深度学习推荐系统(三)NeuralCF及其在ml-1m电影数据集上的应用
深度学习推荐系统(三)NeuralCF及其在ml-1m电影数据集上的应用
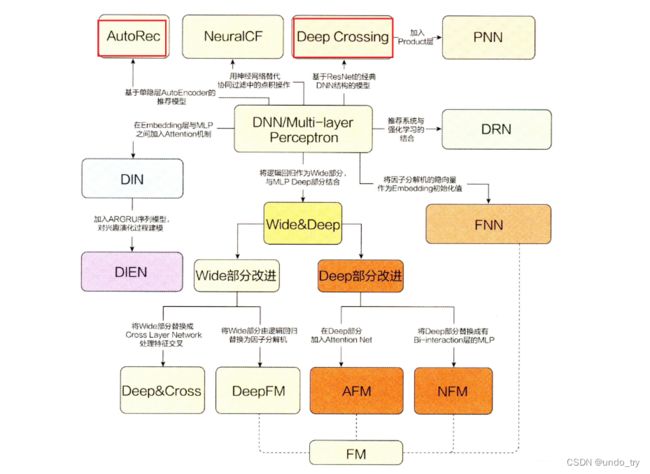
在2016年, 随着微软的Deep Crossing, 谷歌的Wide&Deep以及FNN、PNN等一大批优秀的深度学习模型被提出, 推荐系统全面进入了深度学习时代, 时至今日, 依然是主流。 推荐模型主要有下面两个进展:
-
与传统的机器学习模型相比, 深度学习模型的表达能力更强, 能够挖掘更多数据中隐藏的模式
-
深度学习模型结构非常灵活, 能够根据业务场景和数据特点, 灵活调整模型结构, 使模型与应用场景完美契合
深度学习推荐模型,以多层感知机(MLP)为核心, 通过改变神经网络结构进行演化。
传统的推荐算法有两个根本性思路:
-
一个是用户和条目的表征, 也就是如何更好地把用户特征和物品特征信息表示出来。 隐语义模型(MF)就是属于这个思路上的, 使用了embedding的思路去表示用户和物品, 从而用向量的乘积表示用户对物品的喜好程度。
-
第二个思路是特征交叉, 即考虑特征之间的交互信息以丰富数据的表达能力。 因子分解机(FM)的家族就是致力于解决这个问题上的。
深度学习的推荐算法, 依然会是这两个根本性的思路
-
有的深度学习算法依然会专走用户和条目表征的思路。
AutoRec和Deep Crossing模型是在神经网络的复杂度和层数方面进行的进化,而这两个模型也是使用深度学习从用户和条目表征的角度解决推荐问题的方案, 因为它们并没有刻意去研究特征与特征之间的交互。 -
有的深度学习算法会专走特征交叉的思路。
Neural CF模型和PNN模型更注重于研究特征交叉的方式。 -
当然,还有深度学习都会关注。
1 NeuralCF模型原理
1.1 矩阵分解模型MF
矩阵分解是在协同过滤共现矩阵的基础上, 使用更稠密的隐向量表示用户和物品, 挖掘用户和物品的隐含兴趣和隐含特征, 在一定程度上弥补协同过滤模型处理稀疏矩阵能力不足的问题。
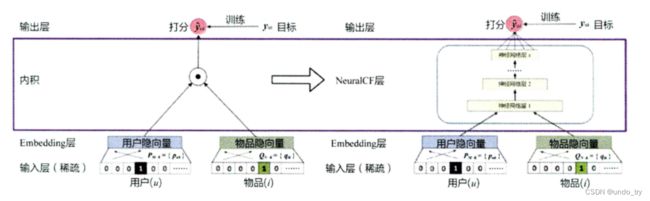
矩阵分解中隐向量的学习过程, 在深度学习中, 就可以看成是一个简单的神经网络表示, 用户向量和物品向量可以看成embedding的方法, 而最终的评分值(预测值), 就是用户向量和物品向量内积后的“相似度”。 而这步内积运算, 就可以看成一个神经单元里面的计算了。

在实际使用矩阵分解来训练和评估模型的过程中,往往会发现模型容易处于欠拟合的状态,究其原因是因为矩阵分解的模型结构相对比较简单,特别是“输出层”(也被称为“Scoring 层”),无法对优化目标进行有效的拟合。这就要求模型有更强的表达能力,在此动机的启发下,新加坡国立大学的研究人员提出了NeuralCF 模型。
1.2 NeuralCF 模型的结构
一个重要的改进其实就是用一个多层的神经网络+输出层替换了矩阵分解里面的内积操作
-
这样做一是让用户向量和物品向量做更充分的交叉, 得到更多有价值的特征组合信息
-
二是引入更多的非线性特征, 让模型的表达能力更强
1.2.1 NeuralCF 模型的细节
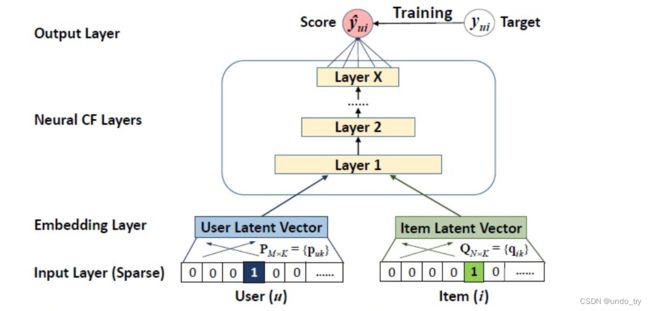
NeuralCF 模型可以看成一种general NCF框架, 因为向量交叉的方式可以有很多种,
-
如果这里是内积操作, 那么这个NCF框架就成了普通的GMF
-
如果这里是多层神经网络, 那么这个框架就成了一种MLP的网络
1.2.2 NeuralCF 混合模型
对于NCF框架, 根据交叉方式的不同就有上面的两个实例模型GMF和MLP, 前者是用线性的方式建模了特征交叉, 而后者是引入了非线性的方式建模了特征交叉。
NeuralCF 混合模型整合了上面提出的原始 NeuralCF 模型和以元素积为互操作的广义矩阵分解模型。这让模型具有了更强的特征组合和非线性能力。

1.2.3 NeuralCF 模型的优缺点
NeuralCF 模型实际上提出了一个模型框架,它基于用户向量和物品向量这两个Embedding 层,利用不同的互操作层进行特征的交叉组合,并且可以灵活地进行不同互操作层的拼接。从这里可以看出深度学习构建推荐模型的优势:利用神经网络理论上能够拟合任意函数的能力,灵活地组合不同的特征,按需增加或减少模型的复杂度。
NeuralCF 模型也存在局限性。由于是基于协同过滤的思想进行构造的,所以NeuralCF 模型并没有引入更多其他类型的特征,这在实际应用中无疑浪费了其他有价值的信息。
1.3 NeuralCF 模型代码实现
NeuralCF 混合模型整合了原始 NeuralCF 模型和以元素积为互操作的广义矩阵分解模型。
1.3.1 GMF模型的实现
