MongoDB面试题整理-四年经验
介绍
MongoDB是一个文档数据库,提供好的性能,领先的非关系型数据库。采用BSON存储文档数据。
BSON()是一种类json的一种二进制形式的存储格式,简称Binary JSON.
相对于json多了date类型和二进制数组。
一、MongoDB的优势有哪些
- 面向文档的存储:以 JSON 格式的文档保存数据。
- 任何属性都可以建立索引。
- 复制以及高可扩展性。
- 自动分片。
- 丰富的查询功能。
- 快速的即时更新。
二、使用MongoDB的场景
- 大数据
- 内容管理系统
- 移动端Apps
- 数据管理
三、MongoDB的命名空间
mongodb存储bson对象在丛集(collection)中.数据库名字和丛集名字以句点连结起来叫做名字空间(namespace).
-
一个集合命名空间又有多个数据域(extent),集合命名空间里存储着集合的元数据,比如集合名称,集合的第一个数据域和最后一个数据域的位置等等。而一个数据域由若干条文档(document)组成,每个数据域都有一个头部,记录着第一条文档和最后一条文档的为知,以及该数据域的一些元数据。
-
extent之间,document之间通过双向链表连接。 索引的存储数据结构是B树,索引命名空间存储着对B树的根节点的指针。
四、MongoDB的数据类型
String
Integer
Double
Boolean
Object
Object ID
Arrays
Min/Max Keys
Datetime
Code
Regular Expression等
Code是用来存储代码的。
正则表达式则是在文档中存储正则。
五、ObjectID有哪几部分组成
时间戳、客户端ID、客户进程ID、三个字节的增量计数器
- 前4个字节表示时间戳;
- 接下来的3个字节是机器标识码;
- 紧接的两个字节由进程id组成(PID);
- 最后三个字节是自增计数器生成的随机数;
六、副本集与主从同步
1. 选举
-
如果主挂了,mongodb保证只有操作序列为最大的从才能成为新的主,这只保证了数据尽可能地少丢,如果写操作是写1个节点以上成功才认为成功,可保证不丢数据
-
如果新的主丢了老的主的部分操作,而且老的主又重新加入副本集,这时老的主会回滚操作以保证与新的主状态一致。回滚日志会被记录到文件里,通过工具可手动将回滚操作来新的主上执行,以恢复数据。另外,如果需要的回滚数据超过300M,老的主不会进行回滚,并log异常;如果要强制回滚到300M之前,可采用重新同步数据的方法来保证与新主状态一致,但不能恢复这300M数据了。
-
mongodb可保证优先级最高的从节点变为主;
-
优先级为0的从节点不进行选主,即不能成为主;
-
除了主从节点,还有仲裁者节点,不保存副本数据,只用于选主投
2.变更主从
副本集支持手动变更主从关系吗?支持的话,变更会不会出现数据丢失呢?可对比下redis cluster
(1)You can force a replica set member to become primary by giving it a higher priority value than any other member in the set.(所以是支持的)
(2)变更不会出现数据丢失,因为mongodb会停止原主的更新操作,直到新主追上最新的plog后并成功变为主,才恢复更新操作(跟redis cluster的no force变更策略一样)。
副本集一般是三个数据库。
七、WiredTiger存储引擎
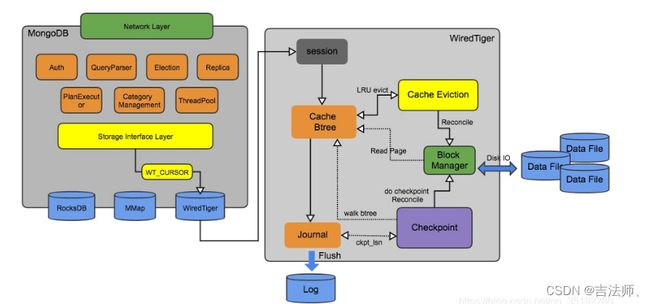
- Session 模块:负责和wt引擎上层交互的句柄,每个session会关联多个cursor,cursor属于一个session
- cache 模块:主要有内存中的btree page(数据页,索引页,溢出页)构成
- evict 模块:如果cache内存紧张,触发cache淘汰,遍历btree,并根据lru排序淘汰
- Journal 模块:WAL log,类似InnoDB的redolog,保证数据持久化,通过定时和定量阈值来flush
- checkpoint 模块:类似InnoDB checkpoint机制,异步执行btree刷盘,checkpoint之后通知log模块更新log_ckpt_lsn(lsn概念和InnoDB一致)
- block manager模块:负责磁盘IO的读写,cache、evict、checkpoint模块均通过该模块访问磁盘
存储数据结构
在介绍WiredTiger的数据组织前,先来看看传统数据库引擎的数据组织方式,一般存储引擎都是采用btree或者lsm tree来实现索引,但是索引的最小单位不是K/V记录对象,而是数据页,数据页的组织关系实现就是存储引擎的数据组织方式。传统数据库引擎大都是设计一个磁盘和内存完全一样的数据组织方式,这个结构是固定的空间大小。而WT没有像传统的数据库引擎那样设计一套内存和磁盘page完全一致的数据组织方式,而是针对磁盘和CPU、内存三者之间特点设计了一套独特的数据组织方式,这种数据组织结构分为两部分:
- In-memory page: 内存中的数据页(page)
- On-disk extent:基于磁盘文件的偏移量的范围存储
