【GAMES202】Real-Time Global Illumination(in 3D)—实时全局光照(3D空间)
一、SH for Glossy transport
1.Diffuse PRT回顾
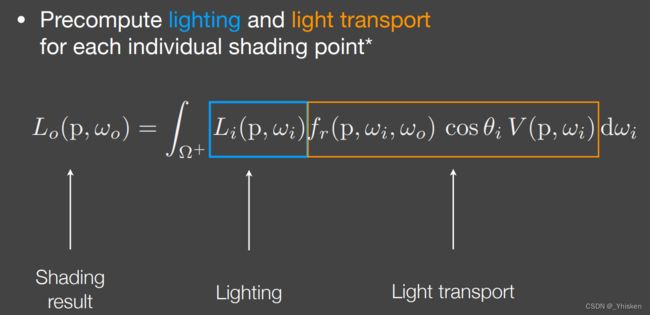
上篇我们介绍了PRT,并以Diffuse的BRDF作为例子分析了预计算的部分,包括Lighting和Light transport,如上图所示。 包括我们还提到了SH,可以用SH的有限阶近似拟合球面函数,然后计算。

这里和上篇的推导方式不太一样,我们上篇是把Lighting项用SH分解然后交换积分和求和符号,最后变成了两个向量的点乘。而这次我们把Lighting项用SH分解,把Light transport项也用SH分解,最后得到了两个求和,以及右边的两个基函数的乘积再积分(product integral) ,感觉不太一样?从O(n)变成了O(n2)?
这里就可以用到SH的性质,正交性,显然两个基函数的product integral的操作正如同把一个基函数投影到另一个基函数上一样,类比于三维空间中把x轴投影到y轴,结果是0,除非是把x轴投影到x轴,那么结果是1,由此我们知道,只有Bp和Bq是相同基函数的情况下,右边这个东西才不等于0而是等于1。
由此也就相当于两个一维向量组成的矩阵,但只有矩阵对角线上有值,那么仍然是O(n),我们的上篇的推导仍然成立。
2.Glossy PRT
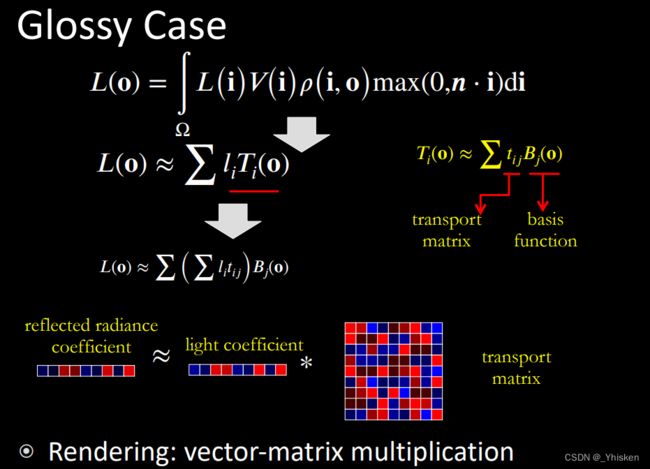
接下来看Glossy的情况,我们之前说Diffuse的PRT好做是因为,Diffuse的BRDF是一个常数,而Glossy的BRDF显然不是一个常数,它是一个完整的四维的函数。
这里我们仍然把Lighting投影到SH上,然后把Light transport也投影到SH上,但是最后得到的结果就不是简单的两个向量的点乘了,Ti变成了T(o),原因正是因为BRDF此时不再是常数了,此时任给一个方向o,我们都可以得到一个BRDF和相应的T(o),也就是说,不同的o得到的向量不同,也就是说我们最后得到的不再是一个向量Ti,而是一个函数T(o)。
换个角度理解,我们知道Diffuse的反射是和视角无关的,而Glossy则不同,Glossy和视角方向是有关的,这也符合最后得到的结果L(o)是一个关于观察方向o的函数。
那我们怎么处理呢?原本的四维被我们投影到二维的SH上变成了二维的Light transport,那我们可不可以再做一次投影呢?答案是可以,只不过这时候transport就不再是一个向量了,而是一个矩阵,如上图所示。最后的结果自然是一个关于观察方向o的函数L(o)了,也就是一个向量。

