【知识分享】C语言应用-易错篇
一、C语言简介
C语言结构简洁,具有高效性和可移植性,因此被广泛应用。但究其历史的标准定义,C语言为了兼容性在使用便利性作出很大牺牲。在《C陷阱与缺陷》一书中,整理出大部分应用过程中容易出错的点,本文为《C陷阱与缺陷》的浓缩版本,想要更详细的解释,可以查看原著。
二、常见易错点
1、关键词
1.1 =与==
=:在C语言中代表赋值,典型用法是:a = b,意思是把b的值赋值给a。
==:在C语言中作为恒等于的逻辑判断,典型用法是:if (a == b),意思是判断a与b是否相等。
比如现在有个需求需要判断a与b相等则运行某个逻辑,但由于程序员的疏忽写成了如下代码:
if (a = b)
{
/* do something */
}
这个应该是耳熟能详了,最经典的一个故事就是某某航天局因为程序员的粗心,把一个"==“写成一个”=",导致火箭发射失败。在C专家编程一书中,作者把这个锅甩给了C语言标准,因为C的标准定义,导致所有的C编译器都不会去检查这个异常,而是把它当成程序员的正常操作。
1.2 & 和 | 不同于 && 和 ||
& 和 | 是位与和位或,&& 和 || 是逻辑与和逻辑或。习惯使用C语言的,可能在这点上犯错的概率不大,但如果是跨语言的开发,就容易把这两个符号搞混。
1.3 单字符与双字符
C语言中有些是单字符的符号,有些是双字符的,这样就难免会出现一些二义性,比如下面的代码,原意是y等于x除以指针p指向的值。
y = x/*p;
但因为/优先与*结合,所以这里变成/*的一个注释符。不过这种情况在现代的编辑环境中很难出现这种错误,因为编辑器在你写出这种语句时,就会把/*后面的部分给识别成注释内容。
还有一种可能是编译器都识别不出来的,就像下面这种。
a=-1;
在老版本的C语言中,是允许使用=+来代表+=的,=-代表就是-=,所以上面这个,原意是要给a赋值一个-1,结果编译器编译结果是a递减1。
因为有上面这些坑,所以对于C语言,我们最好是有一套简单的编码规则以避免上述问题,这里简单列出几点与此相关的。
等号两边加上空格,运算符号两边加上空格。
y = a + b; /* 推荐 */
y=a+b; /* 不推荐 */
*作为引用符时,贴近变量使用
y = *p; /* 推荐 */
y = * p; /* 不推荐 */
添加注释时,因为使用到//和/*,里面都存在/,为了防止/与其他字符异常结合,这里也是推荐//或/*后加个空格区分。
// 推荐
//不推荐
/* 推荐 */
/*不推荐*/
1.4 整型变量
如果整型变量第一个字符为0,那么该常量会被视作八进制数。这种写法是ANSI C标准禁止的写法,但有时候为了代码对齐美观,可能会出现这样的写法:
/* 错误写法 */
uint32_t Table[] =
{
012, 032, 054, 022,
123, 456, 321, 051
};
这样写会导致其中012变成10(十进制),032变成26(十进制),054变成44(十进制),022变成18(十进制),051变成41(十进制)。
/* 正确写法 */
uint32_t Table[] =
{
12, 32, 54, 22,
123, 456, 321, 51
};
1.5 单引号与双引号
单引号括起的一个字符代表一个整数,而用双引号括起的一个字符代表一个指针。
怎么理解呢,我们先来看下下面这两种写法。
char *p = "Hello world!\n";
printf(p);
char p[] = {'H', 'e', 'l', 'l', 'o', ' ', 'w', 'o', 'r', 'l', 'd', '!', '\n', 0};
printf(p);
这两种运行结果是完全一致的,但是我们从物理存储的角度来看,这两个是不一样的。
第一种,编译完之后,首先会在常量区存放"Hello world\n\0"这一段字符串常量,然后定义指针p时,p指针初始指向这个字符串的开头。
第二种,同样的编译完后会先在常量区存放"Hello world\n\0"这一些字符(但应该是会去重存放,实际编译出来的大小比上面那种整个字符串的小),然后定义p数组时,会将字符一个个拷贝至数组作为初值。
所以从空间上来看,第一种比第二种省了一部分ram空间的占用。
说完上面这些,现在来说易错的重点了,如果单引号和双引号用混了,会出现什么问题呢?我们来看下下面这个例子。
printf("\n"); /* 正常的写法 */
printf('\n'); /* 错误的使用 */
目前我们知道,printf的第一个传参是指针类型的,所以其运行机制是,当传入"\n"时,实际函数内部是通过地址索引到\n这个字符串的位置进行打印。但第二种写法就变成,传入的地址实际是\n这个字符的值,也就是传入的指针地址是10(\n的ASCII码值),所以printf会去10地址找字符串,直到遇到\0结束打印。
2、语法
2.1 函数声明
从最基础的定义开始,如何声明一个变量或常量是什么数据类型?
