->next;
p->next = q->next;
}
}
简便点:
void Delete1(Link head, int n) {
Node *p = head, *q;
int pos = 0;
if(pos != n) {
pos++;
p = p->next;
}
q = p->next;
p->next = q->next;
free(q);
}
想法2:
快慢指针:
struct ListNode* removeNthFromEnd(struct ListNode* head, int n){
struct ListNode* fast, *slow;
int i;
fast = head;
slow = head;
for(i = 0;i < n;i++) {
fast = fast->next;
}
if(fast == NULL) {
return head->next;
}
while(fast->next != NULL) {
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;
return head ;
}
4.26
①反转链表

很不习惯力扣只能提交无头结点的链表,用有头结点的链表做输出会将首节点看做无效的头结点,作用于从第二个数开始之后。
思路一:
再构造一个链表,将该链表中的每一个数都作为新链表的头节点
原 1 2 3 4 NULL ; 新 NULL
1.
原 1 2 3 4 NULL ; 新 1 NULL
2.
原 1 2 3 4 NULL ; 新 2 1 NULL
3.
原 1 2 3 4 NULL ; 新 3 2 1 NULL
4.
原 1 2 3 4 NULL ; 新 4 3 2 1 NULL
Link Reverse(Link head) {
Node *p = NULL, *q; //pÊÇÐÂÁ´±íµÄÊ×½áµã
while(head) {
q = head->next; //q×÷Ϊ²»¶ÏÑ»·Ã½½é
head->next = p;
p = head;
head = q;
}
return p;
}
4.27
①171.转化为26进制,excel表中的字母转数字

思路
我一直很颠倒ANSI码的使用,这里使用单引号作差可以得到数字差值,加一即表示 excel中字母的大小 ,再乘以26的位置次方可得到数字值
int main()
{
long long n=0,t=1,i=0;
char s[26] = {0};
printf("你将转化的字母是:\n");
scanf("%s",s);
int m=strlen(s);
for(i=m-1;i>=0;i--)
{
n += t*(s[i]-'A'+1); //我一直很颠倒ANSI码的使用,这里使用单引号作差可以得到数字差值,加一即表示 excel中字母的大小
t*=26; //①t=pow(26,0) ②t=pow(26,1)...
}
printf("转化成数字是:%d\n",n);
return 0;
}
②蛇形方阵5731


初步想法写出四个外部基本规律,问题在于如何运用到循环中,i,j,x,y 关系
优化解法
1.既然有四个规律,那就给蛇,如果越界或位置被占,不断转头,不断向右转
2.不断打印上下左右,t=1,t++;以 t
1.*越界或位置被占*,不断转头,不断向右
#include4.28
①外观数列

思路:
递归 加 双指针
边说边数 字符串指针(拿捏分配空间大小)
遍历字符串,对连续相邻字符串计数,记得数存储在数组中,注意转化ANSI,被记得数放在记得数之后,重置为1,不断开辟空间,循环。
坑:‘0’与ANSI码
#include②口算练习题
自己的算法实在差,开始就练习力扣实在打击,造成逆反更加不想刷,就还是从洛谷的新手刷吧。

初步想法:
while循环,输出用printf返回值减一
问题:我得循环输入必须是3个(%c输入需要&,%s不需要),与题目2个输入与上一运算类型相等不符,
优化
通过判断循环内第一个是字母(存储)还是数字(使用sscanf ( 掌握[], ^, *如何使用))是数字存储到倒数第二个数字中,输入最后一个数字.注意mamset清空字符串,防止长度判断错误,sprintf格式化的数据写入字符串
例如:
①
char b[10] = {0,1,2,3,4,a,b,c};
sscanf(b,“%10[0-9]”,&c);
把数组b中含有的0-9的数字写入c;
前至后读写
②
char a[] = {‘1’, ‘2’, ‘3’, ‘4’};
char b[] = {‘5’, ‘6’, ‘7’, ‘8’};
char buffer[10];
sprintf(buffer, “%.4s%.4s”, a, b);后至前读写
连接a,b数组读写入buffer数组
#include4.29
①标题统计
在这里水一道题,一个小点
字符串输入scanf与gets
gets(s)函数与 scanf(“%s”,&s) 相似,但不完全相同,使用scanf(“%s”,&s) 函数输入字符串时存在一个问题,就是如果输入了空格会认为字符串结束,空格后的字符将作为下一个输入项处理,但gets()函数将接收输入的整个字符串直到遇到换行为止。