当然Glossy的PRT也有代价,首先是预计算的存储,如果想用前五阶的SH拟合,那就是25*25=625个基函数的计算结果。其次因为不再是向量与向量相乘,而是向量与矩阵相乘,计算的开销也会增加。正常情况下人们通常会用3,4,5阶的SH,相应的高频BRDF使用的阶数就高一些。
对于特别高频的情况(接近镜面反射),一般会采用其它的基函数来投影,因为SH表达高频的效果很差,或者另一种解决思路就是直接采样就可以了,因为镜面反射已经知道了是如何反射的。
3.PRT for Interreflections and Caustics

PRT同样可以做Interreflection,也就是自身反射自身的效果。
我们先总结一下传播路径,如上图所示,其中LE表示光源(Light)直接到达眼睛(Eye),LGE自然表示光源(Light)打到Glossy的物体,再进入眼睛(Eye),一个通用的表达L(D|G)*E,因为物体要么是Diffuse的要么是Glossy(Specular可以当作特殊的Glossy)的,*代表可以反射多次,然后进入人的眼睛。
如上图的茶壶所示,在多了一次光线的bounce之后,壶身可以反射到自身的壶嘴,那自然bounce越多反射的也就越多,也就越接近真实的光线传播。
另一种常见的传播路径,Caustics(焦散),通常用LS*(D|G)*E表示,它表示光源先打到Specular也就是非常光滑的表面上,再打到Diffuse物体上再传到眼睛被看到。如上图的金属环。
通过观察我们可以发现任何的Transport path都可以被分成Lighting和Light transport两部分,也就是L和除L外的东西。也就是说无论Light transport多复杂我们都可以用PRT的方式进行预计算。

回顾一下Ti项的预计算,我们之前提到了可以把如图中所示的式子当作一种投影,而另一种理解思路,我们发现这个式子很像渲染方程,唯一不同的是Li变成了基函数,那我们可以就可以理解成用这些不同基函数形式的光照去照亮整个物体,如图所示,只不过每个光照会有些奇怪罢了,但是把它们合在一起,仍然是正确的完整的光照。(红色为+,蓝色为-,黑色为0)

对于不同的BRDF,我们只要能把light transport表示出来,都可以通过预计算来实时渲染。即使为如上图所示的右下角的茶壶,不同的位置上有不同的BRDF,此时虽然任何一个顶点的BRDF仍是四维,但整个物体变成了六维的函数,但是我们仍然可以通过PRT计算。
4.PRT的局限
⦿ 球谐函数只适合于描述低频的函数,描述高频要用很高阶的基函数
⦿ 因为预计算,所以只适用于静态场景。材质,场景都不能发生改变
⦿ 大量的预计算数据需要存储和读取0
二、Wavelet—小波
⦿ Wavelet
⦿ Zonal Harmonics
⦿ Spherical Gaussian (SG)
⦿ Piecewise Constant
事实上,在SH之后,人们研究了许多基函数,用来表示其他函数,如上面所列举的一部分。

我们简单介绍其中的一种,Wavelet—小波,并且小波有很多种,这里我们介绍的是2D Haar小波。与SH相同,它也是一系列基函数,但不同的是,SH定义在球面上,而它定义在图像块上,并且不同的小波定义域不同,如图中只有黑白的地方才是定义域,并且小波支持全频率的表示。其次,与SH不同的是,我们用SH近似的时候是取了SH有限阶的基函数去近似,而小波不同,我们把函数投影到小波的每个基函数上,会发现有些基函数的系数接近0,这样我们就可以定义一个系数大小,小于一定值的基函数丢掉就可以了。

自然的,由于小波定义在图像块上,那自然不能用Sphere map来做光照,而是改用Cubemap,并且对Cubemap的每张图单独做小波变换,大致思路为一张图划分为四块,左上角存储低频信息,然后其余为高频信息的小波变换保留下来的非0系数项,接着依次不断划分,如上图所示。