int main(void)
{
unsigned char apple = 0;
/* 声明20这个值是unsigned char,这种方式我们也称之为数据类型强转 */
apple = (unsigned char)20;
}
接下来提升点难度,如果现在要求要跳转到0地址运行,用C语言应该怎么实现?这个可以引申到C语言是如何实现跳转的。C语言中有一种很常见的跳转方式,就是函数。比如现在定义了一个函数A,这个函数A的所在地址刚好就是0,那调用这个函数A是不是就相当于跳转到0地址。那反过来,如果我把0地址当成函数操作,那是不是就可以实现程序的跳转。按照前面的分析,我们来简单实现一下。先来看下普通函数的调用方式。
/* 定义一个函数 */
void Func(void)
{
}
int main(void)
{
/* 函数的调用就是函数名加上()来实现 */
Func();
}
那有了上面函数的基本语法,那要把0地址当成函数来操作,是不是可以像下面这样操作。
int main(void)
{
/* 把0当成函数来操作 */
0();
}
这显然是不行的,我们可以看下函数的基本组成,除了函数传参,函数还有个返回值,而这里0这个数字,直接加上()进行引用,编译器并不知道这个“函数”的传参类型是什么,返回数据类型是什么,所以编译器搞不明白的东西,自然就会报错了。那么应该如何告诉编译器这个0是什么样的函数类型呢?这里就要用到我们神奇的指针了。
unsigned char *p;
我们看下这个指针也有个数据类型,这个数据类型表示的是这个指针指向的地址的数据类型。有没有发现一个好用的东西,就是定义一个指针时,可以给这个指针指向的地址定义一个数据类型,抛开指针不讲,就是可以给地址定义一个数据类型。那现在只要我们定义一个指针指向0,并且把这个指针指向的地址定义成函数类型,那不就完美解决上面的问题么。到这里我们就来看下函数指针应该如何定义及引用。
/* 定义一个函数指针 */
void (*pData)(void);
int main(void)
{
pData = 0;
/* 注意这里只是一种简写,写全应该是"*pData();",不过ANSI C允许下面这种简写形式 */
pData();
}
那么回到最开始的问题,如果这里不想引入指针变量,只想直接声明地址0是函数指针,那应该如何操作。
int main(void)
{
/* 把中间(void (*)(void))这部分抽出来,就是普通的指针引用 */
(*(void (*)(void))0)();
}
如果嫌上面的操作太简单,可以看下下面这个操作。
int main(void)
{
/* 我不是针对你,我是说在座的各位,都是xx */
(*(void(*(*)(void (*)(void)))(void))0)((void (*)(void))1)();
}
上面的操作其实可以通过typedef来进行简化的。简化后效果如下。
typedef void (*FUNCA)(void);
typedef FUNCA (*FUNCB)(FUNCA);
int main(void)
{
/* 简化后的操作,学废了么 */
(*(FUNCB)0)((FUNCA)1)();
}
指针操作的灵活性超乎你的想像,这就是函数声明的易错点。
2.2 运算符优先级
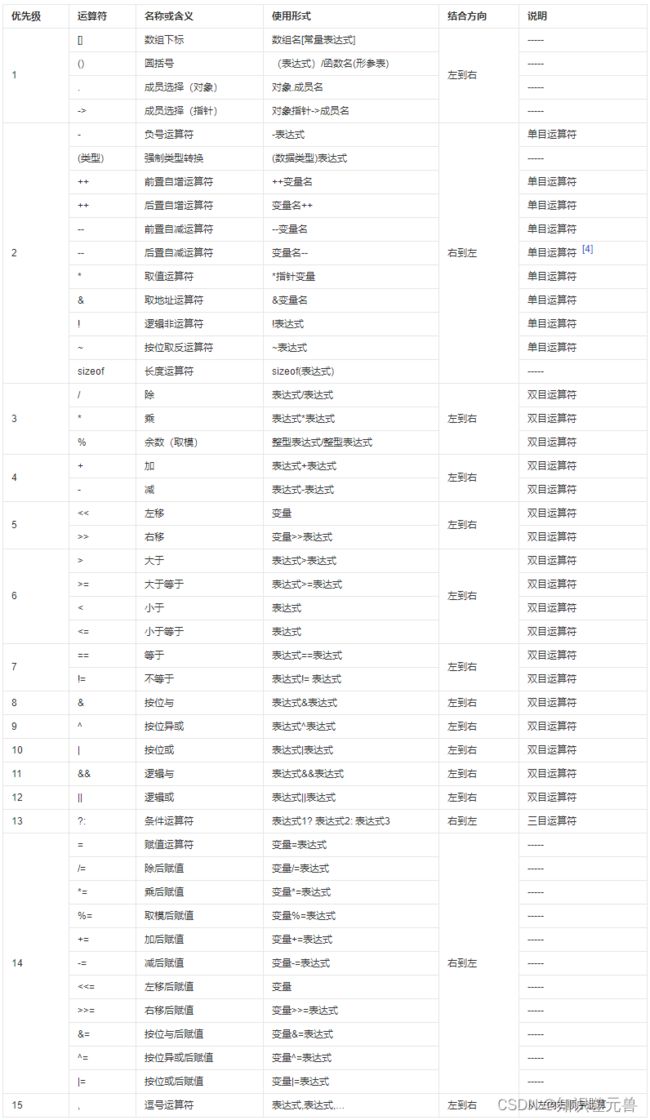
因为各运算符存在优先级,所以当运算符混用时,就容易出现实际效果跟想像中不一样的情况。比如*p++,实际编译器认为是*(p++)。又比如现在想要判断两个标志是否存在有某一位均为1,可以有如下写法:
if (flags & FLAG != 0)
但因为 != 的优先级比 && 高,所以上面的语句会被编译器解释为:
if (flags & (FLAG != 0))
这样就导致除了FLAG恰好为1或0的情形,FLAG为其他数时这个式子都是错误的。
但实际自己写代码的时候,没必要去背这个表,只要在需要先执行的语句中加上括号即可,毕竟括号不要钱,随便加,只要不加到影响阅读即可。
2.3 结束标志的分号
正常来讲,在C程序中多写一个分号可能不会造成什么影响:多出的分号可能会被视作一个不会产生任何实际效果的空语句。但如果这个多的分号是跟在if或while后,那可能会对原本的逻辑造成影响。如下:
