python报org.apache.spark.SparkException: Python worker failed to connect back.
org.apache.spark.SparkException: Python worker failed to connect back.
22/12/06 15:04:14 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
22/12/06 15:04:27 ERROR Executor: Exception in task 7.0 in stage 0.0 (TID 7)
org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:189)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:164)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:131)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:535)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:189)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:176)
... 14 more
22/12/06 15:04:27 WARN TaskSetManager: Lost task 7.0 in stage 0.0 (TID 7) (172.23.48.1 executor driver): org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:189)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:164)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:131)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:535)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:189)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:176)
... 14 more
22/12/06 15:04:27 ERROR TaskSetManager: Task 7 in stage 0.0 failed 1 times; aborting job
Traceback (most recent call last):
File "E:\学习资料\编程项目\Python\test\pythonProject1\pyspark\03_数据计算_map方法.py", line 26, in <module>
print(rdd2.collect())
File "E:\module\learn\Python\lib\site-packages\pyspark\rdd.py", line 1197, in collect
sock_info = self.ctx._jvm.PythonRDD.collectAndServe(self._jrdd.rdd())
File "E:\module\learn\Python\lib\site-packages\py4j\java_gateway.py", line 1321, in __call__
return_value = get_return_value(
File "E:\module\learn\Python\lib\site-packages\py4j\protocol.py", line 326, in get_return_value
raise Py4JJavaError(
py4j.protocol.Py4JJavaError: An error occurred while calling z:org.apache.spark.api.python.PythonRDD.collectAndServe.
: org.apache.spark.SparkException: Job aborted due to stage failure: Task 7 in stage 0.0 failed 1 times, most recent failure: Lost task 7.0 in stage 0.0 (TID 7) (172.23.48.1 executor driver): org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:189)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:164)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:131)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:535)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:189)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:176)
... 14 more
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.failJobAndIndependentStages(DAGScheduler.scala:2672)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2(DAGScheduler.scala:2608)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$abortStage$2$adapted(DAGScheduler.scala:2607)
at scala.collection.mutable.ResizableArray.foreach(ResizableArray.scala:62)
at scala.collection.mutable.ResizableArray.foreach$(ResizableArray.scala:55)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:49)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:2607)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGScheduler.$anonfun$handleTaskSetFailed$1$adapted(DAGScheduler.scala:1182)
at scala.Option.foreach(Option.scala:407)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:1182)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.doOnReceive(DAGScheduler.scala:2860)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2802)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:2791)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:49)
at org.apache.spark.scheduler.DAGScheduler.runJob(DAGScheduler.scala:952)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2228)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2249)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2268)
at org.apache.spark.SparkContext.runJob(SparkContext.scala:2293)
at org.apache.spark.rdd.RDD.$anonfun$collect$1(RDD.scala:1021)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151)
at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112)
at org.apache.spark.rdd.RDD.withScope(RDD.scala:406)
at org.apache.spark.rdd.RDD.collect(RDD.scala:1020)
at org.apache.spark.api.python.PythonRDD$.collectAndServe(PythonRDD.scala:180)
at org.apache.spark.api.python.PythonRDD.collectAndServe(PythonRDD.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)
at py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)
at py4j.Gateway.invoke(Gateway.java:282)
at py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)
at py4j.commands.CallCommand.execute(CallCommand.java:79)
at py4j.ClientServerConnection.waitForCommands(ClientServerConnection.java:182)
at py4j.ClientServerConnection.run(ClientServerConnection.java:106)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.spark.SparkException: Python worker failed to connect back.
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:189)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:109)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:124)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:164)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:365)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:329)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:136)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:548)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1504)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:551)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more
Caused by: java.net.SocketTimeoutException: Accept timed out
at java.net.DualStackPlainSocketImpl.waitForNewConnection(Native Method)
at java.net.DualStackPlainSocketImpl.socketAccept(DualStackPlainSocketImpl.java:131)
at java.net.AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:535)
at java.net.PlainSocketImpl.accept(PlainSocketImpl.java:189)
at java.net.ServerSocket.implAccept(ServerSocket.java:545)
at java.net.ServerSocket.accept(ServerSocket.java:513)
at org.apache.spark.api.python.PythonWorkerFactory.createSimpleWorker(PythonWorkerFactory.scala:176)
... 14 more
进程已结束,退出代码为 1
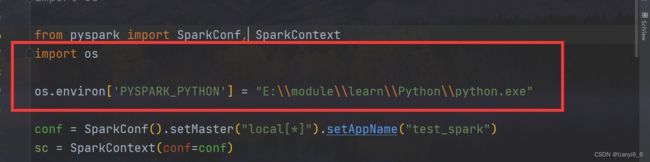
报以上错误需要导包,需要添加解释器位置
解决方法:
添加python解释器的路径
import os
os.environ['PYSPARK_PYTHON'] = "E:\\module\\learn\\Python\\python.exe"
结果:
运行成功
E:\module\learn\Python\python.exe E:/学习资料/编程项目/Python/test/pythonProject1/pyspark/03_数据计算_map方法.py
22/12/06 15:09:57 WARN Shell: Did not find winutils.exe: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset. -see https://wiki.apache.org/hadoop/WindowsProblems
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/12/06 15:09:57 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[10, 20, 30, 40, 50]
进程已结束,退出代码为 0