import torch
import torch.nn as nn
class GMF(nn.Module):
def __init__(self, num_users, num_items, latent_dim):
super(GMF, self).__init__()
self.MF_Embedding_User = nn.Embedding(num_embeddings=num_users, embedding_dim=latent_dim)
self.MF_Embedding_Item = nn.Embedding(num_embeddings=num_items, embedding_dim=latent_dim)
self.linear = nn.Linear(latent_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
# 这个inputs是一个批次的数据, 所以后面的操作切记写成inputs[0], [1]这种, 这是针对某个样本了, 我们都是对列进行的操作
# 先把输入转成long类型
inputs = inputs.long()
# 用户和物品的embedding
MF_Embedding_User = self.MF_Embedding_User(inputs[:, 0])
MF_Embedding_Item = self.MF_Embedding_Item(inputs[:, 1])
# 两个隐向量点积
predict_vec = torch.mul(MF_Embedding_User, MF_Embedding_Item)
# liner
linear = self.linear(predict_vec)
output = self.sigmoid(linear)
return output
if __name__ == '__main__':
# 创建GMF模型
model = GMF(num_users=50,num_items=20,latent_dim=10)
print(model)
# 创建测试数据,批次大小为1,特征为2(user_id,item_id)
x = torch.rand(size=(1, 2), dtype=torch.float32)
print(model(x))
GMF(
(MF_Embedding_User): Embedding(50, 10)
(MF_Embedding_Item): Embedding(20, 10)
(linear): Linear(in_features=10, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
tensor([[0.4614]], grad_fn=<SigmoidBackward0>)
1.3.2 MLP模型的实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self, num_users, num_items, layers=[20, 64, 32, 16]):
super(MLP, self).__init__()
# embedding层
self.MLP_Embedding_User = nn.Embedding(num_embeddings=num_users, embedding_dim=layers[0]//2)
self.MLP_Embedding_Item = nn.Embedding(num_embeddings=num_items, embedding_dim=layers[0]//2)
# 全连接网络
self.dnn_network = nn.ModuleList(
[
nn.Linear(layer[0], layer[1]) for layer in list(zip(layers[:-1],layers[1:]))
]
)
self.linear = nn.Linear(layers[-1],1)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
# 这个inputs是一个批次的数据, 所以后面的操作切记写成inputs[0], [1]这种, 这是针对某个样本了, 我们都是对列进行的操作
# 先把输入转成long类型
inputs = inputs.long()
# 用户和物品的embedding
MLP_Embedding_User = self.MLP_Embedding_User(inputs[:, 0])
MLP_Embedding_Item = self.MLP_Embedding_Item(inputs[:, 1])