if (x[i] > big);
big = x[i];
又或是少了个分号,那也会让程序逻辑大不相同:
if (n < 3)
return
logrec.data = x[0];
logrec.time = x[1];
logrec.code = x[2];
同样存在异常结束的还有if不加花括号的情况,比如下面这种,原意是如果a条件满足,则执行b、c、d函数。
if (a)
b();
c();
d();
但实际效果是下面这样,满足a条件,则执行b函数,然后再执行c、d函数。
if (a)
{
b();
}
c();
d();
于是这里也引发出一些编程规范。
使用if/for/while时,无论执行条件执行有多少个语句,都加上花括号。
/* 推荐 */
if (a)
{
b();
}
/* 不推荐 */
if (a) b();
2.4 switch-case
一般来说,switch除了搭配case,还有default和break,一个完整的switch-case语法如下:
switch (a)
{
case 0:
{
dosomethingA();
break;
}
case 1:
{
dosomethingB();
break;
}
default:
{
ErrorFunc();
break;
}
}
如果这里少了break,那如果输入a的值为1,按照原本的逻辑,应该是执行完dosomethingB后就退出,但没了break后程序执行完dosomethingB后不会退出switch语句,会继续执行ErrorFunc。不过有些场景下是会特地省略break。比如Duff’s device(达夫设备)的C语言实现,可以提高循环执行的效率,有兴趣可以去查下他的原理,下面上源码
/* to为拷贝的目标缓存,from为拷贝的源数据缓存,count为拷贝数据个数 */
void fDuffDevice( int * to, int * from, int count)
{
int n = (count + 7 ) / 8 ;
switch (count % 8 )
{
case 0 : do { * to ++ = * from ++ ;
case 7 : * to ++ = * from ++ ;
case 6 : * to ++ = * from ++ ;
case 5 : * to ++ = * from ++ ;
case 4 : * to ++ = * from ++ ;
case 3 : * to ++ = * from ++ ;
case 2 : * to ++ = * from ++ ;
case 1 : * to ++ = * from ++ ;
} while ( -- n > 0 );
}
}
2.5 一个else引发的血案
首先明白一个定义,else始终与同一括号内最近的未匹配的if结合,比如现在有这么一段代码:
if (x == 0)
if (y == 0) error();
else
{
z = x + y;
f(&z);
}
从缩进来看,作者原本是想着当x为0时,执行判断y的操作,不为0时执行加法。然而C语言不像python是按缩进来识别的,所以代码的实际逻辑如下:
if (x == 0)
{
if (y == 0)
{
error();
}
else
{
z = x + y;
f(&z);
}
}
所以还是那句话,尽量加上花括号,并且建议每个if后面都带个else,即使else里不执行代码。
/* 推荐 */
if (a)
{
dosomething();
}
else
{
/* 不需要执行 */
}
/* 不推荐 */
if (a)
dosomething();
3、语义
3.1 指针和数组
这两个算是有最多渊源的哥俩好,经常有人拿他俩去对比,有的说他俩是一样的,有的说不一样。直接说结论吧,这俩肯定不一样,如果一样为什么还要设计这么两种语法。这里不讲其他共性的点,重点讲下他俩最大的区别。
数组:编译器编译的时候就已经确定了数组的起始地址,如果把数组名当成指针操作,这就是一个常量指针(即指向的地址不可变)。所以这个所谓的“指针”本身是不占用空间的。