思路:
标题中可能包含大、小写英文字母、数字字符、空格和换行符。统计标题字 符数时,空格和换行符不计算在内。
#include②P5734 文字处理软件


思路
循环n次内输入字符串b , 根据b[0]赋值给 a 判断类型,分装函数。
1.后插使用sprintf或者strcat(字符串拼接)都可
char f1(int b[]) { //后插
char str[100], p[100];
gets(str);
sprintf(p,"%s%s",b,str); //
return p;
}
2.strcpy,妙了!截止位置后置零,开始位置首地址重新存储临时变量中,再将临时变量中的覆盖到原函数
char f2(int b[]) { //截取 c到d字符串
int c, d;
char p[100];
scanf("%d%d",&c,&d);
b[c+d] = '\0';//
strcpy(p,&b[c]);
strcpy(b,p);
return b;
}
3.strcat(覆盖原dest结尾处的’\0’),并添加新的’\0’。)妙,题目要求放在之前,确定位置后面的数 连接 将要插的数组后 ,重置将要插后面(已存),连接
char f3(int b[]) { // 特定位a之前插入p
int a;
char p[100];
scanf("%d%s",&a,p);
strcat(p,&b[a]); //后面的数连接将要插的数组后
b[a] = '\0'; //重置将要插后面(已存)
strcat(b,p); //连接
return b;
}
√找到一个和str[0]str[0]相等的字符,就往后判断是否相等
void f4(int b[]) { //查找 返回首地址位置
char p[100], l = -1;
scanf("%s",p);
bool flag;
int i;
for(i = 0;i < strlen(b) - strlen(p)+1;i++) {
int j = 0;
flag = false;
while(b[i++] == p[j++] && j < strlen(p)) { //判断子字符串是否相等
flag = true;
}
if(j == strlen(p)) {
l = i - j; //i往后j个,需要减去
break;
}
if(flag) {
i--;//找到了和p[0]相等的字符但不是答案之后加上一个i--
}
}
printf("%d",l);
}
×查找子字符串1.strstr返回出现的首地址,否则返回null
2.strchr同样返回查找字符首地址
char a[10] = {"abcdef"};
printf("%s\n",strchr(a,'c')); //ANSI码值
printf("%s\n",strstr(a,"c")); //元素
均打印出 cdef
omg 强制类型转化 int(q-b) nonono c语言不允许!)
问题:
2.截取字符串中 指定位 (不是后面所有都输出)
只保留文档中从第 a 个字符起 b 个字符,
很可惜c语言不提供substr函数:substr(a,b,2,6);将b串中第2个字符起,后6个放入a数组中。
③p1308统计单词数
和考核题目以及上题第四步很像


思路:
转化大写为小写,(32)
创建两个指针,遍历文章一一对比单词是否相等
利用strstr(返回首次出现的指针否则返回NULL(空指针))
问题:可能出现两次该字符串,如何标记第一次字母出现的位置,而不会被第二次覆盖
flag仅标记第一次,为true后再
收获:
tolower返回值为 int 类型,你可能需要隐式或者显式地将它转换为 char 类型
对于 tolower(),仅当有且只有一个对应的小写字母时,这种转换才能成功;如果没有对应的小写字母,或者有多个对应的小写字母,那么转换失败。转换成功返回对应的小写字母,转换失败直接返回 c(值未变)。
char ch = 'A';
ch = tolower(ch);
printf("ch=%c\n",ch);
ch = 'b';
ch = toupper(ch);
isupper
函数isupper()采用整数形式的单个参数,并返回int类型的值 。
既然都只针对单个字符,那循环就能改变字符串
对了,c语言仅支持 to 开头,不支持 is 开头
#include4.30
①p1765手机


caicai思路:
caicai第一思路就是打表,吧每一个数首字母,第2,3,4个字母分别用if敲出来,再进行sum+=1,2,3,4;
实现一下:
#include大佬想法:
也是打表,不过是打每个数字,更简洁
#include②p3741 VK键盘


caicai想法:
就是统计相邻特定字符串出现次数
这道题就是找两种子串
“VK”
“VV”或“KK”
果然想简单了~ ^ ~(才跑了6分5555)
问题:
1.题目要求输入整形与字符串,我就习惯性,scanf, gets a a巴嘎就在这里:如果在scanf后用gets需要注意一点,gets是遇到’\n’直接返回,而输入scanf后回车会将’\n’留在输入缓存里,而gets正好遇到’\n’就直接返回了,所以你没有机会输入。
解决就两个gets(a)咯
2.VK相邻时可以,但是最后一个例子过不去啊!要把计数过的筛掉,否则就是3咯
char a[102];
int main()
{
gets(a);
gets(a);
int ans=0;
for(int i=0;i<strlen(a);i++)
{
if(a[i]=='V' && a[i+1]=='K')
{
ans++;
a[i]='X';
a[i+1]='X';
} //筛掉辣
}
for(int i=0;i<strlen(a);i++)
{
if(a[i]!='X' && a[i]==a[i+1])
{
ans++;
break; //先从头到尾跑一遍,把正确的VK都改为X
}
}
printf("%d",ans);
return 0;
}
5.1
①p1553 数字反转



