【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!
文章目录
- 一、爬虫对象-豆瓣音乐TOP250
- 二、python爬虫代码讲解
- 三、同步视频
- 四、获取完整源码
一、爬虫对象-豆瓣音乐TOP250
您好,我是 @马哥python说 ,一名10年程序猿。
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣音乐TOP250排行榜数据:https://music.douban.com/top250
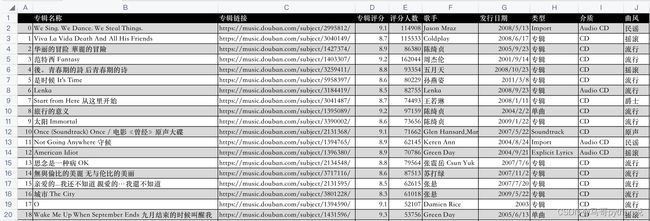
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python实现。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣音乐网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
name = music.select('.pl2 a')[0].text.replace('\n', '').replace(' ', ' ').strip() # 专辑名称
music_name.append(name)
url = music.select('.pl2 a')[0]['href'] # 专辑链接
music_url.append(url)
star = music.select('.rating_nums')[0].text # 音乐评分
music_star.append(star)
star_people = music.select('.pl')[1].text # 评分人数
star_people = star_people.strip().replace(' ', '').replace('人评价', '').replace('(\n', '').replace('\n)',
'') # 数据清洗
music_star_people.append(star_people)
music_infos = music.select('.pl')[0].text.strip() # 歌手、发行日期、类型、介质、曲风
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['专辑名称'] = music_name
df['专辑链接'] = music_url
df['专辑评分'] = music_star
df['评分人数'] = music_star_people
df['歌手'] = music_singer
df['发行日期'] = music_pub_date
df['类型'] = music_type
df['介质'] = music_media
df['曲风'] = music_style
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
需要说明的是,豆瓣页面上第4、5、6页只有24首(不是25首),所以总数量是247,不是250。
不是爬虫代码有问题,是豆瓣页面上就只有247条数据。
三、同步视频
同步讲解视频:【python爬虫】利用python爬虫爬取豆瓣音乐TOP250的数据!
四、获取完整源码
附完整源码:【python爬虫案例】利用python爬虫爬取豆瓣音乐TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!