指针:指针地址可变,因此指针本身需要占用32位的空间(跟系统有关系,如果是64位系统那就是占用64位的空间),用来存储指针对应的地址。
除了上面这个性质外,其他方面两个基本是一样的。但是有一个点一些新手很容易搞混。就比如对于一维数组来讲,数组跟指针的操作可以互换。
unsigned char Arr[10];
unsigned char *P = Arr;
/* 下面这两个操作是等效的 */
P[3] = 2;
*(Arr + 3) = 2;
但是到二维数组,很多人就会犯下面这种错误。
unsigned char Arr[2][3];
unsigned char **P = Arr;
/* 下面这个操作编译器会报错 */
P[1][2] = 20;
正确的应该是下面这种写法。
unsigned char Arr[2][3];
/* 正确写法一 */
unsigned char (*P)[3] = Arr;
P[1][2] = 20;
/* 正确写法二 */
unsigned char *P = &Arr[0][0];
*(P + 3 * 1 + 2) = 20;
3.2 指针的拷贝
在Java中,存在深拷贝和浅拷贝的说法,深拷贝的意思就是完全复制一份数据,而浅拷贝则是复制一份数据的指向。换成C语言中,很多新手在完全搞懂指针之前很容易犯的一个错误就是指针类数据的拷贝,比如下面这种情况。
char *p, *q;
p = "abc";
q = p;
这里p是指向’a’‘b’‘c’'\0’这个字符串的一个指针,当把p赋值给q时,实际只是让q也指向这个字符串,而不是拷贝了一份字符串,所以当操作p[1] = ‘d’时,q[1]的值也会变成’d’。
3.3 空指针并非空字符串
空指针指的是指针的值为0,即指针指向0地址。而空字符串指的是字符串中没有元素,严格来讲是第一个字符就是’\0’,所以操作两者不能够等同。
3.4 边界计算
这个可以说是新手杀手,甚至有时候老手也会在这里栽跟头,因为C语言中的数组操作时,下标是从0开始的,于是当一个有n个元素的数组时,其可操作的下标范围为0~n-1。所以来看下下面这几类代码,是不是自己也在里面栽过跟头。
unsigned char i = 0;
unsigned char a[10];
/* 实际循环赋值了11次 */
for (i = 0; i <= 10; i++)
{
a[i] = 0;
}
/* 实际dosomething执行了times+1次 */
void Function(unsigned char times)
{
do
{
dosomething();
}
while (times--);
}
如果实在拿捏不准,建议代一个小值代入脑测一下。
3.5 求值顺序
自增减有两种写法,一种是作为变量前缀,一种则是作为变量后缀。
/* 先返回n的结果,再对n进行自加减操作 */
n++;
n--;
/* 先对n进行自加减操作,再返回自加减后n的结果 */
++n;
--n;
当这个自增/减变量应用在同一语句中的多个地方时,对这个执行顺序就有比较多的考究。
i = 0;
while (i < n)
y[i] = x[i++];
这个问题出在哪?上面这个代码是假设y[i]在i的自增操作之前被赋值,但ANSI C可不给你保证。也就是说,对于此处的处理顺序,ANSI C中并未给出明确的定义,所以不同编译器的处理的结果可能不一样。那对于这种问题,最保险的做法,就是自增/减单独一个语句执行。
3.6 最短执行路径
这个一般体现在判断语句中,比如有如下代码:
unsigned char a(void);
unsigned char b(void);
int main()
{
if (a() && b())
return 0;
}
如果要求a和b都必须执行,那上面这段代码,b是否执行完全看a的心情,当a函数返回结果为假,这时候无论b返回结果是真是假,此判断都不满足,所以程序会直接跳过b的运行结束此判断。
/* 规范性写法 */
unsigned char a();
unsigned char b();
int main()
{
unsigned char c, d;
/* 确保a和b都有执行 */
c = a();
d = b();
if (c && d)
return 0;
}