# 两个隐向量堆叠起来
x = torch.cat([MLP_Embedding_User, MLP_Embedding_Item], dim=-1)
# 全连接网络
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.linear(x)
output = self.sigmoid(x)
return output
if __name__ == '__main__':
# 创建模型
net = MLP(num_users=50,num_items=20)
print(net)
# 创建测试数据,批次大小为1,特征为2(user_id,item_id)
x = torch.rand(size=(1, 2), dtype=torch.float32)
print(net(x))
MLP(
(MLP_Embedding_User): Embedding(50, 10)
(MLP_Embedding_Item): Embedding(20, 10)
(dnn_network): ModuleList(
(0): Linear(in_features=20, out_features=64, bias=True)
(1): Linear(in_features=64, out_features=32, bias=True)
(2): Linear(in_features=32, out_features=16, bias=True)
)
(linear): Linear(in_features=16, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
tensor([[0.4674]], grad_fn=<SigmoidBackward0>)
1.3.3 NeuralCF 模型的实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class NeuralCF(nn.Module):
def __init__(self, num_users, num_items, latent_dim, layers=[20, 64, 32, 16]):
super(NeuralCF, self).__init__()
# embedding层
self.MF_Embedding_User = nn.Embedding(num_embeddings=num_users, embedding_dim=latent_dim)
self.MF_Embedding_Item = nn.Embedding(num_embeddings=num_items, embedding_dim=latent_dim)
# embedding层
self.MLP_Embedding_User = nn.Embedding(num_embeddings=num_users, embedding_dim=layers[0] // 2)
self.MLP_Embedding_Item = nn.Embedding(num_embeddings=num_items, embedding_dim=layers[0] // 2)
# 全连接网络
self.dnn_network = nn.ModuleList(
[
nn.Linear(layer[0], layer[1]) for layer in list(zip(layers[:-1], layers[1:]))
]
)
self.linear = nn.Linear(layers[-1], latent_dim)
# 合并之后
self.linear2 = nn.Linear(2 * latent_dim, 1)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
# TODO 1、左边的GMF模型
# 这个inputs是一个批次的数据, 所以后面的操作切记写成inputs[0], [1]这种, 这是针对某个样本了, 我们都是对列进行的操作
# 先把输入转成long类型
inputs = inputs.long()
# MF模型的计算 用户和物品的embedding
MF_Embedding_User = self.MF_Embedding_User(inputs[:, 0])
MF_Embedding_Item = self.MF_Embedding_Item(inputs[:, 1])
# 两个向量点积过一个全连接
mf_vec = torch.mul(MF_Embedding_User, MF_Embedding_Item)
# TODO 2、右边的MLP模型
# MLP 模型的计算
MLP_Embedding_User = self.MLP_Embedding_User(inputs[:, 0])