问题:
// 1.怎么判断是 小数,分数,百分数,整数。呢
//寻找符号 ,也就是非数字
// 2.这些可以都用gets或者%s输入吗?
// gets输入
// 3. 4个能用char类型表示吗?精度够吗
//可以的,分开数为两部分,注意存储符号
caicai看到题头已大
大佬思路:
分开数为两部分,注意存储符号
#include5.9
①括号匹配判断

初步想法:
手打栈,存储左边符号,遇到右边符号时化为左边存储,和存储到栈内的符号自顶向低一一比对,但是比对时对于 --top 出现了问题。
想法优化:
遇到左i符号直接转换为右符号存储到 a[top++] 会方便很多,后续直接比较,
比较时采用 s[i] 与 a[–top] 的关系
注意:
#include例:
( [ { } ( ) ] )

5.10
①回文链表

知识点:栈,快慢指针,递归,链表
初步想法:
利用栈,新链表放置前1半截数据,逆置链表后(后半截编程前半截2),前半截2数据和1数据比较
问题
选取前半截链表的方法太过繁琐(计算链表长度,还要判断奇偶)
解决:
方法1:
快慢指针找中点后,通过fast != NULL得到链表结点数为奇数个 ,
然后反转后面一半的链表,和前面链表一一比对
Link Reverse(Link head) {
Node *p = head, *q, *r;
q = r = NULL;
while(p) {
q = p->next;
p->next = r;
r = p;
p = q;
}
return r;
}
bool Panduan(Link head) {
Node *fast = head, *slow = head;
while(fast != NULL && fast->next != NULL) {
fast = fast->next->next;
slow = slow->next;
}
//快慢指针找到中间,slow的指向
if(fast != NULL) {
slow = slow->next;
}
//此时slow指向后半部分
slow = Reverse(slow);
//反转后半部分
fast = head;
//fast指向头
while(slow != NULL) {
if(slow->data != fast->data) {
return false;
}
fast = fast->next;
slow = slow->next;
}
//对比反转后的链表和前面的数据。
return true;
}
int main() {
Node *wei = NULL, *tou = NULL; //没有头结点需要对第一个节点进行操作
wei = Creatwei(wei);
Output(wei);
tou = Reverse(wei);
Output(tou);
if(Panduan(wei)) {
printf("True!\n");
} else {
printf("false!\n");
}
return 0;
}
方法2;
栈 逆序存储前半部分再与后半部分一一比对
表的长度,将链表前面一般的元素入栈,然后逐个出栈与后一半的元素进行比较,如果一旦不相等立马返回FALSE,停止比较,如果到最后栈不为空也要返回FALSE,只有当栈为空且出栈的元素和链表后一半的元素都想得才能返回TRUE;另外要注意的一点是长度为1的链表都是回文链表所以要进行特殊处理,即当length=1时直接返回TRUE不用进行后续的操作。
int l(Link head) //计算长度
{
Link p=head;
int i=0;
while(p!=NULL)
{
i++;
p=p->next;
}
return i;
}
void push(Link *s,int n) //尾插法给新链表传送数据
{
Link p;
p=(Node *)malloc(sizeof(Node));
p->data=n;
p->next=(*s);
(*s)=p;
}
int pop(Link* s)
{
int e=(*s)->data;
(*s)=(*s)->next;
return e;
}
int empty(Link S)
{
if(S==NULL)
return 0;
else
return 1;
}
bool Panduan2(Link head){
if(head==NULL)
return false; //头为空,没有数,不是回文链表
Link S;
S=NULL;
Link p=head;
int length=l(head); //计算长度
if(length==1)
return true; //链表中仅有一个数,是回文链表
int i;
for(i=1;i<=length/2;i++) //一半链表入栈
{
push(&S,p->data); //将链表数据传入新链表 S
p=p->next;
}
if(length%2!=0) //链表长度奇数
p=p->next;
while(p!=NULL)
{
if(p->data==pop(&S)) //对比
p=p->next;
else
return false;
}
if(empty(S)==0&&p==NULL)
return true;
else
return false;
}
方法三:
递归
定义一个全局变量,保存头节点, 递归到最后和头结点比较
Link temp;
bool check(Link head) {
if(head == NULL) {
return true;
}
bool res = check(head->next) && (temp->data == head->data);
temp = temp->next;
return res;
}
bool Panduan3(Link head) {
temp = head;
return check(head);
}
5.24 模拟与高精度
一。框架