3.7 数据类型的隐式转换
就如下面一个简单的例子。
if (a - b < 0)
{
printf("%d - %d < 0\n", a, b);
}
else
{
printf("%d - %d >= 0\n", a, b);
}
这段代码执行结果如何,完全取决于a和b的数据类型和a、b本身的数值。比如下面这几种情况,执行结果将截然不同。
/* 这种定义结果是10 - 20 >= 0 */
unsigned int a = 10;
unsigned int b = 20;
/* 这种定义结果是10 - 20 < 0 */
signed int a = 10;
signed int b = 20;
/* 这种定义结果是10 - 20 < 0 */
unsigned char a = 10;
unsigned char b = 20;
为了避免这种情况,有一种最保险的方式,就是加个临时变量缓存一下,把“隐式”转为“明式”,明确其计算结果的数据类型,再进行下一步的比较和计算。
unsigned char a = 10;
signed short b = 20;
signed int c = a - b;
if (c < 0)
{
printf("%d - %d < 0\n", a, b);
}
else
{
printf("%d - %d >= 0\n", a, b);
}
4、链接
代码编译一般分为几个阶段,预编译->编译->汇编->链接,对于新手而言,很多人不清楚这个过程,这难免就会产生一些错误。
4.1 定义与声明
在同一源文件中,如果定义与声明不一致,编译时会报错,但如果定义和声明不在同一个源文件中时,则会越过编译器的检查,从而出现一些奇怪的问题。比如下面这个例子。
/********************** A.c ***********************/
float i = 20.22;
/**************************************************/
/********************** B.c ***********************/
extern unsigned char i;
/* 这里使用i时,其数据已丢失了大部分 */
printf("%d\n", i);
/**************************************************/
再有像函数的定义与声明,如果定义跟声明不一致,也会导致结果不如人意。
/********************** A.c ***********************/
unsigned char Func(unsigned char i)
{
printf("函数内打印\n");
return i;
}
/**************************************************/
/********************** B.c ***********************/
unsigned char Func(void);
int main()
{
printf("返回值:%d\n", Func());
return 0;
}
/**************************************************/
4.2 命名冲突
在同一个源文件中定义两个相同命名的变量或函数时,会出现命名冲突并编译报错,但不同的源文件中定义时,则不一定会报错,甚至ANSI C还允许你这么做。比如ANSI C标准库中提供了一部分函数,如果外部定义了相同命名的函数时,ANSI C会“隐藏名称”优先调用外部的函数。但如果同一个工程中,有第三者想要使用原本ANSI C标准库中的定义时,可能就会无意调用到被重构后的函数。解决这个问题最好的方法就是在使用区域内使用static修饰词,限制重定义的使用范围。
4.3 预编译与链接
这个首先得清楚代码的整个编译过程,首先编译器识别到预处理指令,会先进行预编译,然后再按单个文件的编译,编译成独立的.o文件,然后通过链接把独立的.o文件链接成.a文件。
因为其执行顺序如此,所以很多时候会有这样的一些异常出现,比如下面的代码,先猜猜结果打印出来是什么?