MLP_Embedding_Item = self.MLP_Embedding_Item(inputs[:, 1])
# 两个隐向量堆叠起来
x = torch.cat([MLP_Embedding_User, MLP_Embedding_Item], dim=-1)
# 全连接网络
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
# 输出纬度和GMF输出的相同
mlp_vec = self.linear(x)
# TODO 3、合并两个
vector = torch.cat([mf_vec, mlp_vec], dim=-1)
# liner
linear = self.linear2(vector)
output = self.sigmoid(linear)
return output
if __name__ == '__main__':
net = NeuralCF(num_users=50,num_items=20,latent_dim=10)
print(net)
# 创建测试数据,批次大小为1,特征为2(user_id,item_id)
x = torch.rand(size=(1, 2), dtype=torch.float32)
print(net(x))
NeuralCF(
(MF_Embedding_User): Embedding(50, 10)
(MF_Embedding_Item): Embedding(20, 10)
(MLP_Embedding_User): Embedding(50, 10)
(MLP_Embedding_Item): Embedding(20, 10)
(dnn_network): ModuleList(
(0): Linear(in_features=20, out_features=64, bias=True)
(1): Linear(in_features=64, out_features=32, bias=True)
(2): Linear(in_features=32, out_features=16, bias=True)
)
(linear): Linear(in_features=16, out_features=10, bias=True)
(linear2): Linear(in_features=20, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
tensor([[0.5512]], grad_fn=<SigmoidBackward0>)
2 Neural CF在ml-1m电影数据集上的应用
使用的数据集是MovieLen电影评分数据集(处理过)。
下载地址:https://github.com/hexiangnan/neural_collaborative_filtering
2.1 数据预处理
import scipy.sparse as sp
import numpy as np
# filename为test.rating的数据 类似于测试集的制作
def load_rating_file_as_list(filename):
ratingList = []
with open(filename, "r") as f:
line = f.readline()
while line is not None and line != "":
arr = line.split("\t")
user, item = int(arr[0]), int(arr[1])
ratingList.append([user, item]) # 用户名 电影名
line = f.readline()
return ratingList
# test.negative
def load_negative_file(filename):
negativeList = []
with open(filename, "r") as f:
line = f.readline()
while line is not None and line != "":
arr = line.split("\t")
negatives = []
for x in arr[1:]:
negatives.append(int(x))
negativeList.append(negatives)
line = f.readline()
return negativeList
def load_rating_file_as_matrix(filename):
"""
Read .rating file and Return dok matrix.
