C++初探 5-2(while循环 do while循环 输入 二维数组)
目录
注
while循环
for 与 while
编写延时循环
do while循环
基于范围的for循环(C++11)
循环和文本输入
使用原始的cin进行输入
使用cin.get(char)进行补救
使用不同的cin.get( )
文件尾条件
另一个cin.get( )版本
嵌套循环和二维数组
初始化二维数组
使用二维数组
注
本笔记参考:《C++ PRIMER PLUS(第6版)》
while循环
可以把while循环看作没有初始化和更新部分的for循环,即while循环只存在测试条件和循环体:

和for循环一样,① 当while循环的测试表达式值为true时,执行循环体中的语句。② 执行完毕后,返回测试表达式重新进行评估,直到测试条件为false。

使用例:遍历字符串,显示其中的字符及其ASCII码。
#include
const int ArSize = 20;
int main()
{
using namespace std;
char name[ArSize];
cout << "请输入一个单词(英文):";
cin >> name;
cout << "这个单词拥有的字符及其ASCII码是:\n";
int i = 0;
while (name[i] != 0)
{
cout << name[i] << ": " << int(name[i]) << endl;
i++;
}
return 0;
} 程序执行的结果是:

【分析】
在上述程序的while循环的最后,存在 i++; 这样的语句,while循环需要通过类似于这种语句去更新测试表达式的结果,否则可能会进入死循环。
当然,上述while行可以改成这样:
while (name[i])此时,测试表达式有两个可能值:
- 若name[i]是常规字符,其值应该为 true 或者 一个非零值(对应字符的编码);
- 若name[i]是空值字符,其值应该为 false 或者 0 。
另外,在上述程序中,为了打印字符的ASCII码,使用了强制类型转换,否则cout将会把name[i]解释为字符编码。
string对象并没有使用空字符标记字符串末尾,如果使用string对象,就要对应改变上述程序。
for 与 while
在本质上,for循环和while循环是相同的。例如:
- 下方的for循环:
for (int i = 0; i < 10; i++) { cout << i << endl; }可改成对应的while循环:
int i = 0; while (i < 10) { cout << i << endl; i++; } - 或者将while循环:
while (j > 0) { i += j; j--; }改写为对应的for循环:
for ( ; j > 0; ) { i += j; j--; }
对于for循环而言,其需要的3个表达式均可以是空表达式,只有分号是必须要有的。不过如果测试表达式为空,那么这个for循环将会是一个死循环,类似于:
int i = 0;
for (; ;)
cout << i++ << endl;
因此,在设计循环时,需要知道3个条件:
- 循环终止的条件;
- 首次测试前的初始化条件;
- 在条件被再次测试之前的更新条件。
for循环在结构上明确指出了这3个条件。而在无法预知循环的执行次数时,程序员会使用while循环。
在书写循环时,可能会出现这种情况:
i = 0; while (name[i] != '\0'); //存在问题:多写了一个分号 { cout << name[i] << endl; i++; }上述代码在while行中多插入了一个分号,因为分号结束语句,因此分号将会结束while循环(即上述循环的循环体为空语句)。所以,上述循环不执行任何操作,成为了一个死循环。
编写延时循环
在一种用于个人计算机的早期技术中,会通过while循环的使用来进行延时操作:
int main()
{
long wait = 0;
while (wait < 1000000)
wait++;
return 0;
}但这种延时方式受到计算机处理器的限制,在不同的计算机上可能需要不同的计数限制。另外,现在计算机的计算速度已经很快了,通过这种方式进行延时操作并不合适。
而现在,ANSI C和C++库提供了一个函数,clock( ) ,它能够返回出现开始执行后所用的系统时间。但依旧存在一些问题:
- clock( )返回的时间,单位不一定是 秒 ;
- clock( )的返回类型并不一致,可能是long,也可能是unsigned long等等。
为此,需要使用头文件