1.[NOIP2003 普及组] 乒乓球
题目背景
国际乒联现在主席沙拉拉自从上任以来就立志于推行一系列改革,以推动乒乓球运动在全球的普及。其中 11 11 11 分制改革引起了很大的争议,有一部分球员因为无法适应新规则只能选择退役。华华就是其中一位,他退役之后走上了乒乓球研究工作,意图弄明白 11 11 11 分制和 21 21 21 分制对选手的不同影响。在开展他的研究之前,他首先需要对他多年比赛的统计数据进行一些分析,所以需要你的帮忙。
题目描述
华华通过以下方式进行分析,首先将比赛每个球的胜负列成一张表,然后分别计算在 11 11 11 分制和 21 21 21 分制下,双方的比赛结果(截至记录末尾)。
比如现在有这么一份记录,(其中 W \texttt W W 表示华华获得一分, L \texttt L L 表示华华对手获得一分):
WWWWWWWWWWWWWWWWWWWWWWLW \texttt{WWWWWWWWWWWWWWWWWWWWWWLW} WWWWWWWWWWWWWWWWWWWWWWLW
在 11 11 11 分制下,此时比赛的结果是华华第一局 11 11 11 比 0 0 0 获胜,第二局 11 11 11 比 0 0 0 获胜,正在进行第三局,当前比分 1 1 1 比 1 1 1。而在 21 21 21 分制下,此时比赛结果是华华第一局 21 21 21 比 0 0 0 获胜,正在进行第二局,比分 2 2 2 比 1 1 1。如果一局比赛刚开始,则此时比分为 0 0 0 比 0 0 0。直到分差大于或者等于 2 2 2,才一局结束。
你的程序就是要对于一系列比赛信息的输入( WL \texttt{WL} WL 形式),输出正确的结果。
输入格式
每个输入文件包含若干行字符串,字符串有大写的 W \texttt W W 、 L \texttt L L 和 E \texttt E E 组成。其中 E \texttt E E 表示比赛信息结束,程序应该忽略 E \texttt E E 之后的所有内容。
输出格式
输出由两部分组成,每部分有若干行,每一行对应一局比赛的比分(按比赛信息输入顺序)。其中第一部分是 11 11 11 分制下的结果,第二部分是 21 21 21 分制下的结果,两部分之间由一个空行分隔。
样例 #1
样例输入 #1
WWWWWWWWWWWWWWWWWWWW
WWLWE
样例输出 #1
11:0
11:0
1:1
21:0
2:1
提示
每行至多 25 25 25 个字母,最多有 2500 2500 2500 行。
(注:事实上有一个测试点有 2501 2501 2501 行数据。)
思路
遍历字符串,分别以11和21作为一组,重置计数器分别计数W,L,以E作为结束标志。
卡在了,如何分堆及输出 ,在那个位置重置计数器还要保证扫描的还是下一个数。
omg忽略了·一条信息:直到分差abs大于或者等于 22,才一局结束。
注意使用字符需要带 ‘ ’
大佬想法:
输入一个计数一个,使用另一个数组a存储,先使用11进制,再用a数组判断21进制
#include2.[NOIP2010 普及组] 接水问题
题目描述
学校里有一个水房,水房里一共装有 m m m个龙头可供同学们打开水,每个龙头每秒钟的供水量相等,均为$ 1$。
现在有$ n $名同学准备接水,他们的初始接水顺序已经确定。将这些同学按接水顺序从 1 1 1到$ n 编 号 , 编号, 编号,i $号同学的接水量为 w i w_i wi。接水开始时,$1 到 到 到 m$ 号同学各占一个水龙头,并同时打开水龙头接水。当其中某名同学$ j 完 成 其 接 水 量 要 求 完成其接水量要求 完成其接水量要求 w_j$后,下一名排队等候接水的同学 k k k马上接替 j j j 同学的位置开始接水。这个换人的过程是瞬间完成的,且没有任何水的浪费。即 j j j 同学第 x x x 秒结束时完成接水,则$ k$ 同学第 x + 1 x+1 x+1 秒立刻开始接水。若当前接水人数 n n n’不足 m m m,则只有 n n n’个龙头供水,其它 m − n m-n m−n’个龙头关闭。
现在给出 n n n 名同学的接水量,按照上述接水规则,问所有同学都接完水需要多少秒。
输入格式
