转载scrapy框架解析
微信搜索关注「水滴与银弹」公众号,第一时间获取优质技术干货。7年资深后端研发,用简单的方式把技术讲清楚。
在爬虫开发领域,使用最多的主流语言主要是 Java 和 Python 这两种,如果你经常使用 Python 开发爬虫,那么肯定听说过 Scrapy 这个开源框架,它正是由Python编写的。
Scrapy 在开源爬虫框架中名声非常大,几乎用 Python 写爬虫的人,都用过这个框架。而且业界很多开源的爬虫框架都是模仿和参考 Scrapy 的思想和架构实现的,如果想深入学习爬虫,研读 Scrapy 的源码还是很有必要的。
从这篇文章开始,我就和你分享一下当时我在做爬虫时,阅读 Scrapy 源码的思路和经验总结。
这篇文章我们先来介绍一下 Scrapy 的整体架构,从宏观层面上学习一下 Scrapy 运行的流程。之后的几篇文章,我会带你深入到每个模块,剖析这个框架的实现细节。
介绍
首先,我们先来看一下 Scrapy 的官方是如何介绍它的。从官方网站,我们可以看到 Scrapy 如下定义。
Scrapy 是一个基于 Python 语言编写的开源爬虫框架,它可以帮你快速、简单的方式构建爬虫,并从网站上提取你所需要的数据。
也就是说,使用 Scrapy 能帮你快速简单的编写一个爬虫,用来抓取网站数据。
本篇文章不再介绍 Scrapy 的安装和使用,这个系列主要通过阅读源码讲解 Scrapy 的实现思路,关于如何安装和使用的问题,请参考官方网站和官方文档学习。(注:写本篇文章时,Scrapy 版本为1.2,虽然版本有些低,但与最新版的实现思路基本没有很大出入。)
使用 Scrapy 开发一个爬虫非常简单,这里使用 Scrapy 官网上的例子来说明如何编写一个简单爬虫:
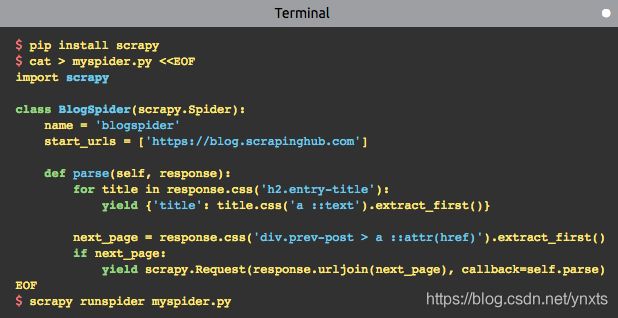
简单来讲,编写和运行一个爬虫只需以下几步:
- 使用
scrapy startproject命令创建一个爬虫模板,或自己按模板编写爬虫代码 - 定义一个爬虫类,并继承
scrapy.Spider,然后重写parse方法 parse方法里编写网页解析逻辑,以及抓取路径- 使用
scrapy runspider运行这个爬虫
可见,使用 Scrapy 编写简单的几行代码,就能采集到一个网站页面的数据,非常方便。
但是在这背后到底发生了什么?Scrapy 到底是如何帮助我们工作的呢?