/* 枚举定义 */
enum emModuleType
{
MODULE_TYPE_normal = 0,
MODULE_TYPE_plus = 1,
};
/* 宏定义 */
#define MODULE_TYPE 1
int main(void)
{
/* 条件编译 */
#if (MODULE_TYPE == MODULE_TYPE_plus)
printf("MODULE_TYPE = MODULE_TYPE_plus\n");
#else
printf("MODULE_TYPE = MODULE_TYPE_normal\n");
#endif
}
公布答案了,结果打印的是:
MODULE_TYPE = MODULE_TYPE_normal
为什么?再看回前面说的编译的顺序,这代码先执行#开头的这些预处理,所以执行预处理的时候,enum枚举里的这两个枚举量还没被赋值,即两个均为0,于是上面的代码等效于下面这段代码。
#define MODULE_TYPE 1
int main(void)
{
#if (MODULE_TYPE == 0)
printf("MODULE_TYPE = MODULE_TYPE_plus\n");
#else
printf("MODULE_TYPE = MODULE_TYPE_normal\n");
#endif
}
5、预处理
5.1 宏定义中的空格
宏定义里的空格不可以随意加,因为宏定义的语法本身是通过空格来识别替换的主体是哪个,所以像下面这个例子,其含义将完全不同。
/* 定义一个f(x),用于替换((x) - 1) */
#define f(x) ((x) - 1)
/* 定义一个f,用于替换(x) ((x) - 1) */
#define f (x) ((x) - 1)
5.2 宏不是函数
一个司空见惯的例子,计算两数之积的宏应该如何书写。
#define MUL(x, y) (x * y)
如果像函数一样操作,下面这个计算是没有问题的,然而这 是宏,宏就是把传入的变量直接展开,这计算结果就跟原设想相差十万八千里。
/* 宏展开得到(1 + 2 * 3 + 4),结果为11而不是预想的21 */
MUL(1 + 2, 3 + 4);
5.3 宏不是语句
一般的语法习惯,都是要在语句结尾加上一个分号,如果把宏定义也当成语句使用,有时候有存在这么些尴尬的情况。比如
/* 自定义一个断言宏,如果传入e条件不满足,则终止程序 */
#define assert(e) if (!(e)) assert_error(__FILE__, __LINE__)
因为考虑到应用时语句结尾会加分号,所以宏定义这里不加分号。如果把这用在实际应用中,会有一些难以察觉的错误。
if (x > 0 && y > 0)
assert(x > y);
else
assert(x > y);
如果assert是个函数,那上面这操作是没问题的,可惜他是个宏,把他展开就变成下面这样
if (x > 0 && y > 0)
if (!(x > y)) assert_error(__FILE__, __LINE__);
else
if (!(x > y)) assert_error(__FILE__, __LINE__);
为了解决这个问题,那在宏定义后加上一个花括号
#define assert(e) {if (!(e)) assert_error(__FILE__, __LINE__);}
但这样又会出现一个新问题,按上面那方式展开后,又变成下面这样,因为在else前有个分号,变成了语法错误。
if (x > 0 && y > 0)
{if (!(x > y)) assert_error(__FILE__, __LINE__);};
else
{if (!(x > y)) assert_error(__FILE__, __LINE__);};
所以把宏完全当成语句来操作,道阻且长。不过有一种写法倒是在宏定义里比较常见的,可以解决上述问题的,就是加上do while。
#define assert(e) \
do\
{\
if (!(e)) assert_error(__FILE__, __LINE__);\
}while(0)
5.4 宏不是类型定义
有部分定义看起来跟typedef是一样的,这样就导致有些人以为他俩可以等效替换,其实不然。
typedef unsigned char* pU8
/* 使用pU8定义两个指针变量A和B */
pU8 A, B;
#define pU8 unsigned char*
/* 同样用pU8来定义两个变量,这时候直接按宏展开,会得到unsigned char *A和unsigned char B */
pU8 A, B;
所以建议所有的类型重定义都用typedef。
6、可移植性缺陷
6.1 C语言标准变更
比如下面这个写法,在C99中是支持的,但旧标准是不支持的。
int main()
{
for (int i = 0; i < 20; i++);
return 0;
}
/* 旧标准的写法 */
int main()
{
int i;
for (i = 0; i < 20; i++);
return 0;
}
6.2 系统位数
对于32位系统,int代表的是32位整形,但8位系统中,int则是代表16位的整形,这就是系统位数差异带来的数据类型差异。
为了解决这个问题,可以使用C标准库