可以看到,小波还原出来的效果比SH好一些,包括高频的阴影。
但小波有一个缺点,就是它不支持光源的旋转,而不像SH的简单的旋转性质。
三、Real-Time Global Illumination (in 3D)
全局光照在真实感渲染中有着举足轻重的作用,如果没有全局光照,场景中会出现许多死黑的地方,所以做全局光照是必然的,回顾我们在GAMES101里的Blinn-Phong模型,它的全局光照是做法是把间接光照ambient当成一个常数,然后假设场景所有地方所受间接光相同并且和Normal也没有任何关系,但显然,这是非常不准确的做法。
 [Image courtesy of Prof. Henrik Wann Jensen]
[Image courtesy of Prof. Henrik Wann Jensen]
在实时渲染中,人们指的全局光照中的所谓间接光照,指的就是光线比直接光照多弹射一次的间接光照,而不是弹射很多次的,如上图所示。
Reflective Shadow Maps (RSM)
(1)Idea
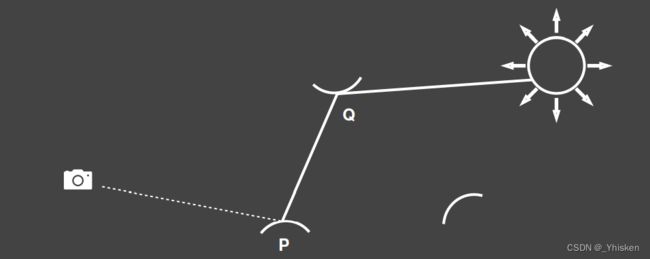 [Image courtesy of Prof. Henrik Wann Jensen]
[Image courtesy of Prof. Henrik Wann Jensen]
那么回顾我们在GAMES101里面提到的,在P点考虑接受的光照,有从光源接收到的的直接光照那就是光源的直接光照,有从Q点接收到的间接光照,那也就是Q点接收光源的光后反射到自己的光就好像Q点也是一个光源一样。
所以实际上我们并不区分哪些是直接照到的,哪些是反射来的,而是把Q当作次级光源来计算。

如上图所示,太阳标记表示被直接光照照到的部分,它们在下一次弹射的时候将被当作次级光源去照亮其它物体。
如上图,p点接收不到光源的直接光照,但可以接收到第一次获得的次级光源的光照,然后被照亮。
(2)Key Observations
有了思路,我们需要解决中间的一些问题
• 首先,我们怎么知道光源直接照到了哪些地方呢?
显然我们一下就可以想到借助Shadow Map。这个时候从Shadow Map上的每个像素对应的场景中的Area都会被当成次级面光源去照亮点p。
• 其次,我们怎么知道一个次级面光源对着色点(点p)的光照贡献呢
 对光源直接采样
对光源直接采样
我们想到在GAMES101介绍蒙特卡洛积分对半球采样的时候,我们当时说因为会导致浪费许多路径,所以我们改写了渲染方程,把对立体角的积分改成了对光源上面积dA的积分,直接采样光源避免了浪费。而在这里我们同样可以采取这种方法,在p点对所有有贡献的次级光源采样即可。
但这里有一个问题,我们在p点求各个次级光源的贡献,实际上我们是以p点作为了观察点,而不是我们的Camera,所以我们如果不知道出射方向,那就没法计算着色了。但是这里我们会做一个假设,我们假设所有的反射物(reflector)都是Diffuse的,这样就和观测方向没有关系,我们从p点还是从Camera看都是相同的。但注意,我们不需要假设接收物都是也是Diffuse的,也就是说虽然次级光源被我们认为是Diffuse,但是点p并不需要认为是Diffuse的。
 对光源面积积分的渲染方程
对光源面积积分的渲染方程
如上图所示是我们之前提到的改写后的渲染方程,从立体角积分变成了对面积的积分,其实如果我们如果知道了Shadow Map上的一个像素对应的面积就可以直接计算了,不需要积分dA。 现在需要知道的就是,从q点打到p点的Radiance是多少,也就是上图所示的Li(q→p)项。

