noisy node
起源
DeepMind 两部曲。
第一篇,以下简称SGR (simple gnn regularization),熟人Peter。
SIMPLE GNN REGULARISATION FOR 3D MOLECULAR PROPERTY PREDICTION & BEYOND
ICLR 2022
https://arxiv.org/pdf/2106.07971v2.pdf
第二篇,以下简称PVD(Pretrain via Denoising)
发在第一篇一年后,有监督到无监督。
PRE-TRAINING VIA DENOISING FOR MOLECULAR PROPERTY PREDICTION
ICLR 2023
https://arxiv.org/pdf/2206.00133.pdf
Main methods
核心思想:给输入pos加noise,解决一些graph-level task上 node-level label缺失的问题。
而加上一个node-level loss可以防止深层过平滑。
强迫最后输出的node-level repr足够diversify。
下图可以看到,第一行(last layer) NN的MAD值大于DropEdge or DropNode。
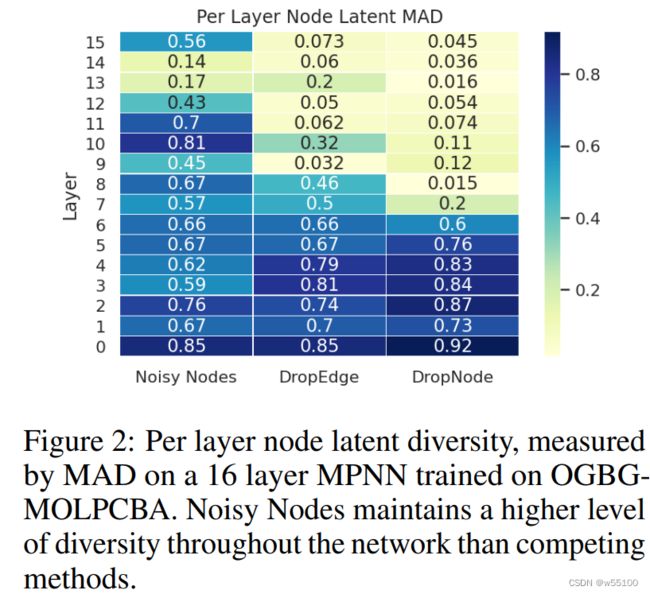
Appendix里还有一个和不加NN对比的图。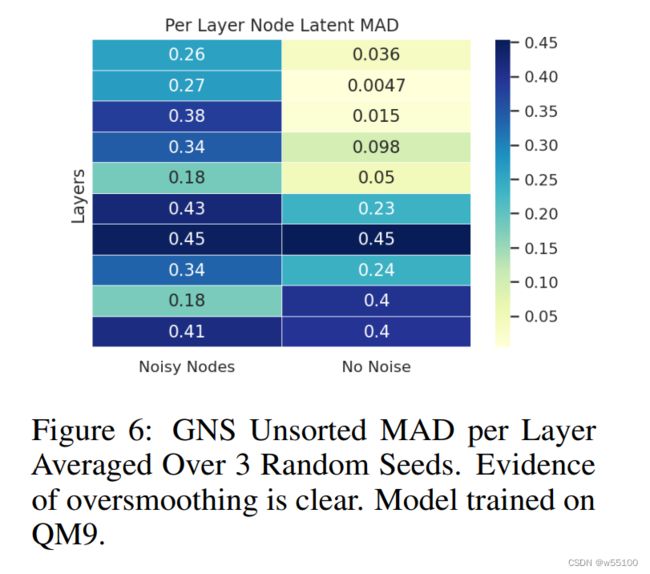
SGR还是从over-smoothing出发,作为一个正则项来看的。 auxiliary loss这个称呼习惯也由此而来。
Our method requires a noise correction target to prevent oversmoothing by enforcing diversity in the
last layers of the GNN, which can be achieved with an auxiliary denoising autoencoder loss
抛开SGR来看,这种做法类似于data augmentation。
例如在lowest energy sample上不断加noise,让其还原这个lowest energy,看上去就很合理。
(暴论:定点问题都可以用去噪来完成)
输入输出设置
Input positions are corrupted with noise σ, and the training objective is the node-level difference between target positions and the noisy inputs.
在SGR文章里,预测目标是 target position - noisy inputs。
Q: 什么是target position?