WT内存中的page是一个松散自由的数据结构,而磁盘上的extent只是一个变长的经过了序列化的数据块,这样做的目的(设计目标)有以下几点:
- 内存中的page松散结构可以不受磁盘存储方式的限制,可以自由的构建page的无锁多核并发结构,充分发挥CPU多核的能力。
- 可以自由的在内存page和磁盘extent之间实现数据的压缩,提高磁盘的存储效率和减少I/O访问时间
磁盘数据结构
对于WiredTiger存储引擎来说,集合所在的数据文件和相应的索引文件都是按B-Tree结构来组织的,不同之处在于数据文件对应的B-Tree叶子结点上除了存储键名外(keys),还会存储真正的集合数据(values),所以数据文件的存储结构也可以认为是一种B+Tree,其对应于磁盘的数据组织结构如下图所示:
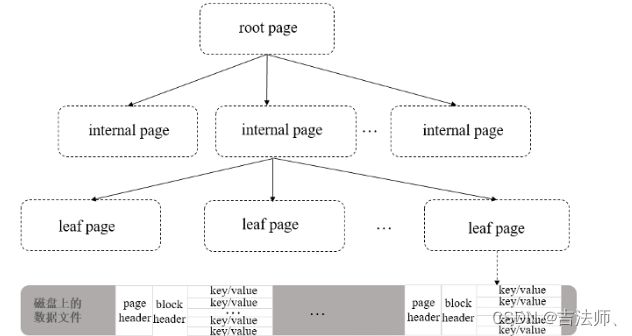
图中B+Tree在磁盘上的一个page(leaf page与internal page)也被称作一个extent,包含一个页头(page header)、块头(block header)和真正的数据(key/value)。

Page header主要存储了extent的类型、extent中实际载荷数据的大小、extent中key与value的条目总数等信息(源码见src/inclue/btmem.h:__wt_page_header);block header主要存储了extent的实际盘上大小、extent的checksum值等信息(源码见src/include/block.h: __wt_block_header)。
Extent data是真正存储page数据的地方,它是page中所有k/v的序列化内容集合。对于internal page来说,key/value分别表示子page的查找key以及子page在磁盘上位置的address cookie,也就是
内存数据结构
WiredTiger会按需将磁盘的数据以extent为单位加载到内存的in-memory page,在这里我们统称为page,与extent区分开。WT中的page分为以下几类:
- row internal page: 行存储b-tree的索引页
- row leaf page: 行存储b-tree的数据页
- column internal page: 列存储b-tree的索引页
- column fix leaf page: 列存储b-tree的定长数据页
- column var leaf page: 列存储b-tree的变长数据页
内存B+Tree的大致结构:
- 基本page类型:root page(btree根页面,是特殊的索引页)、internal page(索引页)、leaf page(数据页,叶子页)
- 结构:每个page包含在一个ref(可以看作page的容器)里,root/internal page包含一个ref数组,这里我们统称为index array,指向子page的ref。每个ref包含一个指向父page的home元素、指向自身page的page元素以及一个标识page所在磁盘文件位置的addr元素和一个标识自身page的索引key等(图3.4用于表现ref与page的关系,因此只标注了home与page元素)。

后面基本够了,主要是知道查询是先从磁盘找到数据页,在内存中B+树的结构基本也够了。
官网说了用的WireTiger的引擎,而这个引擎明确说了是B+树索引
八、MongoDB和MySQL应用场景的区别
MongoDB的应用场景
MongoDB的应用场景
1)表结构不明确且数据不断变大
MongoDB是非结构化文档数据库,扩展字段很容易且不会影响原有数据。内容管理或者博客平台等,例如圈子系统,存储用户评论之类的。
2)更高的写入负载
MongoDB侧重高数据写入的性能,而非事务安全,适合业务系统中有大量“低价值”数据的场景。本身存的就是json格式数据。例如做日志系统。
3)数据量很大或者将来会变得很大
Mysql单表数据量达到5-10G时会出现明细的性能降级,需要做数据的水平和垂直拆分、库的拆分完成扩展,MongoDB内建了sharding、很多数据分片的特性,容易水平扩展,比较好的适应大数据量增长的需求。
4)高可用性
自带高可用,自动主从切换(副本集)
不适用的场景
1)MongoDB不支持事务操作,需要用到事务的应用建议不用MongoDB。
2)MongoDB目前不支持join操作,需要复杂查询的应用也不建议使用MongoDB。
关系型数据库和非关系型数据库的应用场景对比
关系型数据库适合存储结构化数据,如用户的帐号、地址:
1)这些数据通常需要做结构化查询,比如join,这时候,关系型数据库就要胜出一筹
2)这些数据的规模、增长的速度通常是可以预期的
3)事务性、一致性
NoSQL适合存储非结构化数据,如文章、评论:
1)这些数据通常用于模糊处理,如全文搜索、机器学习
2)这些数据是海量的,而且增长的速度是难以预期的,
3)根据数据的特点,NoSQL数据库通常具有无限(至少接近)伸缩性
4)按key获取数据效率很高,但是对join或其他结构化查询的支持就比较差
MongoDB更适合使用内嵌文档进行更新,因为数据库本身Join的性能较差。