The first line of .rating file is: num_users\t num_items
"""
# Get number of users and items
num_users, num_items = 0, 0 # 这俩记录用户编号和物品编号里面的最大值,用来构建稀疏矩阵
with open(filename, "r") as f:
line = f.readline()
while line is not None and line != "":
arr = line.split("\t")
u, i = int(arr[0]), int(arr[1])
num_users = max(num_users, u)
num_items = max(num_items, i)
line = f.readline()
# Construct matrix
# dok_matrix可以高效地逐渐构造稀疏矩阵。 存储是稀疏存储 toarray()
mat = sp.dok_matrix((num_users + 1, num_items + 1), dtype=np.float32)
with open(filename, "r") as f:
line = f.readline()
while line is not None and line != "":
arr = line.split("\t")
user, item, rating = int(arr[0]), int(arr[1]), float(arr[2])
if rating > 0:
mat[user, item] = 1.0
line = f.readline()
return mat # 0,1矩阵, 如果评过分就是1, 否则是0
class Dataset():
def __init__(self, path):
# 将【电影-用户-评分】数据转换为0,1稀疏矩阵,如果评过分,那么就为1,否则为0
# 这个矩阵的行数是用户数目, 列数是商品数目, 1代表某个用户对某个电影感兴趣
self.trainMatrix = load_rating_file_as_matrix(path + '.train.rating')
# 测试集正样本
# 将测试数据【用户名,电影名】封装到list中
# 6040个元素,每个元素(userID, ItemID)的格式
self.testRatings = load_rating_file_as_list(path + '.test.rating')
# 测试集负样本
# 6040个 每个元素的长度均为99个 这个和上面的testRating对应, 即每个用户评分电影里面有一个正的, 99个负的
self.testNegatives = load_negative_file(path + '.test.negative')
assert len(self.testRatings) == len(self.testNegatives)
def Getdataset(self):
return (self.trainMatrix, self.testRatings, self.testNegatives)
if __name__ == '__main__':
# 开始导入原数据并进行处理
'''
处理过的电影数据集:
数据集地址:https://github.com/hexiangnan/neural_collaborative_filtering
processed datasets: MovieLens 1 Million (ml-1m)
train.rating:
Train file.
Each Line is a training instance: userID\t itemID\t rating\t timestamp (if have)
test.rating:
Test file (positive instances).
Each Line is a testing instance: userID\t itemID\t rating\t timestamp (if have)
test.negative
Test file (negative instances).
Each line corresponds to the line of test.rating, containing 99 negative samples.
Each line is in the format: (userID,itemID)\t negativeItemID1\t negativeItemID2 ...
'''
path = 'Data/ml-1m'
dataset = Dataset(path)
train, testRatings, testNegatives = dataset.Getdataset()
for item in testNegatives:
print(len(item))
2.2 加载数据
import os
os.environ['KMP_DUPLICATE_LIB_OK']="TRUE"
import torch
from torch.utils.data import DataLoader, Dataset, TensorDataset
import numpy as np
import torch.nn as nn
from torchkeras import summary
import warnings
warnings.filterwarnings('ignore')
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
from MovieDataSet import Dataset
# 1、加载处理好的数据
path = 'Data/ml-1m'
dataset = Dataset(path)
train, testRatings, testNegatives = dataset.Getdataset()
num_users, num_items = train.shape
num_users, num_items # (6040, 3706)
# 制作数据 用户打过分的为正样本, 用户没打分的为负样本, 负样本这里采用的采样的方式
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [], [], []
num_items = train.shape[1]
for (u, i) in train.keys(): # train.keys()是打分的用户和商品
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instance
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u, j) in train:
j = np.random.randint(num_items)
#print(u, j)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