另一方面,
例子:
#include
#include
int main()
{
using namespace std;
cout << "请输入需要延迟的时间(单位是秒):";
float secs;
cin >> secs;
clock_t delay = secs * CLOCKS_PER_SEC;
cout << "开始计时\a\n";
clock_t start = clock();
while (clock() - start < delay);
cout << "完成\a\n";
return 0;
} 程序执行的结果:

上述程序选择了以系统时间为单位(不以秒为单位)进行延迟时间的计算,省去了在每轮循环中将系统时间转换成秒的操作。
在之前提到过,clock_t 是一个系统别名,而C++创建别名的方式有两种:
- 使用预处理器,例如:
#define BYTE char预处理器将使用char类型替换程序中出现的所有BYTE,这就使BYTE成为了char的别名;
-
使用关键字typedef创建别名,例如:
typedef char byte; //将 byte 作为char的别名通用格式:

如果要让 byte_pointer 成为char指针的别名,可以这样做:
typedef char* byte_pointer;
尽管上述两种方法都可以用来创建别名,但是在使用 #define 声明一系列变量时应该注意:
#define FLOAT_POINTER float* FLOAT_POINTER pa, pb;上述代码在预处理器的转换后,会变成这样:
float* pa, pb; //此时,pa是一个浮点型指针,pb是一个浮点型变量不过typedef不会有这样的问题,它能够处理更复杂的类型别名。但注意,typedef不会创建新的类型,它只是为已有的类型创建一个新的名称。
do while循环
do while循环不同于之前的两种循环,它是出口条件循环:先执行循环体,再进入测试表达式。因此,do while循环至少会执行一次。其句式为:

do while循环的程序流程:
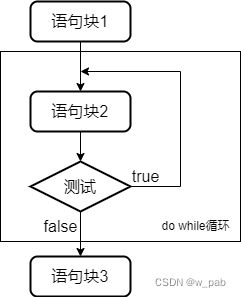
因为出口条件循环本身的结构, 有时候适合入口条件循环的场合并不一定适合do while循环,但在一些情况下,do while循环要更为合理。例如:请求用户输入,程序要先获得输入,再进行测试。
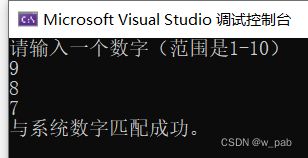
使用例:
#include
int main()
{
using namespace std;
int n;
cout << "请输入一个数字(范围是1-10)\n";
do
{
cin >> n; //先执行语句
} while (n != 7); //再进行测试
cout << "与系统数字匹配成功。\n";
return 0;
} 程序执行的结果是:
另一方面,存在如下的循环:
int I = 0; for (;;) { I++; //内部执行的一些操作 if (30 >= I) break; }或者
int I = 0; for (;; I++) { if (30 >= I) break; //内部执行的一些操作 }上述代码可读性差,也并非编写循环的通用模型。但第一个例子使用 do while循环 会使得代码表达更加清晰:
//对应之前的第一个例子 int I = 0; do { I++; //进行一些操作 } while (30 > I);类似地,第二个例子使用 while循环 会更易理解:
int I = 0; while (I < 30) { //进行一些操作 I++; }
基于范围的for循环(C++11)
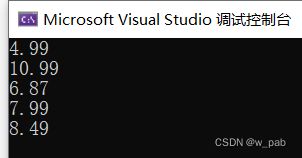
C++11新增了一种循环:基于范围的for循环。这简化了对于数组(或容器类,包括vector和array)的每个元素执行相同的操作,例如:
#include
int main()
{
using namespace std;
double prices[5] = { 4.99, 10.99, 6.87, 7.99, 8.49 };
for (double x : prices)
cout << x << endl;
return 0;
} 程序执行的结果是:
【分析】
先看语句:
for (double x : prices)在这条语句中,x 最初表示数组prices的第一个元素。此后,随着循环进行,x 依次表示了数组中的每个元素。
类似地,可以通过上述方式进行数组元素的修改:
for (double& x : prices) //& 表示引用变量
x = x * 0.80;还可以将这种语法与初始化列表结合起来:
for (int x : {3, 5, 2, 8, 6})
cout << x << " ";
cout << "\n";打印结果:

循环和文本输入
通过循环,能够完成一类常见、重要的工作:逐字符地读取来自文件或键盘的文本。在C++中,因为cin对象支持三种不同模式的单字符输入,其用户接口各不相同,所以需要分开讨论。
使用原始的cin进行输入
为了明确读取文本的循环停止的条件,有时,会选择某个特殊字符(哨兵字符),将其作为停止标记。譬如,下方的例子规定:在遇到 #字符 时停止读取输入。
例子
#include
int main()
{
using namespace std;
char ch;
int count = 0;
cout << "请输入字符(输入 # 时,结束文本读取):\n";
cin >> ch; //读取第一个字符(初始化)
cout << "\n读取到的字符是:\n";
while (ch != '#') //(测试)
{
cout << ch; //打印读取的字符
++count; //进行读取字符的计数
cin >> ch; //读取下一个字符(更新)
}
cout << "\n\n读取了 " << count << " 个字符。\n";
return 0;
} 程序执行的结果是:

【分析】
该循环在循环开始前就读取了第一个字符,这是为了让循环能够测试第一个字符(第一个字符也可能是'#')。
可以发现,程序在输出时忽略了空格(seeyouagain),这是因为 cin 在读取char值(或者其他基本类型)时,将自动省略空格和换行符。因此上述程序中,空格也没有被包含在计数(count)内。
另外,发送给cin的输入会先进入缓冲区,当用户输入回车键时,再统一发送给程序。这也解释了为什么在运行程序时,可以在 # 后面输入字符(因为程序在遇到 # 时就结束了对输入的处理)。
使用cin.get(char)进行补救
之前提到,通过原始的cin进行输入会忽略空格和换行符。而在cin所属的istream类中,包含了一个能够读入每个字符(包括空格、制表符和换行符)的成员函数cin.get( )。
例子:
#include
int main()
{
using namespace std;
char ch;
int count = 0;
cout << "请输入字符(输入 # 时,结束文本读取):\n";
//cin >> ch;
cin.get(ch);
cout << "\n读取到的字符是:\n";
while (ch != '#')
{
cout << ch;
++count;
cin.get(ch);
}
cout << "\n\n读取了 " << count << " 个字符。\n";
return 0;
} 程序执行的结果是:
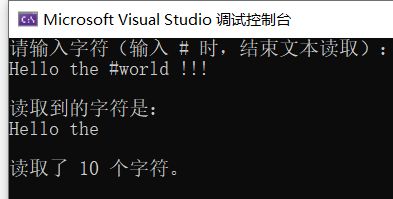
【分析】
这次程序打印了每个字符,并对它们进行了计数,包括空格。cin.get( )同样存在一个缓冲区,这意味着输入的字符个数可能并最终打印的要多。
解释 cin.get(ch);
如果用C语言的理解进行解释:该语句将 字符变量ch 传递给了 函数cin.get( )。这很明显是无效的,因为该函数的目的是修改变量ch的值,这需要的应该是ch的地址(即&ch)。
但程序执行的结果已经告诉我们,上述代码是正确的。这是为什么?
这是因为成员函数cin.get(ch)的参数声明是一个引用类型(引用类型是C++新增的一种类型):

使用不同的cin.get( )
回顾曾经提到过的例子:
#include
#define ArSize 20
int main()
{
using namespace std;
char name[ArSize];
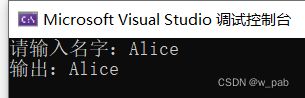
cout << "请输入名字:";
cin.get(name, ArSize).get();
cout << "输出:" << name << "\n";
return 0;
} 程序执行的结果是:
其中,存在着这条语句:
cin.get(name, ArSize).get();这条语句可以被看作是两个连续的函数调用:
cin.get(name, ArSize);
cin.get();这里出现了cin.get( )的两个版本:
- 一个版本接受两个参数:① 数组名((char*类型的)字符串的地址),② ArSize(int类型的整数);
- 另一个版本是不接受任何参数的cin.get( )。
而在之前的例子中,还存在一个 cin.get( ) :
-
char ch; cin.get(ch);该版本下的 cin.get( ) 接受一个char类型的参数。
这很明显区别于C语言的函数定义,而C++之所以可以这样做,是因为该语言支持被称为函数重载的OOP特性。函数重载允许创建多个同名函数,条件是它们的参数列表不同,例如:

如果输入的参数不同,编译器将会从上述各种版本的cin.get( )中选出适合当前参数的。
暂时总结:函数重载允许对多个相关的函数使用相同的名称,这些函数以不同的方式或针对不同的类型执行相同的基本任务。
为区分不同的函数版本,在引用这类函数时提供参数列表。
文件尾条件
在之前进行字符串输入的例子中,为了检测字符串输入完毕,需要在字符串末尾添加'#',但这明显没有考虑'#'可能是合法输入的组成部分,其他符号亦然。
如果输入来自文件,替代上述提到的特殊字符,可以使用一种技术 —— 检测文件尾(EOF - End of File)。这需要C++输入工具和操作系统协同工作。
首先了解两个概念:
- 重定向操作符( < ):很多操作系统支持重定向,即允许文件替换键盘输入,例如:
excute < word其中 excute.exe 是可执行文件,word 是文本文件。通过这种方式,程序将从word文件(而不是键盘)获取输入。
-
允许通过键盘输入模拟文件尾条件:
-
Unix中,需要在行首按下 Ctrl + D 来实现;
-
Windows命令提示符中,可在任意为止按下 Ctrl + Z + Enter 实现。
-
键盘输入的EOF概念是命令行环境遗留下来的。总之,很多PC环境都将 Ctrl + Z 视为模拟的EOF(不过有些系统不支持这种模拟的EOF,或者支持并不完善)。
例子:
#include
int main()
{
using namespace std;
char ch;
int count = 0;
cin.get(ch); //尝试进行第一个字符的读取
while (cin.fail() == false) //进行检测
{
cout << ch;
++count;
cin.get(ch);
}
cout << "\n读取了 " << count << " 个字符。\n";
return 0;
} 程序执行的结果是:

在检测到EOF之后,cin将会把成员常量 eofbit 和 failbit 都设置为1。此时可以通过成员函数eof( )或者fail( )进行检测,如果检测到EOF,函数会返回 true ,否则返回 false 。
(ps:fail( )和eof( )读取的都是最近的结果,它们是事后报告。)
通过重定向,可以用该程序显示文本文件及其包含的字符数,下面是Ubantu系统上的运行结果(其中test是可执行文件,word是文本文件):

