【OCR】文本检测方案 TextFuseNet解读
TextFuseNet: Scene Text Detection with Richer Fused Features
PDF Link Github Code
一些总结,非作者文章内容:
实质上是去通过文本检测中多级别的目标融合的方法来提升检测效果的,核心价值其实分两点来看
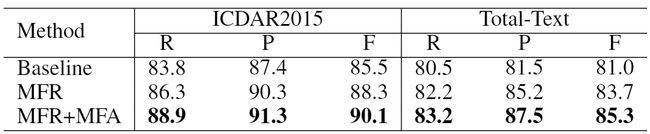
- 提出了一种利用Mask-RCNN的流程以及多分枝的结构实现多层特征融合方案,从全局特征->词特征+字符特征来提升文字检测效果。性能优势非常非常明显,但是对应的推理速度相对较慢ResNet-50的backbone下只有7-8FPS。
- 另一个就是针对没有字符标注的情况下给出了一个相对直观的弱监督的方式来推进训练。
总体来看提出了方案,但是方案类似推土机(个人观点,勿喷)…
Section 1 介绍
当前的场景文本检测主要分为两种不同的类型,基于字符和基于词的形式的检测。前者的问题是文本中字符数量很多、检测+融合的速度慢导致最终效果很不理想(但是没说效果不好欸)。后者利用通用目标检测的pipeline来进行,尽管简单但是往往在对任意形状文本的支持不是太好。另外也有一些基于实例分割的方法,但是主要也存在两种主要缺陷。首先是在有限的RoI框缺少全局视觉信息,导致检测效果不佳。此外,这类方法没有对不同层级的的语义信息进行建模,造成假阳性的问题。可以参考下图。

文本提出了一个新的场景文本检测框架叫TextFuseNet,参考了Mask-RCNN、Mask-TextSpotter然后将认为定义为一个实例分割的任务。文章重构了Mask-RCNN,使得最终的文字检测能够用到融合三个levels上的特征表示(字符、词、全局)。
具体来看,首先引入了一个额外的语义分割分支用于提取和保留全局特征表示。全局语义特征信息后面会被用于指导检测和MASK分支的目标值预测。然后尝试在MASK-RCNN框架中的检测分支和MASK分支提取字符和词级别的特征。与原始的MASK-RCNN相比,TextFusedNet同时检测和分割字符、词。针对全局特征,引入了多路径特征融合结构用于学习一个更具有判别力的特征表示。
针对当前数据集往往缺少单个字符的标签标记信息,进一步开发了一个弱监督学习流程来从词标注数据集中生成字符集别的标注信息。
贡献分为三块:
- 提出了TextFuseNet,融合三个级别的特征引入多路径特征融合。
- 基于提出的框架,给出来一个弱监督的学习方法,使得模型能够仅从词标注信息中进行学习而不要详细的字符标注信息。
- SOTA。
Section 2 相关工作
Character-based methods
通用的字符检测器有SWT, MSER, FASText,通过检测候选字符,然后利用一个字符/非字符的分类器来去除假阳性。最后剩下的字符依据先验知识或者聚类、分组算法进行整合。但是大多数的字符检测方法需要精巧的设计和多阶段的处理。这会导致最终会模型很复杂,过程中产生的错误也会累计,最后导致这类方法耗时且性能不佳。
Word-based methods
受到通用文本检测的方法,基于词的检测方法直接检测词文本。CTPN, TextBoxes++之类方法很多,但是这些方法都仅适用于水平或者多角度的问题。
为了解决任意角度文本检测的问题,许多基于实例分割的模型被提出,SPCNet, PSENet之类的很多。
Section 3 方法
3.1 Framework
下图表述了TextFuseNet的完整结构。首先提取多层级的特征表示,然后利用多路径特征融合来实现文本检测。主要来看,框架大致有五个模块:
- FPN 用于提取多阶段特征
- RPN 生成文本建议框
- 语义分割分支捕捉全局语义信息
- 检测分支用于检测字符与词文本
- Mask分时用实例分割字符与词文本

在TextFuseNet中,与Mask-RCNN以及Mask-TextSpotter一致,采用了ResNet作为backbone以及FPN。此外我们使用了RPN来生成文本建议框用于后续的检测和MASK分支。然后为了提取多层特征表示,我们采用了以下的实现。
- 首先,我们引入了一种新的语义分割分支,对输入图像进行语义分割,帮助获得全局级的特征。
- 在检测分支中,通过预测类别和boudning box回归的方法对文本的提议框进行精细化,并提取、融合了单词和全局级别的特征,从而同时检测单词和字符。与当前的常规方法不一样的地方在于常规方法每个提议框只检测一个字符或者问本词,详细的见3.2章节。
- 在提取出多个特征后,我们提出了一种多路径融合结构来融合不同的特征来检测任意形状的文本,细节见3.3章节。
3.2 Multi-level Feature Representation
通常来说多级别的特征很容易提取到,但是我们需要在特征提取部分有一个新网络来帮助获取全局特征。因此我们提议进一步使用一个语义分割分支。语义分割分支基于FPN的输出,融合了所有层次的特征到一个统一的表征中去从而获得一个全局的分割结果。在实际中,使用了1x1卷积来对齐通道数量,结合resize来保证尺寸一致。
3.3 Multi-path Fusion Architecture
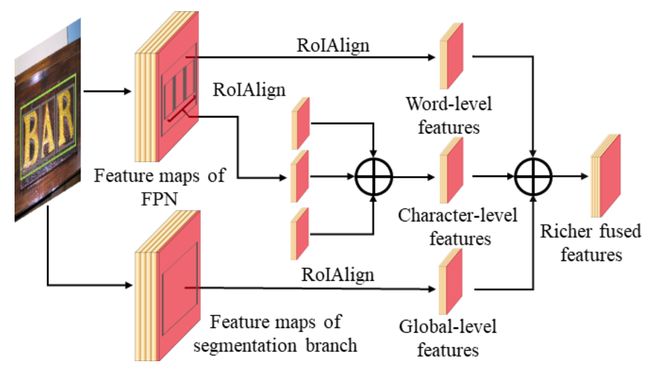
