Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
Python使用Scrapy框架爬取数据存入CSV文件(Python爬虫实战4)
1. Scrapy框架
Scrapy是python下实现爬虫功能的框架,能够将数据解析、数据处理、数据存储合为一体功能的爬虫框架。
2. Scrapy安装
1. 安装依赖包
| 1 2 |
|
2. 安装scrapy
| 1 |
|
注意事项:scrapy和twisted存在兼容性问题,如果安装twisted版本过高,运行scrapy startproject project_name的时候会提示报错,安装twisted==13.1.0即可。
3. 基于Scrapy爬取数据并存入到CSV
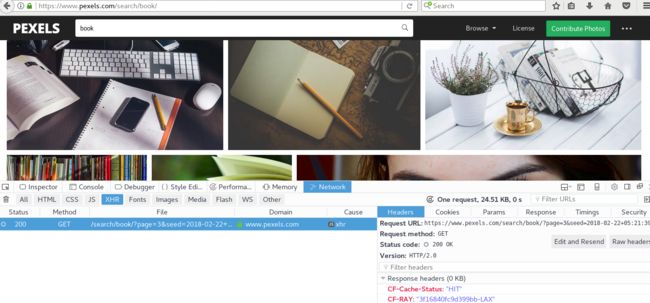
3.1. 爬虫目标,获取简书中热门专题的数据信息,站点为https://www.jianshu.com/recommendations/collections,点击"热门"是我们需要爬取的站点,该站点使用了AJAX异步加载技术,通过F12键——Network——XHR,并翻页获取到页面URL地址为https://www.jianshu.com/recommendations/collections?page=2&order_by=hot,通过修改page=后面的数值即可访问多页的数据,如下图:
3.2. 爬取内容
需要爬取专题的内容包括:专题内容、专题描述、收录文章数、关注人数,Scrapy使用xpath来清洗所需的数据,编写爬虫过程中可以手动通过lxml中的xpath获取数据,确认无误后再将其写入到scrapy代码中,区别点在于,scrapy需要使用extract()函数才能将数据提取出来。
3.3 创建爬虫项目
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
|
3.4 代码内容
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 |
|
3.5 运行scrapy爬虫
返回到项目scrapy项目创建所在目录,运行scrapy crawl spider_name即可,如下:
| 1 2 3 4 5 6 |
|
查看/root/zhuanti.csv中的数据,即可实现。
4. 遇到的问题总结
1. twisted版本不见容,安装过新的版本导致,安装Twisted (13.1.0)即可
2. 中文数据无法写入,提示'ascii'错误,通过设置python的encoding为utf即可,如下:
| 1 2 3 4 5 6 7 8 |
|
3. 爬虫无法获取站点数据,由于headers导致,载settings.py文件中添加USER_AGENT变量,如:
| 1 |
|
Scrapy使用过程中可能会遇到结果执行失败或者结果执行不符合预期,其现实的logs非常详细,通过观察日志内容,并结合代码+网上搜索资料即可解决。