Python VS R | 批量处理EXCEL年终报表
前情回顾:五分钟学会四种宽数据转长数据方法
在之前的博客中,我们分享过宽数据转长数据的四种方法。今天,就以一个具体案例来介绍一下宽数据转长数据的实际应用吧

目录
-
- 一、案例需求介绍
- 二、需求分析与实现
-
- 2.1 需求分析
- 2.2 逐步实现
- Python版全部代码
- R版本全部代码
一、案例需求介绍
某公司现有若干年度报表
每个文件的部分内容如下两张图所示(暂且称第一张图为图1)
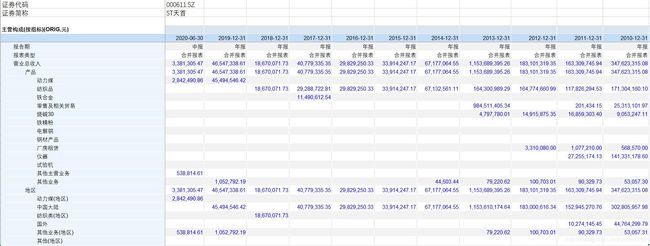
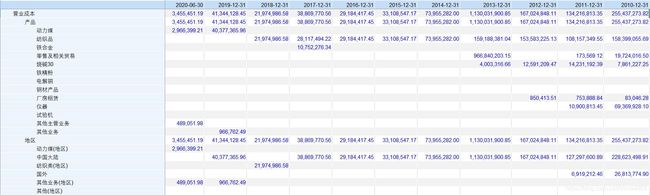
考虑篇幅限制,以上仅展示了营业总收入和营业成本这两个指标的内容,除此之外还有毛利及毛利率指标,数据排列方式均和上图相同。
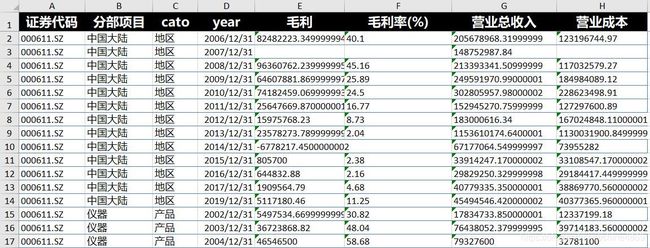
现老板想要将这些年度报表,合并成如下样式(暂且称为图2)
二、需求分析与实现
咋一看从图1转为图2好像挺复杂的,但只要知道宽数据转长数据这一知识点,问题就能迎刃而解。
2.1 需求分析
首先,我们简单理一理图2各字段含义
| 字段名 | 字段含义 |
|---|---|
| 证券代码 | 可由文件名直接获取 |
| 分部项目 | 产品及地区以下所有的项目,例如动力煤、纺织品等 |
| cato | 区分分部项目的来源 |
| year | 报表日期,注意图2为纵向排列 |
| 营业总收入 | 所有分部项目的营业总收入汇总,注意图2纵向排列,且为一列 |
| 营业成本 | 所有分部项目的营业成本汇总,注意图2纵向排列,且为一列 |
| 毛利 | 所有分部项目的毛利汇总,注意图2纵向排列,且为一列 |
| 毛利率(%) | 所有分部项目的毛利率汇总,注意图2纵向排列,且为一列 |
转换的关键点:如果将图1中每个分部项目的营业总收入都看作一个向量,那么图2则是将各项目的营业总收入进行拼接拉直,形成一列向量。同时,也需要将日期进行转置处理!
