Linux驱动编程(驱动程序基石)(下)
一、中断的线程化处理
复杂、耗时的事情,尽量使用内核线程来处理。上节视频介绍的工作队列用起来挺简单,但是它有一个缺点:工作队列中有多个 work,前一个 work 没处理完会影响后面的 work。解决方法有很多种,比如干脆自己创建一个内核线程,不跟别的 work 凑在一块了。
对于中断处理,还有另一种方法:threaded irq,线程化的中断处理。中断的处理仍然可以认为分为上半部、下半部。上半部用来处理紧急的事情,下半部用一个内核线程来处理,这个内核线程专用于这个中断。
 你可以只提供 thread_fn,系统会为这个函数创建一个内核线程。发生中断时,系统会立刻调用 handler函数,然后唤醒某个内核线程,内核线程再来执行 thread_fn 函数。
你可以只提供 thread_fn,系统会为这个函数创建一个内核线程。发生中断时,系统会立刻调用 handler函数,然后唤醒某个内核线程,内核线程再来执行 thread_fn 函数。
8.1、内核机制
调用 request_threaded_irq 后内核的数据结构
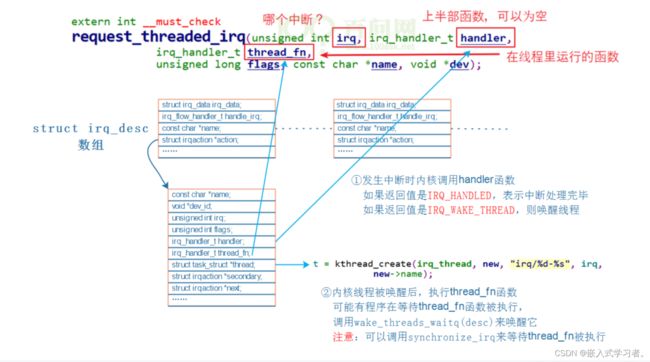
request_threaded_irq
request_threaded_irq 函数,肯定会创建一个内核线程。
int request_threaded_irq(unsigned int irq, irq_handler_t handler,irq_handler_t thread_fn, unsigned long irqflags,const char *devname, void *dev_id)
{
// 分配、设置一个 irqaction 结构体
action = kzalloc(sizeof(struct irqaction), GFP_KERNEL);
if (!action)
return -ENOMEM;
action->handler = handler;
action->thread_fn = thread_fn;
action->flags = irqflags;
action->name = devname;
action->dev_id = dev_id;
retval = __setup_irq(irq, desc, action); // 进一步处理
}
__setup_irq 函数代码如下(只摘取重要部分):
if (new->thread_fn && !nested) {
ret = setup_irq_thread(new, irq, false);
setup_irq_thread 函数代码如下(只摘取重要部分):
if (!secondary)
{
t = kthread_create(irq_thread, new, "irq/%d-%s", irq,new->name);
}
else
{
t = kthread_create(irq_thread, new, "irq/%d-s-%s", irq,new->name);
param.sched_priority -= 1;
}
new->thread = t;
二、mmap
应用程序和驱动程序之间传递数据时,可以通过 read、write 函数进行。这涉及在用户态 buffer 和内核态 buffer 之间传数据,如下图所示:
 2.1、内存映射现象与数据结构
2.1、内存映射现象与数据结构
假设有这样的程序,名为 test.c:
#include \n" , argv[0]);
return -1;
}
a = strtol(argv[1], NULL, 0);
printf("a's address = 0x%lx, a's value = %d\n", &a, a);
while (1)
{
sleep(10);
}
return 0;
}
在 PC 上如下编译(必须静态编译):
gcc -o test test.c -staitc
分别执行 test 程序 2 次,最后执行 ps,可以看到这 2 个程序同时存在,这 2 个程序里 a 变量的地址相同,但是值不同。如下图:

观察到这些现象:
① 2 个程序同时运行,它们的变量 a 的地址都是一样的:0x6bc3a0;
② 2 个程序同时运行,它们的变量 a 的值是不一样的,一个是 12,另一个是 123。
疑问来了:
① 这 2 个程序同时在内存中运行,它们的值不一样,所以变量 a 的地址肯定不同;
② 但是打印出来的变量 a 的地址却是一样的。
这里要引入虚拟地址的概念:CPU 发出的地址是虚拟地址,它经过 MMU(Memory Manage Unit,内存管理单元)映射到物理地址上,对于不同进程的同一个虚拟地址,MMU 会把它们映射到不同的物理地址。如下图:
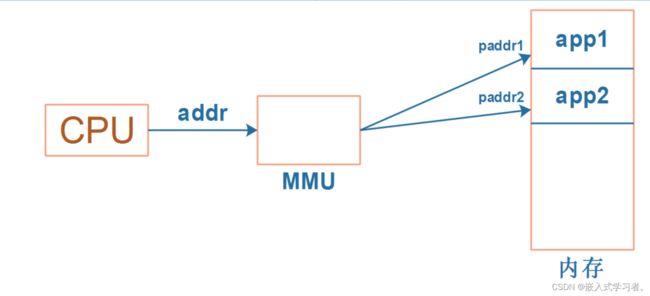
当前运行的是 app1 时,MMU 会把 CPU 发出的虚拟地址 addr 映射为物理地址 paddr1,用 paddr1 去访问内存。
当前运行的是 app2 时,MMU 会把 CPU 发出的虚拟地址 addr 映射为物理地址 paddr2,用 paddr2 去访问内存。
MMU 负责把虚拟地址映射为物理地址,虚拟地址映射到哪个物理地址去?
可以执行 ps 命令查看进程 ID,然后执行“cat /proc/325/maps”得到映射关系。
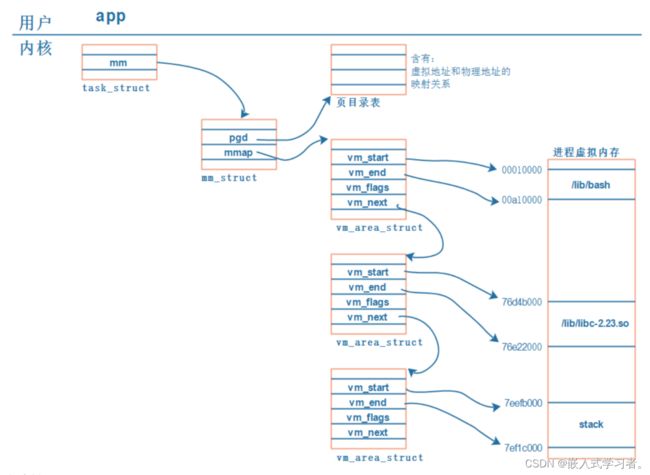
每一个 APP 在内核里都有一个 tast_struct,这个结构体中保存有内存信息:mm_struct。而虚拟地址、物理地址的映射关系保存在页目录表中,如下图所示:
2.2、怎么给 APP 新建一块内存映射
1、mmap 调用过程
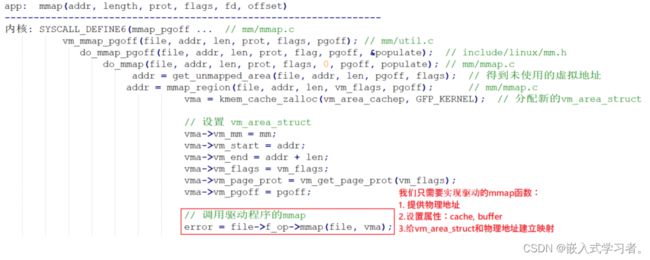
① 得到一个 vm_area_struct,它表示 APP 的一块虚拟内存空间;
APP 调用 mmap 系统函数时,内核就帮我们构造了一个 vm_area_stuct 结构体。里面含有虚拟地址的地址范围、权限。
② 确定物理地址
你想映射某个内核 buffer,你需要得到它的物理地址,这得由你提供。
③ 给 vm_area_struct 和物理地址建立映射关系
APP 里调用 mmap 时,导致的内核相关函数调用过程如下:
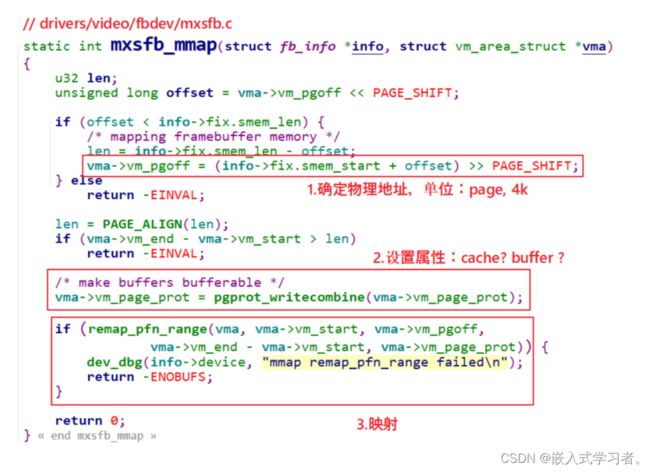
3、驱动程序要做的事
驱动程序要做的事情有 3 点:
① 确定物理地址
② 确定属性:是否使用 cache、buffer
③ 建立映射关系