由于之前假设的q点是Diffuse的,那么q点的BRDF就很好求,就是ρ/π ,我们之前推导过。那出射的Radiance自然就是BRDF乘以Irradiance,Irradiance直接用光源的Φ除以单位面积dA就可以了。并且dA可以消掉,于是得到最终的公式结果如上图白框所示。(这里的白框里的公式是Paper的原公式,可以看到闫令琪老师非常自信的把它的4次方改成了2次方,并且说Paper上绝对写的是错的立flag吃键盘,据闫令琪老师说这个错的原因在于无脑加了一次平方衰减,而实际上这个衰减的假设是错的)
这里仍然存在这问题,首先我们发现改写后的渲染方程的Visibility项无法得到,我们不可能对每个次级光源和着色点之间都生成一张Shadow Map来判断可见性,于是人们直接放弃了Visibility项,就认为是可见的。
(3)Tips
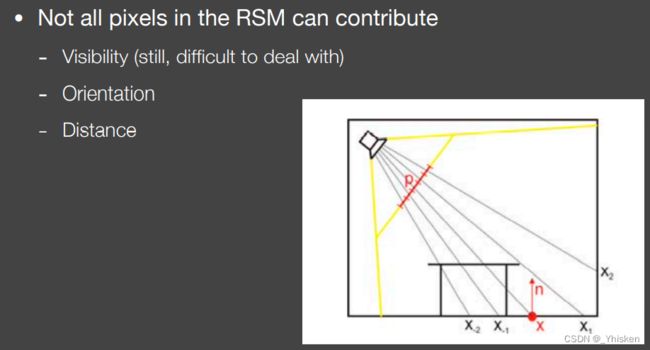
RSM仍然有一些可以优化的点,比如我们之前提到的次级光源的Visibility项,以及根据法线判断哪些光源根本不可能对着色点有贡献,比如上图的在桌子上的次级光源(x-1,x-2)就不可能对x点有贡献。其次我们之前看到了,改写渲染方程有距离平方衰减项,所以一定距离范围外的次级光源我们自然也没必要考虑,因为太小了。

离着色点一定距离范围外的次级光源不考虑?我们自然不能对每个着色点p把Shadow Map上所有次级光源遍历计算距离再排序,再删除,这是很大的工程量,于是有了RSM另外一个大胆的假设。
我们目的是找到在世界坐标下距离着色点p距离近的一些点。于是我们把p点投影到Shadow Map上,然后在Shadow Map上离点p近的像素/深度接近的像素,我们就认为在世界坐标下距离也接近。这样就可以有效的加速这一过程。当然查询可能仍然很慢,我们可以随机采样,至于采样点的选取,采样点的数量,采样的权重分布,这些都可以借鉴PCSS等之前提到过的其它方法,这里因实际情况而有所不同,但我们可以知道的是,这种方法可以有效加速RSM。
(4)Summary
RSM相比于普通的Shadow Map多存储了什么呢?那无非是我们之前说思路的时候用到的哪些信息。Depth深度,这是Shadow Map原本就存储的。除此之外还有,世界坐标来判断距离(算Shading的时候需要使用),反射物的法线(计算cos项),光源的辐射通量。
 GDC Vault - In-Game and Cinematic Lighting of The Last of Us
GDC Vault - In-Game and Cinematic Lighting of The Last of Us
RSM的效果被用在手电筒上非常不错,而且因为手电筒覆盖范围较小,不需要太大的RSM,开销比较小 。

RSM的优点是比较容易实现,因为它本身其实就是Shadow Map。
那缺点也很容易想到,Shadow Map有的缺点它也有。有多少个直接光源就需要多少个RSM,所以多光源开销大。 其次我们说了,无法考虑Visibilty项,于是不考虑,所以不够真实。还有,RSM做了很多假设包括:反射物都是Diffuse,SM近似的世界空间坐标距离,这些都会对渲染质量有一定影响。最后RSM的采样率和质量的平衡问题,这是所有采样方法都有的问题。
参考
GAMES202_Lecture_07 (ucsb.edu)
Lecture7 Real-time GLobal Illumination (in 3D)_哔哩哔哩_bilibili