在RPN中从不同的路径中提取了全局、词级别的特征,对这些特征进行融合,使得最终能够输出字符和词检测结果。注意这里并没有加入字符特征,因为字符特征在检测分支之前都还没有被框出。在实际落实中,在给定一个生成的提议框,我们使用RoIAlign在7x7的特征图上来提取全局和词特征。然后用element-wise add和一个3x3 + 1x1的两个卷积层,这么处理后的特征将被用于分类和框回归。
在MASK分支,可以使用三个不同级别的特征进行融合用于实例分割。下图展示了详细的多路径融合的结构。
公式化的来看,给定一个词标记为 r i r_i ri,首先识别其中的字符结果 C i C_i Ci,通过字符与提议框的IoU来判断是否包含。使用 c j c_j cj来表示字符,那么字符集 C i C_i Ci是否属于这个标记就可以被表示为如下式
C i = { c i ∣ b i ∩ b j b j > T } C_i = \left\{ c_i | \frac{b_i \cap b_j }{b_j} > T \right\} Ci={ci∣bjbi∩bj>T}
其中 b i bi bi和 b j b_j bj表示 r i r_i ri回归框和字符实例 c j c_j cj, T T T为阈值,设置为0.8。
由于字符的实例并不固定,可以从没有到上百,因此尝试融合字符的集合 C i C_i Ci对应的特征融合为一个统一的表示。具体是线上首先用了RoIAlign在14x14大小的特征图捞了 C i C_i Ci的特征,然后吧这些特征通过element-wise add + 3x3 + 1x1进行融合。
Overall Objective
公式化的来看,损失函数可以被定义为
L = L r p n + L s e g + L d e t + L m a s k L = L_{rpn} + L_{seg} + L_{det} + L_{mask} L=Lrpn+Lseg+Ldet+Lmask
各个部分分别为RPN,语义分割分支,检测分支以及MASK分支对应的损失。
3.4 Weakly Supervised Learning
由于TextFuseNet的形式为同时检测词文本和字符,实现框架的训练就需要字符级别的标注信息。但是正如之前的描述,字符级别的标注数据集并不存在。考虑到时间和成本开销,尝试去利用弱监督学习的方法来指导学习训练。方案大致为首先利用弱监督数据集训练(这里作者的意思大概是这个数据集内包含的字符和词文本两种级别的数据)的预训练模型中搜索字符级别训练样本。然后,在只有词标注数据的数据集 A A A中利用预训练好的模型 M M M去搜索字符级别的训练样本。
更具体地来看,首先用 M M M在数据集 A A A上预测,对于数据集 A A A中的每一个图像数据中会生成以下候选样本:
R = { r o ( c 0 , s 0 , b 0 , m 0 ) , r 1 ( c 1 , s 1 , b 1 , m 1 ) , ⋯ , r i ( c i , s i , b i , m i ) , ⋯ } R = \left\{ r_o(c_0, s_0, b_0, m_0), r_1(c_1, s_1, b_1, m_1), \dotsm, r_i(c_i, s_i, b_i, m_i), \dotsm \right\} R={ro(c0,s0,b0,m0),r1(c1,s1,b1,m1),⋯,ri(ci,si,bi,mi),⋯}
其中 c i , s i , b i , m i c_i, s_i, b_i, m_i ci,si,bi,mi分别表示 r i r_i ri中第 i i i个字符的预测类别、置信度、回归框以及mask掩膜。然后利用置信度阈值以及IoU等方式将生成的假阳性样本过滤掉,具体如下
P = { ( c i , s i ) ∣ c i ∈ C a n d s i > S a n d ( m i ∩ g i ) m i > T } P = \left\{ (c_i, s_i) | c_i \in C \ \mathbf{and} \ s_i > S \ \mathbf{and} \ \frac{(m_i \cap g_i)}{m_i} > T \right\} P={(ci,si)∣ci∈C and si>S and mi(mi∩gi)>T}
其中 C C C表示所有被检测出来的字符类别, S S S表示判断正阳性框的置信度阈值。 ( m i ∩ g i ) m i \frac{(m_i \cap g_i)}{m_i} mi(mi∩gi)表示词级别标注和候选字符标注的重合度(后者在前者内部的比例),对应的阈值设置为 T T T。这俩值一个是0.1一个是0.8。
Section 4 实验
具体不讲了,数据集用了SynthText, ICDAR2013, ICDAR2015, Total-Text, CTW-1500。
训练分成三个阶段,首先在SynthText上预训练(包含字符和词标注),然后再ICDAR2015, Total-Text, CTW-1500上搜索字符标注样本,然后拿这些字符标注数据去finetune模型。
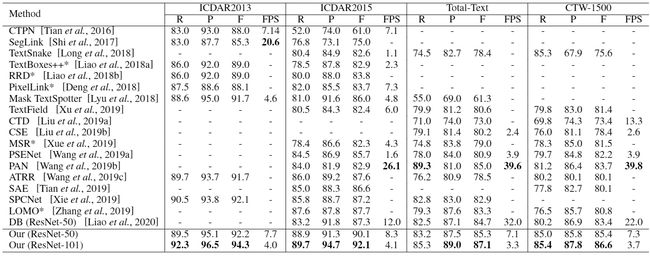
最终性能表现见下面的表。
Section 5 总结
总结!