def get_train(train, num_negatives=4, batch_size=64):
user_input, item_input, labels = get_train_instances(train, num_negatives)
train_x = np.vstack([user_input, item_input]).T
labels = np.array(labels)
# 构建成Dataset和DataLoader
train_dataset = TensorDataset(torch.tensor(train_x), torch.tensor(labels).float())
dl_train = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
return dl_train
dl_train = get_train(train)
2.3 创建模型
# 2、创建模型
from _03_NeuralCF import NeuralCF
num_factors =8
layers = [num_factors*2, 64, 32, 16]
net = NeuralCF(num_users, num_items, num_factors, layers)
summary(net, input_shape=(2,))
==========================================================================
Layer (type) Output Shape Param #
==========================================================================
Embedding-1 [-1, 8] 48,320
Embedding-2 [-1, 8] 29,648
Embedding-3 [-1, 8] 48,320
Embedding-4 [-1, 8] 29,648
Linear-5 [-1, 64] 1,088
Linear-6 [-1, 32] 2,080
Linear-7 [-1, 16] 528
Linear-8 [-1, 8] 136
Linear-9 [-1, 1] 17
Sigmoid-10 [-1, 1] 0
==========================================================================
Total params: 159,785
Trainable params: 159,785
Non-trainable params: 0
--------------------------------------------------------------------------
Input size (MB): 0.000008
Forward/backward pass size (MB): 0.001175
Params size (MB): 0.609531
Estimated Total Size (MB): 0.610714
--------------------------------------------------------------------------
2.4 模型评估函数
import torch
import numpy as np
import heapq
# Global variables that are shared across processes
_model = None
_testRatings = None
_testNegatives = None
_K = None
# HitRation
# 就是在99个负样本中,和正样本(即item_id)一样的个数
def getHitRatio(ranklist, gtItem):
for item in ranklist:
if item == gtItem:
return 1
return 0
# NDCG
'''
当我们检索【推荐排序】,网页返回了与推荐排序相关的链接列表。
列表可能会是[A,B,C,G,D,E,F],也可能是[C,F,A,E,D],现在问题来了,当系统返回这些列表时,怎么评价哪个列表更好
NDCG就是用来评估排序结果的。搜索和推荐任务中比较常见。
具体可参考:
https://zhuanlan.zhihu.com/p/448686098
'''
def getNDCG(ranklist, gtItem):
for i in range(len(ranklist)):
item = ranklist[i]
if item == gtItem:
return np.log(2) / np.log( i + 2)
return 0
def try_gpu(i=0):
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}')
return torch.device('cpu')
def eval_one_rating(idx): # 一次评分预测
device = try_gpu()
rating = _testRatings[idx]
items = _testNegatives[idx]
u = rating[0]
gtItem = rating[1]
# 将1个正样本添加到列表末尾,最终有1个正样本和99个负样本
items.append(gtItem)
# Get prediction scores
map_item_score = {}
users = np.full(len(items), u, dtype='int32')
test_data = torch.tensor(np.vstack([users, np.array(items)]).T).to(device)
predictions = _model(test_data)
for i in range(len(items)):
item = items[i]
map_item_score[item] = predictions[i].data.cpu().numpy()[0]
items.pop()
# Evaluate top rank list
ranklist = heapq.nlargest(_K, map_item_score, key=lambda k: map_item_score[k]) # heapq是堆排序算法, 取前K个
hr = getHitRatio(ranklist, gtItem)
ndcg = getNDCG(ranklist, gtItem)
return hr, ndcg
def evaluate_model(model, testRatings, testNegatives, K):
"""
Evaluate the performance (Hit_Ratio, NDCG) of top-K recommendation
Return: score of each test rating.