这就运用到宽转长运算了!不了解的小伙伴可参照链接博客学习。考虑到营业总收入、营业成本、毛利及毛利率这四个指标数据内容排列方式一致,故只需解决其中一个,其他类比即可。因此,我们以营业总收入为例,理出如下预处理思路:
1. 以产品与地区两个关键词进行分割定位,分别取出各自标签以下所有项目的营业总收入数据,记为data1,data2
2. 将data1与data2进行宽转长运算,并加上各自的cato标签(产品/地区),便于区别项目来源。
3. 纵向合并data1与data2,得到合并数据all_data
在所有指标数据均按上述处理后,根据cato、year等字段进行横向拼接,即可得到我们需要的数据啦~
2.2 逐步实现
以000611.SZ.xlsx数据进行案例演示
1、读取数据,考虑每个指标下均有产品与地区,这里先定位营业总收入与营业成本所在位置,再进行取数
import pandas as pd
import numpy as np
data = pd.read_excel('./Desktop/000611.SZ.xlsx',header=None)
#去除第一列的空格
data[0] = np.char.strip(list(data[0]))
#由于每个指标下均有产品与地区,这里先定位营业总收入与营业成本的位置
income_row = data[data[0] == '营业总收入'].index.tolist()[0]
expense_row = data[data[0] == '营业成本'].index.tolist()[0]
#取出所有项目的营业总收入数据
item_loc_select = data.iloc[income_row:expense_row, 0]
item_row = item_loc_select[item_loc_select == '产品'].index.to_list()[0]
loc_row = item_loc_select[item_loc_select == '地区'].index.to_list()[0]
date = list(data.loc[4, 1:].map(lambda x: x.strftime('%Y-%m-%d')))
date.insert(0, '分部项目')
#取出产品下所有项目的营业总收入
item_data = data.loc[(item_row+1):(loc_row-1), :]
item_data.columns = date
#取出地区下所有项目的营业总收入
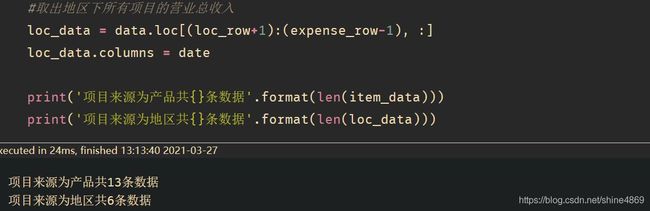
loc_data = data.loc[(loc_row+1):(expense_row-1), :]
loc_data.columns = date
print('项目来源为产品共{}条数据'.format(len(item_data)))
print('项目来源为地区共{}条数据'.format(len(loc_data)))
2、对产品与地区数据进行宽转长运算,并添加cato字段区分项目来源
#取出所有项目的营业总收入数据
item_loc_select = data.iloc[income_row:expense_row, 0]
item_row = item_loc_select[item_loc_select == '产品'].index.to_list()[0]
loc_row = item_loc_select[item_loc_select == '地区'].index.to_list()[0]
date = list(data.loc[4, 1:].map(lambda x: x.strftime('%Y-%m-%d')))
date.insert(0, '分部项目')
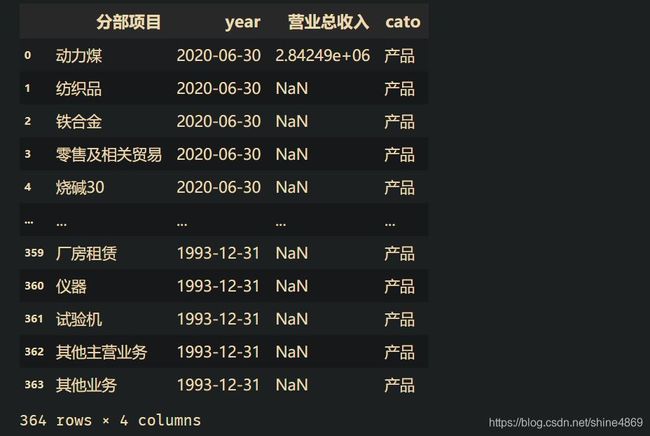
#取出产品下所有项目的营业总收入
product_data = data.loc[(item_row+1):(loc_row-1), :]
product_data.columns = date
product_data = product_data.melt(id_vars='分部项目', var_name='year', value_name='营业总收入')
col_name = product_data.columns.tolist()
product_data['cato']='产品'
#取出地区下所有项目的营业总收入
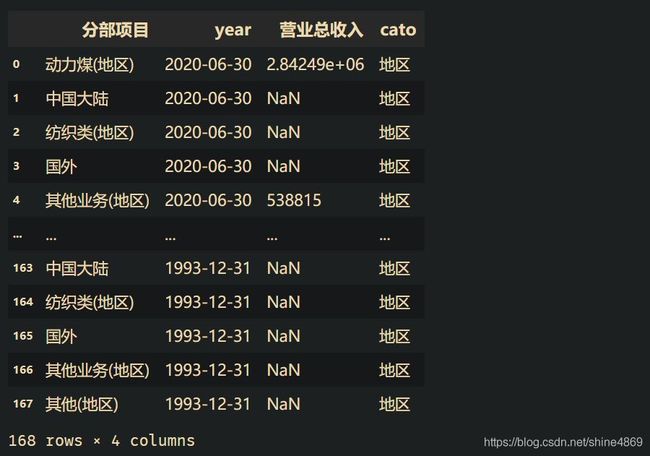
loc_data = data.loc[(loc_row+1):(expense_row-1), :]
loc_data.columns = date
loc_data = loc_data.melt(id_vars='分部项目', var_name='year', value_name='营业总收入')
col_name = loc_data.columns.tolist()
loc_data['cato']='地区'
print(product_data)
print(loc_data)
3、合并产品与地区数据
#纵向合并产品与地区数据
all_data = pd.concat([product_data,loc_data],ignore_index=True)
all_data
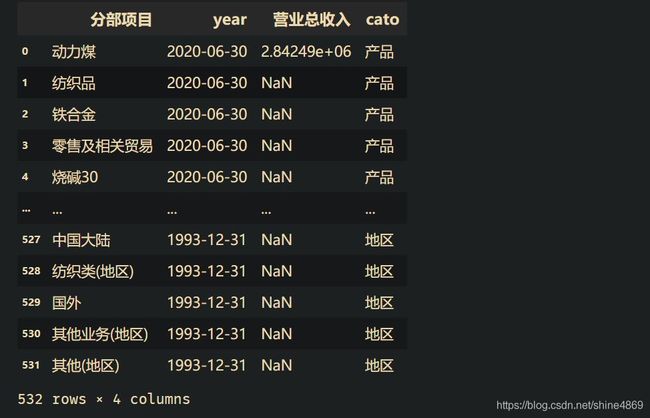
营业总收入所有数据处理完毕!其他指标处理方式同上,将其封装为函数,全部代码如下
Python版全部代码
import os
import pandas as pd
import numpy as np
file_path = './Desktop/上市/'