1. EOF结束输入
正如之前提到的,cin在检测到EOF时,会在cin对象中设置一个指示EOF条件的标记。设置完毕后,cin将不再读取。但这仅针对文件输入。对于键盘输入,是有可能因为cin.clear( )清除了EOF标记,导致输入继续进行。
目前可知的:在一些系统里,Ctrl + Z 将结束输入和输出,但cin.clear( )将无法回复输入和输出。
2. 常见的字符输入做法
在程序的循环测试条件部分出现了这样的语句:
while (cin.fail() == false)之前提到过的,成员函数fail( )是有返回值的,通过将这种返回值和运算符结合起来,可以得到一种更简便的测试表达式(!运算符可以转换true和false):
while (!cin.fail())------
或者,因为istream类提供了一个可以将istream对象(如cin)转换为bool值的函数:当cin出现在需要bool值的位置时,该函数将被调用(在读取到EOF时,因为读取失败,将会得到的bool值是false):
while (cin) //当成功读取输入时,执行循环。因为通过这种方式执行的while循环可以检测更多的失败原因,如磁盘故障,所以这种写法会更加通用。
------
在之前的程序中,出现的输入语句是cin.get( ),该函数的返回值就是cin。因此,可以这样简化程序:
while (cin.get(ch))
{
//内部语句
}这种方式使得程序在这个运行过程中只对函数cin.get(char)进行了一次调用,并且,这条语句同时凑齐了循环的三个条件,即初始化、确定结束(检测)条件和更新条件。
另一个cin.get( )版本
还存在一种类似于 C语言的getchar( ) 的cin.get( )版本。在不接受任何参数时,cin.get( )将会返回输入中的下一个字符,例如:
ch = cin.get();这种版本的cin.get( )的工作方式是将字符编码作为int值返回(与其他版本存在区别:cin.get(ch)返回的是一个对象,而不是读取的字符)。类似地,存在cout.put( )函数,该函数可以进行字符的显示,工作方式类似于C语言的putchar( ):
cout.put(ch);最初,C++标准要求put( )成员只有一个原型,即put(char),该函数可以接受int参数。但有些C++实现提供了3个原型:put(char)、put(signed char)和put(unsigned char),此时给put( )传递一个int类型参数将导致错误,为此需要使用显式强制类型转换。
尽管提到了多种的cin版本,但此时还有一个问题没有得到解决,那就是如何判定EOF?(EOF不表示输入中的字符,而是表示没有字符)
为此,头文件iostream中定义了一个用符号常量EOF表示的特殊值,这个值必须不同于任何有效的字符值。通常,EOF被定义为 -1 :
![]()
之前提到的例子的核心:
char ch;
cin.get(ch);
while (cin.fail() == false)
{
cout << ch;
++count;
cin.get(ch);
}可以被替换成下方的代码:
int ch; //ch变为 int类型 的变量
ch = cin.get(); //使用了另一个版本的cin.get()
while (ch != EOF) //EOF测试替代了原本的cin.fail()检测
{
cout.put(ch); //在一些实现中可用 cout.put(char(ch)) 替代
++count;
ch = cin.get();
}需要注意,EOF表示的不是有效的字符编码,在某些系统中可能与char类型不兼容。此时需要使用int类型的变量接收cin.get( )(无参版本)的返回值,并在输出时进行强制类型转换。
使用cin.get( )方法的例子:
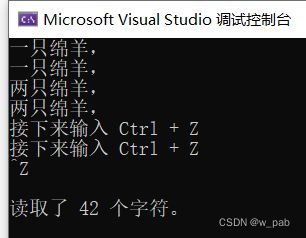
#include
int main()
{
using namespace std;
int ch;
int count = 0;
while ((ch = cin.get()) != EOF)
{
cout.put(char(ch));
++count;
}
cout << "\n读取了 " << count << " 个字符。\n";
return 0;
} 程序执行的结果是:
【分析】
先观察循环条件:
while ((ch = cin.get()) != EOF)子表达式 ch = cin.get( ) 两端的括号改变了程序的运算顺序,因此,该表达式的执行顺序应为:
- 调用函数cin.get( );
- 对 ch 进行赋值;
- 因为赋值表达式的值为左操作数的值,因此整个子表达式的值为 ch 的值;
- 将子表达式(ch)的值与EOF进行比较。
如果上述表达式中省略了子表达式的括号:
while (ch = cin.get() != EOF)因为 !=运算符 的优先级高于 =运算符 ,所以程序将会优先执行 cin.get() != EOF ,并将得到的bool值赋给 ch ,这就偏离了程序本意。
而如果使用 cin.get(ch) 进行输入操作就不会存在上述问题。因为当 cin.get(char) 到达EOF时,该函数不会将任何值赋给ch(即ch不会被用于存储非char值)。
| 属性 | cin.get(ch) | ch = cin.get( ) |
| 传递 输入字符 的方式 | 赋给参数ch | 将 函数返回值 赋给ch |
| 函数的返回值 (用于字符输入) |
istream对象 (执行向bool值的转换后,得到 true) |
int类型的字符编码 |
| 函数的返回值 (到达EOF时) |
istream对象 (执行向bool值的转换后,得到 false) |
EOF |
如果使用的是带有字符参数的版本,那么在进行字符拼接时将会更方便:
cin.get(ch_1).get(ch_2);这条语句将输入中的下一个字符赋给 ch_1 ,并将接着的下一个字符赋给 ch_2 。之所以可以这样处理,是因为 cin.get(ch_1) 返回的是一个cin对象,可以使用整个对象再次进行get( )的调用。
嵌套循环和二维数组
如果把一维数组看作一行数据,那么二维数组就是一个表格(既有数据行,也有数据列)。
尽管C++没有提供二维数组类型,但用户可以创建这样一个数组,让数组的元素本身就是数组。例如:
int maxtemps[4][5];上述声明说明:
- maxtemps是一个包含了 4个元素 的数组;
- 每个元素都是包含了 5个int类型元素 的数组。
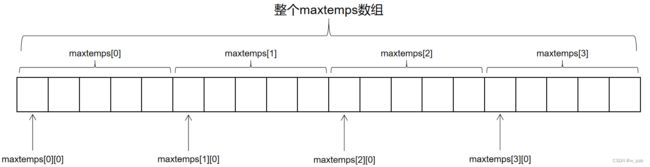
其中:
- maxtemps[0]即是maxtemps数组的第一个元素,本身也是由5个int类型元素组成的元素;
- maxtemps[0][0]是maxtemps[0]数组的第一个元素,本身是int类型。
因此,可以将二维数组看作一个表格,第一个下标表示行,第二个下标表示列:

打印二维数组maxtemps的所有内容:
for (int row = 0; row < 4; row++)
{
for (int col = 0; col < 5; ++col)
cout << maxtemps[row][col] << "\t";
cout << endl;
}初始化二维数组
参照一维数组的初始化方式(提供一个值列表),二维数组的初始化可以看作是一系列的一维数组的初始化:
int maxtemps[4][5] =
{
{1, 2, 3, 4, 5}, //初始化数组maxtemps[0]
{6, 7, 8, 9, 10}, //初始化数组maxtemps[1]
{11, 12, 13, 14, 15}, //初始化数组maxtemps[2]
{16, 17, 18, 19, 20} //初始化数组maxtemps[3]
};使用二维数组
例子:
#include
const int Cities = 5;
const int Years = 4;
int main()
{
using namespace std;
const char* cities[Cities] =
{
"厦门",
"浙江",
"昆明",
"上海",
"吉林"
};
int maxtemps[Years][Cities] = //数据是编的
{
{36, 37, 35, 30, 25},
{37, 38, 36, 31, 24},
{38, 36, 36, 31, 26},
{40, 39, 38, 33, 27},
};
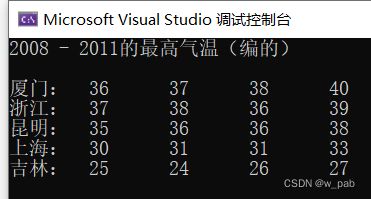
cout << "2008 - 2011的最高气温(编的)\n\n";
for (int city = 0; city < Cities; city++)
{
cout << cities[city] << ":\t";
for (int year = 0; year < Years; year++)
cout << maxtemps[year][city] << "\t";
cout << endl;
}
return 0;
} 程序执行的结果是:
【分析】
不同于之前的程序,该程序将列循环(城市索引)放在了外面,而将行循环(年份索引)放在了里面。
另一方面,该程序提供声明一个char指针数组来存储城市的名字。但是,使用char类型的二维数组也是可行的:
const char cities[Cities][25] =
{
"厦门",
"浙江",
"昆明",
"上海",
"吉林"
};这种写法规定了5个字符串的最大长度为24个字符,而数组本身存储的是这5个字符串的首字符的地址。
从这里可以看出,二维数组在进行元素修改时拥有更大优势(因为二维数组可以通过索引快速找到元素),而指针数组因为不用开辟多余的空间,所以更加经济。
除此之外,还可以使用string对象对城市名称进行存储:
const string cities[Cities] =
{
"厦门",
"浙江",
"昆明",
"上海",
"吉林"
};因为string类拥有自动调整大小的特性,因此在这种地方要比二维数组来得方便。
因为使用了const限定符,使用这里的字符串实际上是无法进行修改的。