第 1 1 1 行$ 2$ 个整数 n n n 和 m m m,用一个空格隔开,分别表示接水人数和龙头个数。
第 2 2 2 行 n n n 个整数$ w_1,w_2,…,w_n , 每 两 个 整 数 之 间 用 一 个 空 格 隔 开 , ,每两个整数之间用一个空格隔开, ,每两个整数之间用一个空格隔开,w_i 表 示 表示 表示 i $号同学的接水量。
输出格式
1 1 1 个整数,表示接水所需的总时间。
样例 #1
样例输入 #1
5 3
4 4 1 2 1
样例输出 #1
4
样例 #2
样例输入 #2
8 4
23 71 87 32 70 93 80 76
样例输出 #2
163
提示
【输入输出样例 1 说明】
第 1 1 1 秒,$3 $人接水。第 $1 $秒结束时,$1,2,3 $号同学每人的已接水量为 $1,3 $号同学接完水,$4 $号同学接替 3 3 3 号同学开始接水。
第 2 2 2 秒,$3 人 接 水 。 第 人接水。第 人接水。第 2$ 秒结束时,$1,2 $号同学每人的已接水量为 $2,4 号 同 学 的 已 接 水 量 为 号同学的已接水量为 号同学的已接水量为 1$。
第 3 3 3 秒,$3 人 接 水 。 第 人接水。第 人接水。第 3$ 秒结束时, 1 , 2 1,2 1,2 号同学每人的已接水量为 3 , 4 3,4 3,4 号同学的已接水量为$ $2。 4 4 4 号同学接完水, 5 5 5 号同学接替$ 4 $号同学开始接水。
第$ 4$ 秒,$3 $人接水。第 $4 $秒结束时, 1 , 2 1,2 1,2 号同学每人的已接水量为 $4,5 号 同 学 的 已 接 水 量 为 号同学的已接水量为 号同学的已接水量为 1$。 1 , 2 , 5 1,2,5 1,2,5 号同学接完水,即所有人完成接水的总接水时间为 4 4 4 秒。
【数据范围】
1 ≤ n ≤ 10000 , 1 ≤ m ≤ 100 1≤n≤10000,1≤m≤100 1≤n≤10000,1≤m≤100 且$ m≤n$;
1 ≤ w i ≤ 100 1≤w_i≤100 1≤wi≤100。
思路:
数组(开大防止下溢)统计水,下标使用水龙头的序号,
接水的人从m+1 开始,以m + n 结束
#include5.25
1.扫雷游戏P2670
题目描述
扫雷游戏是一款十分经典的单机小游戏。在 n n n行 m m m列的雷区中有一些格子含有地雷(称之为地雷格),其他格子不含地雷(称之为非地雷格)。玩家翻开一个非地雷格时,该格将会出现一个数字——提示周围格子中有多少个是地雷格。游戏的目标是在不翻出任何地雷格的条件下,找出所有的非地雷格。
现在给出 n n n行 m m m列的雷区中的地雷分布,要求计算出每个非地雷格周围的地雷格数。
注:一个格子的周围格子包括其上、下、左、右、左上、右上、左下、右下八个方向上与之直接相邻的格子。
输入格式
第一行是用一个空格隔开的两个整数 n n n和 m m m,分别表示雷区的行数和列数。
接下来 n n n行,每行 m m m个字符,描述了雷区中的地雷分布情况。字符’*’表示相应格子是地雷格,字符’?’表示相应格子是非地雷格。相邻字符之间无分隔符。
输出格式
输出文件包含 n n n行,每行 m m m个字符,描述整个雷区。用’*’表示地雷格,用周围的地雷个数表示非地雷格。相邻字符之间无分隔符。
样例 #1
样例输入 #1
3 3
*??
???
?*?
样例输出 #1
*10
221
1*1
样例 #2
样例输入 #2
2 3
?*?
*??
样例输出 #2
2*1
*21
提示
对于 100 % 100\% 100%的数据, 1 ≤ n ≤ 100 , 1 ≤ m ≤ 100 1≤n≤100, 1≤m≤100 1≤n≤100,1≤m≤100。
思路: 遍历s[n][m]中每一个字符周围的8个,是*给cnt++,放在另一个数组a[110][110]中;
问题:很浪费空间,计数时对于8个 if 有什么优化方法。
解决1:
挨个输入一个字符标记 * 点为1 计入s数组,输出时将周围 8 个点求和,复杂度没变,但是会相比没个点8 个if还是简化的。
坑:这里输入字符需要在每一行前加入getchar回收回车,不然回车会产生一个字符,getchar会回收一个字符
#include