#date为日期列名,cato为产品/地区,code为证券代码,category为指标名
def get_data(data , date, start_row, end_row, cato, code, category):
item_data = data.loc[(start_row+1):(end_row-1), :]
item_data.columns = date
item_data = item_data.melt(id_vars='分部项目', var_name='year', value_name=category)
col_name = item_data.columns.tolist()
col_name.insert(0, '证券代码')
col_name.insert(1, 'cato')
item_data = item_data.reindex(columns=col_name)
item_data['cato'] = cato
item_data['证券代码'] = code
return item_data
def transform_data(data , start_row, end_row, code, category):
item_loc_select = data.iloc[start_row:end_row, 0]
item_row = item_loc_select[item_loc_select == '产品'].index.to_list()[0]
loc_row = item_loc_select[item_loc_select == '地区'].index.to_list()[0]
date = list(data.loc[4, 1:].map(lambda x: x.strftime('%Y-%m-%d')))
date.insert(0, '分部项目')
product_data = get_data(data , date, item_row, loc_row, '产品', code, category)
loc_data = get_data(data , date, loc_row, end_row, '地区', code, category)
all_data = pd.concat([product_data, loc_data], axis=0)
return all_data
def main(file_path):
# 用于存储所有文件数据
all_file_data = pd.DataFrame()
all_file = os.listdir(file_path)
for file in all_file[:-1]:
code = file[:-5]
data = pd.read_excel(file_path+file, header=None)
# 去除第一列的空格
data[0] = np.char.strip(list(data[0]))
# 定位四个指标位置
income_row = data[data[0] == '营业总收入'].index.tolist()[0]
expense_row = data[data[0] == '营业成本'].index.tolist()[0]
profit_row = data[data[0] == '毛利'].index.tolist()[0]
profit_rate_row = data[data[0] == '毛利率(%)'].index.tolist()[0]
income = transform_data(data , income_row, expense_row, code, '营业总收入')
expense = transform_data(data , expense_row, profit_row, code, '营业成本')
profit = transform_data(data , profit_row, profit_rate_row, code, '毛利')
profit_rate = transform_data(data , profit_rate_row, len(data)-4, code, '毛利率(%)')
# 合并四个指标值
part_1 = pd.merge(income, expense, on=['证券代码', '分部项目', 'cato', 'year'], how='left')
part_2 = pd.merge(part_1, profit, on=['证券代码', '分部项目', 'cato', 'year'], how='left')
all_part = pd.merge(part_2, profit_rate, on=['证券代码', '分部项目', 'cato', 'year'], how='left')
all_part = all_part.dropna(subset=['营业总收入','营业成本','毛利','毛利率(%)'],how='all')
all_file_data = pd.concat([all_file_data, all_part])
print(file+'已合并完毕')
all_file_data.to_csv('./Desktop/all_file.csv', index=False, encoding='gbk')
if __name__ == '__main__':
main(file_path)
最终所有文件合并数据如下


R版本全部代码
按照同样的思路,用R语言亦可实现。(这里实现宽转长运算的为tidyverse包下gather函数)
library(readxl)
library(tidyverse)
library(plyr)
#处理产品及地区数据
