【大数据】Flink 详解(二):核心篇 Ⅰ
本系列包含:
- 【大数据】Flink 详解(一):基础篇
- 【大数据】Flink 详解(二):核心篇 Ⅰ
- 【大数据】Flink 详解(三):核心篇 Ⅱ
- 【大数据】Flink 详解(四):核心篇 Ⅲ
- 【大数据】Flink 详解(五):核心篇 Ⅳ
- 【大数据】Flink 详解(六):源码篇 Ⅰ
Flink 详解(二):核心篇 Ⅰ
- 14、Flink 的四大基石是什么?
- 15、说说 Flink 窗口,以及划分机制。
- 16、介绍下 Flink 的窗口机制以及各组件之间是如何相互工作的?
- 17、讲一下 Flink 的 Time 概念。
- 18、那在 API 调用时,应该怎么使用?
- 19、在流数据处理中,有没有遇到过数据延迟等问题,通过什么处理呢?
- 20、WaterMark 原理讲解一下?
- 21、如果数据延迟非常严重呢?只使用 WaterMark 可以处理吗?那应该怎么解决?
14、Flink 的四大基石是什么?
Flink 的四大基石分别是:
- Checkpoint(检查点)
- State(状态)
- Time(时间)
- Window(窗口)
15、说说 Flink 窗口,以及划分机制。
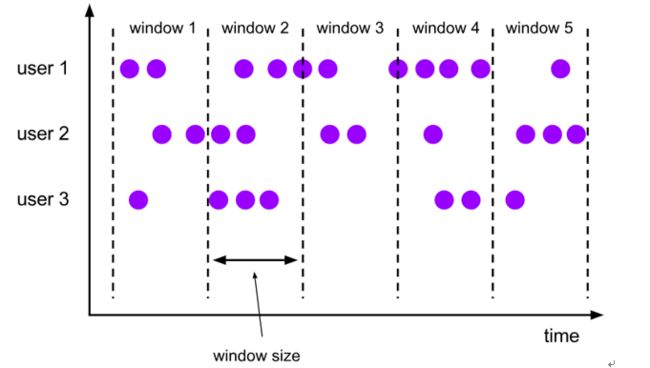
窗口概念:将无界流的数据,按时间区间,划分成多份数据,分别进行统计(聚合)。
Flink 支持两种划分窗口的方式(time 和 count)。第一种,按 时间驱动 进行划分、另一种按 数据驱动 进行划分。
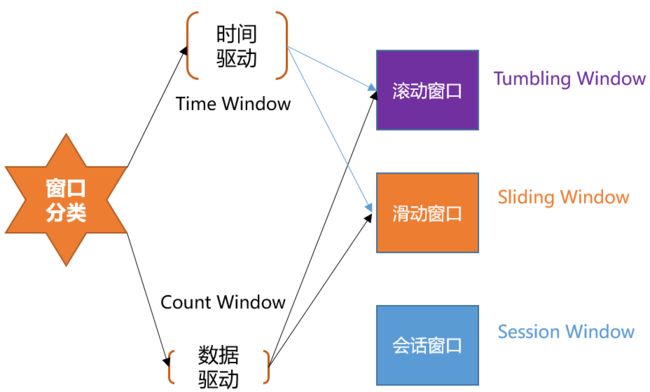
- 按时间驱动 Time Window 可以划分为 滚动窗口 Tumbling Window 和 滑动窗口 Sliding Window。
- 按数据驱动 Count Window 也可以划分为 滚动窗口 Tumbling Window 和 滑动窗口 Sliding Window。
- Flink 支持窗口的两个重要属性(窗口长度
size和 滑动间隔interval),通过窗口长度和滑动间隔来区分滚动窗口和滑动窗口。- 如果 size = interval,那么就会形成 tumbling-window(无重叠数据)——滚动窗口
- 如果 size(1min)> interval(30s),那么就会形成 sliding-window(有重叠数据)——滑动窗口
通过组合可以得出四种基本窗口:
(1)基于时间的滚动窗口:time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))。
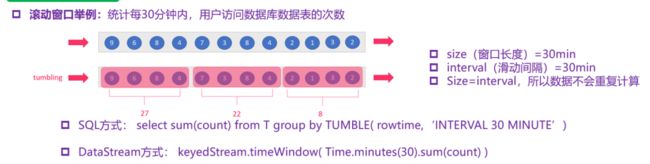
(2)基于时间的滑动窗口:time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(10), Time.seconds(5))。
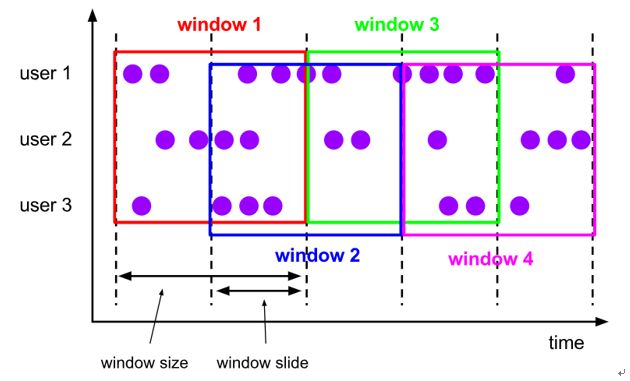
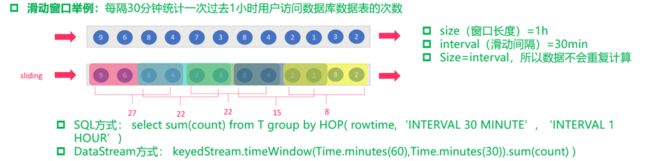
注:上图中有点小错误,应该是 size > interval,所以会有重叠数据。
(3)基于数量的滚动窗口:count-tumbling-window 无重叠数据的数量窗口,设置方式举例:countWindow(5)。