参考 Linux 源文件,示例代码如下:
还有一个更简单的函数:

4、APP 编程
APP 怎么写?open 驱动、buf=mmap(……)映射内存,直接读写 buf 就可以了,代码如下:
/* 1. 打开文件 */
fd = open("/dev/hello", O_RDWR);
if (fd == -1)
{
printf("can not open file /dev/hello\n");
return -1;
}
/* 2. mmap
* MAP_SHARED : 多个 APP 都调用 mmap 映射同一块内存时, 对内存的修改大家都可以看到。
* 就是说多个 APP、驱动程序实际上访问的都是同一块内存
* MAP_PRIVATE : 创建一个 copy on write 的私有映射。
* 当 APP 对该内存进行修改时,其他程序是看不到这些修改的。
* 就是当 APP 写内存时, 内核会先创建一个拷贝给这个 APP,
* 这个拷贝是这个 APP 私有的, 其他 APP、驱动无法访问。
*/
buf = mmap(NULL, 1024*8, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
if (buf == MAP_FAILED)
{
printf("can not mmap file /dev/hello\n");
return -1;
}
printf("mmap address = 0x%x\n", buf);
printf("buf origin data = %s\n", buf); /* old */
/* 3. write */
strcpy(buf, "new");
/* 4. read & compare */
/* 对于 MAP_SHARED 映射: str = "new"
* 对于 MAP_PRIVATE 映射: str = "old"
*/
read(fd, str, 1024);
if (strcmp(buf, str) == 0)
{
/* 对于 MAP_SHARED 映射,APP 写的数据驱动可见
* APP 和驱动访问的是同一个内存块
*/
printf("compare ok!\n");
}
else
{
/* 对于 MAP_PRIVATE 映射,APP 写数据时, 是写入另一个内存块(是原内存块的"拷贝")
*/
printf("compare err!\n");
printf("str = %s!\n", str); /* old */
printf("buf = %s!\n", buf); /* new */
}
5、驱动编程
① 分配一块 8K 的内存
使用哪一个函数分配内存?

② 提供 mmap 函数
关键在于 mmap 函数,代码如下:

要注意的是,remap_pfn_range 中,pfn 的意思是“Page Frame Number”。在 Linux 中,整个物理地址空间可以分为第 0 页、第 1 页、第 2 页,诸如此类,这就是 pfn。假设每页大小是 4K,那么给定物理地址phy,它的 pfn = phy / 4096 = phy >> 12。内核的 page 一般是 4K,但是也可以配置内核修改 page 的大小。所以为了通用,pfn = phy >> PAGE_SHIFT。