get_data<-function(start_row,end_row,cato,category){
item_data<-data[(start_row+2):(end_row-1),]
colnames(item_data)<-change_date(data[1,])
item_data<-gather(item_data,key="year",value='types',colnames(item_data)[2:ncol(item_data)])
colnames(item_data)<-c("分部项目","year",category)
item_data$cato<-cato
item_data<-item_data[,c(1,ncol(item_data),2:(ncol(item_data)-1))]
return(item_data)
}
#R读取时,日期会转为天数,这里将其转换
change_date<-function(x){
x<-as.character(as.Date(as.numeric(x),origin='1899-12-30'))
return(x)}
#处理上市文件下单个类型数据
transform_data1<-function(start_row,end_row,category){
item_row<-which(data[start_row:end_row,1]=='产品')+start_row-1
loc_row<-which(data[start_row:end_row,1]=='地区')+start_row-1
#产品处理
product_data<-get_data(item_row,loc_row,'产品',category)
#地区处理
loc_data<-get_data(loc_row,end_row,'地区',category)
#合并
company_data<-rbind(product_data,loc_data)
return(company_data)
}
#用于存储所有文件数据
all_file_data<-data.frame(matrix(0,0,0))
shangshi<-list.files('./desktop/上市/')
shangshi<-shangshi[-1]
#循环遍历所有文件
for(file in shangshi){
file_dir<-paste0('./desktop/上市/',file)
data<-read_xlsx(file_dir,sheet=1,skip = 3) #跳过前三行,读取sheet1
code<-paste(str_split_fixed(file,'[.]',3)[1,1],str_split_fixed(shangshi[1],'[.]',3)[1,2],sep='.')
income_row<-which(data[,1]=="营业总收入")
expense_row<-which(data[,1]=="营业成本")
profit_row<-which(data[,1]=="毛利")
profit_rates_row<-which(data[,1]=='毛利率(%)')
income_data<-transform_data1(income_row,expense_row,'营业总收入')
expense_data<-transform_data1(expense_row,profit_row,'营业成本')
profit_data<-transform_data1(profit_row,profit_rates_row,'毛利')
profit_rates<-transform_data1(profit_rates_row,nrow(data)-3,'毛利率(%)')
#合并处理
join_data1<-join(income_data,expense_data,by=c('分部项目','year','cato'),type='left')
join_data2<-join(join_data1,profit_data,by=c('分部项目','year','cato'),type='left')
all_data<-join(join_data2,profit_rates,by=c('分部项目','year','cato'),type='left')
#添加证券代码
all_data$证券代码<-code
#调整顺序
all_data<-all_data[,c(ncol(all_data),1:(ncol(all_data)-1))]
all_file_data<-rbind(all_file_data,all_data)
print(paste0(file_dir,"处理完毕"))
}
#删除四个指标均为空的值
income_is_na<-is.na(all_file_data$营业总收入)
expense_is_na<-is.na(all_file_data$营业成本)
profit_is_na<-is.na(all_file_data$毛利)
profit_rate_is_na<-is.na(all_file_data$`毛利率(%)`)
all_is_na<-which(income_is_na&expense_is_na&profit_is_na&profit_rate_is_na)
all_file_data<-all_file_data[-all_is_na,]
write.csv(all_file_data,'all_file.csv',row.names=FALSE)
这里提供部分数据,供大家学习~
链接:https://pan.baidu.com/s/16FUIvKykhKXtl_aS8d7RgA 提取码:zutb
以上就是本次分享的全部内容~