(4)基于数量的滑动窗口:count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(10,5)。

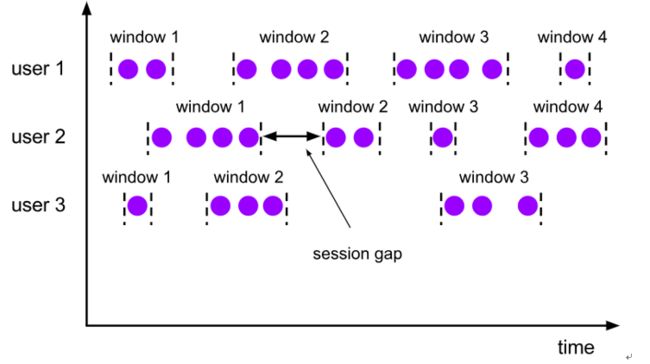
Flink 中还支持一个特殊的窗口:会话窗口 SessionWindows。
session 窗口分配器通过 session 活动来对元素进行分组,session 窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况。
session 窗口在一个固定的时间周期内不再收到元素,即非活动间隔产生,那么这个窗口就会关闭。
一个 session 窗口通过一个 session 间隔来配置,这个 session 间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的 session 将关闭并且后续的元素将被分配到新的 session 窗口中去,如下图所示:
16、介绍下 Flink 的窗口机制以及各组件之间是如何相互工作的?
以下为窗口机制的流程图:
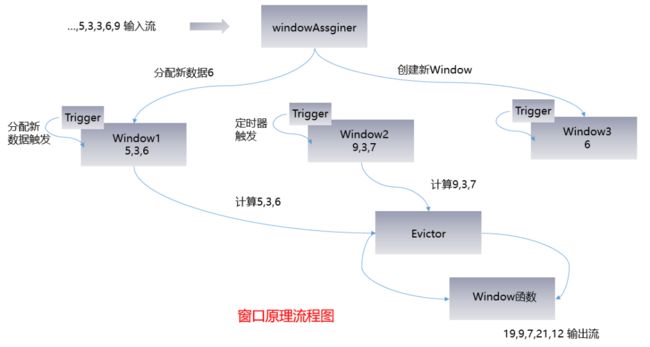
WindowAssigner
1、窗口算子负责处理窗口,数据流源源不断地进入算子(Window Operator)时,每一个到达的元素首先会被交给 WindowAssigner。WindowAssigner 会决定元素被放到哪个或哪些窗口(Window),可能会创建新窗口。因为一个元素可以被放入多个窗口中(个人理解是滑动窗口,滚动窗口不会有此现象),所以同时存在多个窗口是可能的。注意,Window 本身只是一个 ID 标识符,其内部可能存储了一些元数据,如 TimeWindow 中有开始和结束时间,但是并不会存储窗口中的元素。窗口中的元素实际存储在 Key/Value State 中,Key 为 Window,Value 为元素集合(或聚合值)。为了保证窗口的容错性,该实现依赖了 Flink 的 State 机制。
WindowTrigger
2、每一个 Window 都拥有一个属于自己的 Trigger,Trigger 上会有定时器,用来决定一个窗口何时能够被计算或清除。每当有元素加入到该窗口,或者之前注册的定时器超时了,那么 Trigger 都会被调用。Trigger 的返回结果可以是 :
- Continue(继续、不做任何操作)
- Fire(触发计算,处理窗口数据)
- Purge(触发清理,移除窗口和窗口中的数据)
- Fire + Purge(触发计算+清理,处理数据并移除窗口和窗口中的数据)
当数据到来时,调用 Trigger 判断是否需要触发计算,如果调用结果只是 Fire 的话,那么会计算窗口并保留窗口原样,也就是说窗口中的数据不清理,等待下次 Trigger Fire 的时候再次执行计算。窗口中的数据会被反复计算,直到触发结果清理。在清理之前,窗口和数据不会释放,所以窗口会一直占用内存。
Trigger 触发流程
3、当 Trigger Fire了,窗口中的元素集合就会交给 Evictor(如果指定了的话)。Evictor 主要用来遍历窗口中的元素列表,并决定最先进入窗口的多少个元素需要被移除。剩余的元素会交给用户指定的函数进行窗口的计算。如果没有 Evictor 的话,窗口中的所有元素会一起交给函数进行计算。