"""
global _model
global _testRatings
global _testNegatives
global _K
_model = model
_testNegatives = testNegatives
_testRatings = testRatings
_K = K
hits, ndcgs = [], []
for idx in range(len(_testRatings)):
(hr, ndcg) = eval_one_rating(idx)
hits.append(hr)
ndcgs.append(ndcg)
return hits, ndcgs
if __name__ == '__main__':
from MovieDataSet import Dataset
from _01_GMF import GMF
path = 'Data/ml-1m'
dataset = Dataset(path)
train, testRatings, testNegatives = dataset.Getdataset()
model = GMF(num_users=train.shape[0],num_items=train.shape[1],latent_dim=10)
hits, ndcgs = evaluate_model(model,testRatings,testNegatives,10)
print(hits)
print(ndcgs)
# 初始评分
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR=%.4f, NDCG=%.4f' % (hr, ndcg))
# 先导入模型评估函数
from _01_model_evalute import evaluate_model
topK = 10
# 计算出初始的评估
(hits, ndcgs) = evaluate_model(net, testRatings, testNegatives, topK)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR=%.4f, NDCG=%.4f' %(hr, ndcg))
Init: HR=0.1030, NDCG=0.0463
2.5 模型的训练
# 这两个类可以参考
# https://blog.csdn.net/qq_44665283/article/details/130598697?spm=1001.2014.3001.5502
from AnimatorClass import Animator
from TimerClass import Timer
def train_ch(net, dl_train, testRatings, testNegatives, num_epochs=10, lr=0.001, topK=10):
print('training on', device)
net.to(device)
# 模型训练
best_hr, best_ndcg, best_iter = 0, 0, -1
log_step_freq = 10000
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)
# 绘制动态图
animator = Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'test hr', 'test ndcg'],figsize=(8.0, 6.0))
timer, num_batches = Timer(), len(dl_train)
for epoch in range(num_epochs):
# 训练阶段
net.train()
loss_sum = 0.0
for step, (features, labels) in enumerate(dl_train, 1):
timer.start()
features, labels = features.to(device), labels.to(device)
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = net(features)
loss = loss_func(predictions, labels.unsqueeze(1))
# 反向传播求梯度
loss.backward()
optimizer.step()
timer.stop()
loss_sum += loss.item()
if step % log_step_freq == 0:
animator.add(epoch + step / num_batches,(loss_sum/step,None, None))
# 验证阶段
net.eval()
(hits, ndcgs) = evaluate_model(net, testRatings, testNegatives, topK)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
animator.add(epoch + 1 ,(None, hr, ndcg))
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
torch.save(net.state_dict(), 'Pre_train/m1-1m_NeuralCF.pkl')
info = (epoch, loss_sum/step, hr, ndcg)
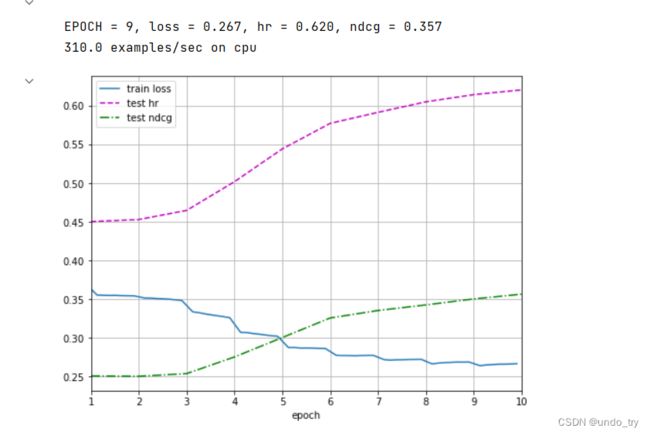
print(("\nEPOCH = %d, loss = %.3f, hr = %.3f, ndcg = %.3f") % info)
print(f'{num_batches * num_epochs / timer.sum():.1f} examples/sec on {str(device)}')
注:
NeuralCF模型也可以先预训练。预训练就是用已经训练好的参数, 直接用到NeuralCF上, 然后再进行训练, 这里考察对结构每个层参数的把握, 步骤如下:
- 首先要建立GMF和MLP模型, 并导入保存好的参数
- 建立NeuralCF模型, 获取到相应层, 得到相应的参数
关键步骤如下
old_param = neural_mf.state_dict()
old_param['MF_Embedding_User.weight'] = gmf.state_dict().get('MF_Embedding_User.weight')
old_param['MF_Embedding_Item.weight'] = gmf.state_dict().get('MF_Embedding_Item.weight')
old_param['MLP_Embedding_User.weight'] = mlp.state_dict().get('MLP_Embedding_User.weight')
old_param['MLP_Embedding_Item.weight'] = mlp.state_dict().get('MLP_Embedding_Item.weight')
for i in range(3):
old_param['dnn_network.' + str(i) + '.weight'] = mlp.state_dict().get('dnn_network.' + str(i) + '.weight')
old_param['dnn_network.' + str(i) + '.bias'] = mlp.state_dict().get('dnn_network.' + str(i) + '.bias')