A:这里的target postion应该是一个虚指概念。
如果数据集不保证每个sample都处于某个定点,但有全局定点的pos标签(例如OC20提供relax pos标签),就用这个label position作为target position。然后构造 target position - noisy inputs作为正则项的预测目标。
如果数据集保证所有样本都处于每个分子各自的某个定点,此时,正则项的预测目标就退化为noise本身。
PS: 此处使用减法是为了保持translation invariance。
在PVD里,更进一步地简化了这种讨论,直接地把noise本身作为预测目标。
需要注意的是SGR认为NN是一种 supervised learning 里的 regularization loss。
而在PVD里, NN 被用于pretrain phrase,被认为是 unsupervised learning的 pretrain task target。
如果考虑 loss = alpha*energy_loss + beta*force_loss + gamma*nn_loss。
上述设置可以简化为
SGR: alpha, gamma>0, beta depends;
PVD: (pretrain)alpha=beta=0, gamma>0; (finetune) alpha>0 , gamma=0, beta depends;
Code
引自 uni-mol on OC20。
如上文所言,如果数据集本身提供定点坐标(代码里的pos_relaxed),就使用定点坐标+noise。
这里还有一种中间态的算法(代码里的mid)。
即介于平衡点与非平衡点pos之间,用插值的方法算一些中间态出来。
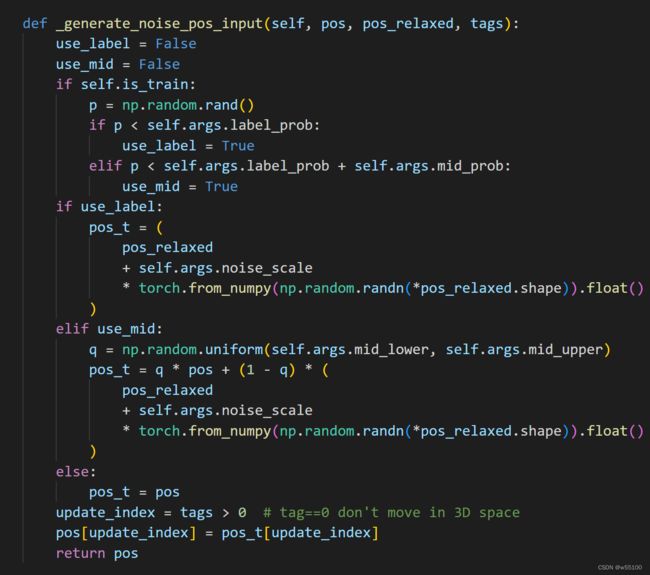
Motivation
NN 可以解释为平衡点的流形学习。
encoder学习输入样本的含噪流形,decoder输出干净的流形(平衡点)
作者认为平衡点包含了分子内最有用的信息和结构。
因此去学平衡点的表征,对其他下游任务更有帮助。
Inspired :
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.
ArXiv, abs/1907.05600, 2019
适用性
如上文所言。
定点问题可以用去噪来完成。
定点问题要求task本身存在一个固定的不动点目标。
在DeepMind这系列文章用到的数据集中,定点就是平衡态的分子。
- OC20是给出random init state,求一个relaxation state作为定点。(IS2RS,IS2RE)
- QM9是每个样本自己就是一个molecular at equilibrium with a local energy minimum,在noise scale足够小的时候,local minimum 可以视为定点。
这也解释了noise scale为什么要足够小。 当且仅当已知global minimum 时,可以加大noise scale。
在PVD的代码里,
- PCQM4MV2-Pretrain.denoising_weight = 0.04 。
- QM9-FineTune.denoising_weight = 0.1 。
在我们的QM数据集上,task本身不以定点为目标。(更类似于OC20的IS2EF赛道)
直接用NN as auxiliary loss不太现实,数据模式不匹配。
可以用pretrain + NN。
但需要用inchikey 先找出 target position。
感想
Deepmind的文章写的真好。高屋建瓴。
可以让人联想到很多文章没有提到的现象。
SGR这篇文章。
同样的做法,我就只能想到attack noise + denoise大概是有效的。做出来也确实是有效的,但不知道怎么解释。
写出来的效果也就只能到empirical effective这个程度了。
没想到绕来绕去,还是和over-smoothing关联上了。
我怎么就想不到拿MAD去算一遍residual update repr呢?