/* Exact integral types. */
/* Signed. */
/* There is some amount of overlap with as known by inet code */
#ifndef __int8_t_defined
# define __int8_t_defined
typedef signed char int8_t;
typedef short int int16_t;
typedef int int32_t;
# if __WORDSIZE == 64
typedef long int int64_t;
# else
__extension__
typedef long long int int64_t;
# endif
#endif
/* Unsigned. */
typedef unsigned char uint8_t;
typedef unsigned short int uint16_t;
#ifndef __uint32_t_defined
typedef unsigned int uint32_t;
# define __uint32_t_defined
#endif
#if __WORDSIZE == 64
typedef unsigned long int uint64_t;
#else
__extension__
typedef unsigned long long int uint64_t;
#endif
6.3 大小端
大端指的是内部数据存取是高位在前,低位在后,小端则是相反。就单片机而论,STM32是小端系统,51单片机是大端系统。那这个差异性会带来什么影响呢?数据的高低位转换,最多是用在通信和存储这两个领域。比如现在把一个32位的数据0x12345678存储至片外Flash中,在大端系统中,存至片外时,数据为0x12345678,如果把这个片外Flash给到小端系统获取数据,同样以32位的数据进行获取,此时数据会变成0x78563412。同样的问题存在于通信领域中。
/* Flash读写接口 */
void FlashWrite(unsigned char *data, unsigned int num);
void FlashRead(unsigned char *data, unsigned int num);
/* 大端系统写入,存储的数据为0x12345678 */
unsigned int DataWrite = 0x12345678;
FlashWrite(&DataWrite, 4);
/* 小端系统读出,DataRead为0x78563412 */
unsigned int DataRead;
FlashRead(&DataRead, 4);
那消除这个问题的一种方式,就是操作数据时,全部按字节操作,并规定好统一高位在前低位在后,或低位在前高位在后。
/* Flash读写接口 */
void FlashWrite(unsigned char *data, unsigned int num);
void FlashRead(unsigned char *data, unsigned int num);
/* 32位数据转成4字节数据的数组 */
void Int32to8_HtoL(unsigned int data, unsigned char *buff)
{
buff[0] = (unsigned char)data >> (0 * 8);
buff[1] = (unsigned char)data >> (1 * 8);
buff[2] = (unsigned char)data >> (2 * 8);
buff[3] = (unsigned char)data >> (3 * 8);
}
/* 4字节数据的数组转成32位数据 */
void Int8to32_HtoL(unsigned int *data, unsigned char *buff)
{
*data = ((unsigned int)buff[0] << (0 * 8))
| ((unsigned int)buff[1] << (1 * 8))
| ((unsigned int)buff[2] << (2 * 8))
| ((unsigned int)buff[3] << (3 * 8));
}
/* 大端系统写入,存储的数据为0x12345678 */
unsigned int DataWrite = 0x12345678;
unsigned char Buff[4];
Int32to8_HtoL(DataWrite, &Buff[0]);
FlashWrite(&Buff[0], 4);
/* 小端系统读出,DataRead为0x78563412 */
unsigned int DataRead;
unsigned char Buff[4];
FlashRead(&Buff[0], 4);
Int8to32_HtoL(&DataRead, &Buff[0])
6.4 char的符号位
对于有些编译器,在不带unsigned和signed关键词的char类型,定义是不一样的。有些编译器默认char为字符,故为无符号,有些则是默认为有符号。所以建议无论数据类型是有符号还是无符号,均带上unsigned/signed关键词,或者使用标准库的定义uint8_t/int8_t。
三、参考文献
《C陷阱与缺陷》
《C专家编程》