4、计算函数收到了窗口的元素(可能经过了 Evictor 的过滤),并计算出窗口的结果值,并发送给下游。窗口的结果值可以是一个也可以是多个。DataStream API 上可以接收不同类型的计算函数,包括预定义的 sum()、min()、max(),还有 ReduceFunction,FoldFunction,还有 WindowFunction。WindowFunction 是最通用的计算函数,其他的预定义的函数基本都是基于该函数实现的。
5、Flink 对于一些聚合类的窗口计算(如 sum、min)做了优化,因为聚合类的计算不需要将窗口中的所有数据都保存下来,只需要保存一个 result 值就可以了。每个进入窗口的元素都会执行一次聚合函数并修改 result 值。这样可以大大降低内存的消耗并提升性能。但是如果用户定义了 Evictor,则不会启用对聚合窗口的优化,因为 Evictor 需要遍历窗口中的所有元素,必须要将窗口中所有元素都存下来。
17、讲一下 Flink 的 Time 概念。
在 Flink 的流式处理中,会涉及到时间的不同概念,主要分为三种时间机制,如下图所示:
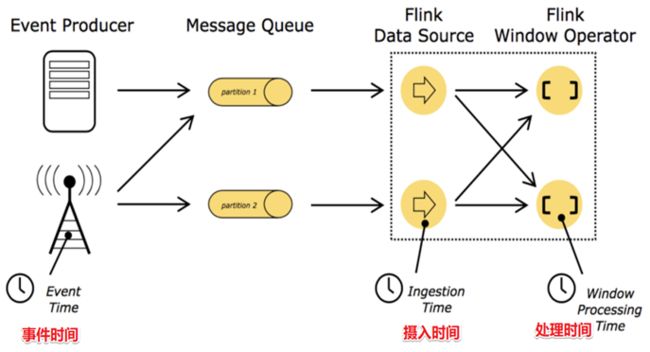
- EventTime,事件时间
- 事件发生的时间,例如:点击网站上的某个链接的时间,每一条日志都会记录自己的生成时间。
- 如果以 EventTime 为基准来定义时间窗口那将形成 EventTimeWindow,要求消息本身就应该携带 EventTime。
- IngestionTime,摄入时间
- 数据进入 Flink 的时间,如某个 Flink 节点的 source operator 接收到数据的时间,例如:某个 source 消费到 kafka 中的数据。
- 如果以 IngestionTime 为基准来定义时间窗口那将形成 IngestionTimeWindow,以 source 的 systemTime 为准。
- ProcessingTime,处理时间
- 某个 Flink 节点执行某个 operation 的时间,例如:timeWindow 处理数据时的系统时间,默认的时间属性就是 Processing Time。
- 如果以 ProcessingTime 基准来定义时间窗口那将形成 ProcessingTimeWindow,以 operator 的 systemTime 为准。
在 Flink 的流式处理中,绝大部分的业务都会使用 EventTime,一般只在 EventTime 无法使用时,才会被迫使用 ProcessingTime 或者 IngestionTime。
18、那在 API 调用时,应该怎么使用?
final StreamExecutionEnvironment env
= StreamExecutionEnvironment.getExecutionEnvironrnent();
// 使用处理时间
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime) ;
// 使用摄入时间
env.setStrearnTimeCharacteristic(TimeCharacteristic.IngestionTime);
// 使用事件时间
env.setStrearnTimeCharacteristic(TimeCharacteri stic Eve~tTime);
19、在流数据处理中,有没有遇到过数据延迟等问题,通过什么处理呢?