架构
要想知道 Scrapy 是如何工作的,首先我们来看一下 Scrapy 的架构图,从宏观角度来了解一下它是如何运行的:

核心模块
从架构图可以看到,Scrapy 主要包含以下五大模块:
Scrapy Engine:核心引擎,负责控制和调度各个组件,保证数据流转;Scheduler:负责管理任务、过滤任务、输出任务的调度器,存储、去重任务都在此控制;Downloader:下载器,负责在网络上下载数据,输入待下载的 URL,输出下载结果;Spiders:我们自己编写的爬虫逻辑,定义抓取意图;Item Pipeline:负责输出结构化数据,可自定义格式和输出的位置;
如果你观察地比较仔细的话,可以看到还有两个模块:
Downloader middlewares:介于引擎和下载器之间,可以在网页在下载前、后进行逻辑处理;Spider middlewares:介于引擎和爬虫之间,在向爬虫输入下载结果前,和爬虫输出请求 / 数据后进行逻辑处理;
了解了这些核心模块,我们再来看使用 Scrapy 时,它内部的采集流程是如何流转的,也就是说各个模块是如何交互协作,来完成整个抓取任务的。
运行流程
按照上面架构图标识出的序号,我们可以看到,Scrapy 运行时的数据流转大概是这样的:
- 引擎从自定义爬虫中获取初始化请求(也叫种子 URL);
- 引擎把该请求放入调度器中,同时调度器向引擎获取待下载的请求;
- 调度器把待下载的请求发给引擎;
- 引擎发送请求给下载器,中间会经过一系列下载器中间件;
- 这个请求通过下载器下载完成后,生成一个响应对象,返回给引擎,这中间会再次经过一系列下载器中间件;
- 引擎接收到下载器返回的响应后,发送给爬虫,中间会经过一系列爬虫中间件,最后执行爬虫自定义的解析逻辑;
- 爬虫执行完自定义的解析逻辑后,生成结果对象或新的请求对象给引擎,再次经过一系列爬虫中间件;
- 引擎把爬虫返回的结果对象交由结果处理器处理,把新的请求通过引擎再交给调度器;
- 重复执行1-8,直到调度器中没有新的请求处理,任务结束;
核心模块的协作
可见,Scrapy 的架构图还是比较清晰的,各个模块之间互相协作,完成抓取任务。
我在读完它的源码后,整理出了一个更详细的核心模块交互图,其中展示了更多模块的相关细节,你可以参考一下:
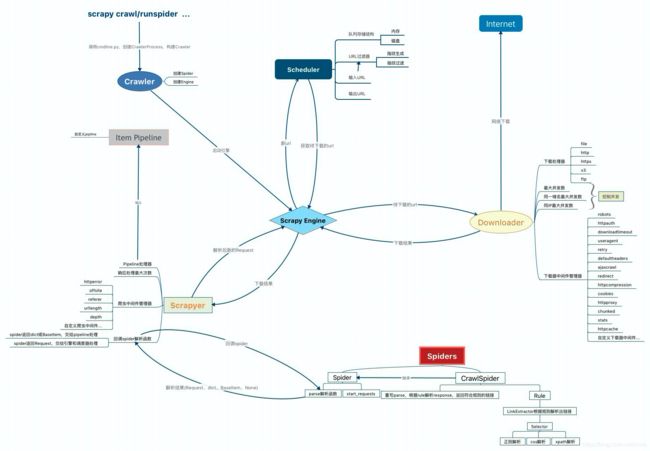
这里需要说明一下图中的 Scrapyer 模块,其实这也是 Scrapy 的一个核心模块,但官方的架构图中没有展示出来。这个模块其实是处于 Engine、Spiders、Pipeline 之间,是连接这 3 个模块的桥梁,我会在后面的源码分析文章中具体讲到。
核心类图
另外,在读源码的过程中,我还整理了这些核心模块的类图,这对于你学习源码会有很大的帮助。

对于这个核心类图简单解释一下:
- 没有样式的黑色文字是类的核心属性;
- 标有黄色样式的高亮文字是类的核心方法;
你在读源码的过程中,可以针对这些核心属性和方法重点关注。
结合官方架构图以及我总结的核心模块交互图、核心类图,我们可以看到,Scrapy 涉及到的组件主要包括以下这些。
- 五大核心类:
Scrapy Engine、Scheduler、Downloader、Spiders、Item Pipeline; - 四个中间件管理器类:
DownloaderMiddlewareManager、SpiderMiddlewareManager、ItemPipelineMiddlewareManager、ExtensionManager; - 其他辅助类:
Request、Response、Selector;
我们先对 Scrapy 整个架构有一个初步认识,在接下来的文章里,我会针对上述的这些类和方法进行更加详细的源码讲解。
微信搜索关注「水滴与银弹」公众号,第一时间获取优质技术干货。7年资深后端研发,用简单的方式把技术讲清楚。