有遇到过数据延迟问题。举个例子:
案例 1:
- 假你正在去往地下停车场的路上,并且打算用手机点一份外卖。
- 选好了外卖后,你就用在线支付功能付款了,这个时候是 11 点 50 分。恰好这时,你走进了地下停车库,而这里并没有手机信号。因此外卖的在线支付并没有立刻成功,而支付系统一直在 Retry 重试 “支付” 这个操作。
- 当你找到自己的车并且开出地下停车场的时候,已经是 12 点 05 分了。这个时候手机重新有了信号,手机上的支付数据成功发到了外卖在线支付系统,支付完成。
- 在上面这个场景中你可以看到,支付数据的事件时间是11点50分,而支付数据的处理时间是12点05分
案例 2:
- 如上图所示,某 App 会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。
- A 用户在 11:02 对 App 进行操作,B 用户在 11:03 操作了 App。
- 但是 A 用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到 B 用户 11:03 的消息,然后再接受到 A 用户 11:02 的消息,消息乱序了。
一般处理数据延迟、消息乱序等问题,通过 WaterMark 水印来处理。水印是用来解决数据延迟、数据乱序等问题,总结如下图所示:

水印就是一个时间戳(timestamp),Flink 可以给数据流添加水印:
- 水印并不会影响原有 EventTime 事件时间。
- 当数据流添加水印后,会按照水印时间来触发窗口计算,也就是说 WaterMark 水印是用来触发窗口计算的。
- 设置水印时间,会比事件时间小几秒钟,表示最大允许数据延迟达到多久。
- 水印时间 = 事件时间 - 允许延迟时间(例如:10:09:57 = 10:10:00 - 3s)
20、WaterMark 原理讲解一下?
如下图所示:

窗口是 10 分钟触发一次,现在在 12:00 - 12:10 有一个窗口,本来有一条数据是在 12:00 - 12:10 这个窗口被计算,但因为延迟,12:12 到达,这时 12:00 - 12:10 这个窗口就会被关闭,只能将数据下发到下一个窗口进行计算,这样就产生了数据延迟,造成计算不准确。
现在添加一个水位线:数据时间戳为 2 分钟。这时用数据产生的事件时间 12:12 - 允许延迟的水印 2 分钟 = 12:10 >= 窗口结束时间 。窗口触发计算,该数据就会被计算到这个窗口里。
在 DataStream API 中使用 TimestampAssigner 接口定义时间戳的提取行为,包含两个子接口 AssignerWithPeriodicWatermarks 接口和 AssignerWithPunctuatedWaterMarks 接口。
定义抽取时间戳,以及生成 WaterMark 的方法,有两种类型
AssignerWithPeriodicWatermarks- 周期性的生成 WaterMark:系统会周期性的将 WaterMark插入到流中。
- 默认周期是 200 200 200 毫秒,可以使用
ExecutionConfig.setAutoWatermarklnterval()设置。 BoundedOutOfOrderness是基于周期性 WaterMark 的。
AssignerWithPunctuatedWatermarks- 没有时间周期规律,可打断的生成 watermark
| 定期生成 | 根据特殊记录生成 |
|---|---|
| 现实时间驱动 | 数据驱动 |
| 每一次分配 Timestamp 都会调用生成方法 | 每隔一段时间调用生成方法 |
实现 AssignerWithPeriodicWatermarks |
实现 AssignerWithPunctuatedWatermarks |
21、如果数据延迟非常严重呢?只使用 WaterMark 可以处理吗?那应该怎么解决?
使用 WaterMark + EventTimeWindow 机制可以在一定程度上解决数据乱序的问题,但是,WaterMark 水位线也不是万能的,在某些情况下,数据延迟会非常严重,即使通过 Watermark + EventTimeWindow 也无法等到数据全部进入窗口再进行处理,因为窗口触发计算后,对于延迟到达的本属于该窗口的数据,Flink 默认会将这些延迟严重的数据进行丢弃。
那么如果想要让一定时间范围的延迟数据不会被丢弃,可以使用 Allowed Lateness(允许迟到机制 / 侧道输出机制)设定一个允许延迟的时间和侧道输出对象来解决。
即使用 WaterMark + EventTimeWindow + Allowed Lateness 方案(包含侧道输出),可以做到数据不丢失。
API 调用
allowedLateness(lateness:Time):设置允许延迟的时间
该方法传入一个 Time 值,设置允许数据迟到的时间,这个时间和 WaterMark 中的时间概念不同。
再来回顾一下,WaterMark = 数据的事件时间 - 允许乱序时间值。随着新数据的到来,WaterMark 的值会更新为最新数据事件时间 - 允许乱序时间值,但是如果这时候来了一条历史数据,WaterMark 值则不会更新。
总的来说,WaterMark 永远不会倒退,它是为了能接收到尽可能多的乱序数据。
那这里的 Time 值呢?主要是为了等待迟到的数据,如果属于该窗口的数据到来,仍会进行计算,后面会对计算方式仔细说明。
注意:该方法只针对于基于 EventTime 的窗口。
sideOutputLateData(outputTag:OutputTag[T]):保存延迟数据
该方法是将迟来的数据保存至给定的 outputTag 参数,而 OutputTag 则是用来标记延迟数据的一个对象。
DataStream.getSideOutput(tag:OutputTag[X]):获取延迟数据
通过 window 等操作返回的 DataStream 调用该方法,传入标记延迟数据的对象来获取延迟的数据。