最强的AI视频去码&图片修复模型:CodeFormer
目录
1 CodeFormer介绍
1.1 CodeFormer解决的问题
1.2 人脸复原的挑战
1.3 方法动机
1.4 模型实现
1.5 实验结果
2 CodeFormer部署与运行
2.1 conda环境安装
2.2 运行环境构建
2.3 模型下载
2.4 运行
2.4.1 人脸复原
编辑编辑
2.4.2 全图片增强
2.4.3 人脸颜色增强
2.4.4 人脸补全
2.4.5 视频增强
3 安装问题定位与解决
3.1 安装错误描述
3.2 问题分析
3.3 问题解决
1 CodeFormer介绍
1.1 CodeFormer解决的问题
CodeFormer是由南洋理工大学-商汤科技联合研究中心S-Lab在NeurIPS 2022上提出的一种基于VQGAN+Transformer的人脸复原模型。该方法基于预训练VQGAN离散码本空间,改变复原任务的固有范式,将人脸复原任务转成Code序列的预测任务,大幅度降低了复原任务映射的不确定性,同时VQGAN的码本先验也为复原任务提供了丰富的人脸细节。最后,通过Transformer全局建模,进一步增加了模型对严重退化的鲁棒性,使得复原的人脸更加真实。
- 论文地址:https://arxiv.org/pdf/2206.11253.pdf
- 代码地址:https://github.com/sczhou/CodeFormer

主要用途:
- 老照片修复与增强
- 面部修复
- 面部颜色增强和修复
- 马赛克还原
1.2 人脸复原的挑战
人脸复原任务面临的诸多挑战:
图片复原任务中的共性问题:高度不适定性。
低清图像(LQ)和潜在的高清图像(HQ)存在多对多的映射关系,如下图所示。这种多解的映射使得网络在学习过程中产生疑惑,无法获得一个高质量的输出,且退化越严重,这种不适应性就会越大。“如何才能降低这种映射的不确定性”是其挑战之一。

纹理细节丢失
从上图可以看出,真实场景的低清人脸图片中往往会引入各种退化,包括噪声、JPEG压缩伪影、模糊、下采样等。这些退化不同程度地损害了原有人脸纹理细节,造成信息丢失。“如何更好地补充真实高清纹理”也一直是人脸复原的一大难题。
人脸身份丢失
以上两点都会导致人脸复原的结果很难保持身份的一致性。然而现实应用中又往往对输出人脸的身份一致性有着很高的要求,在输出高清人脸细节的同时,又要与低清人脸的身份保持一致,这无疑增加了复原过程的难度。
1.3 方法动机
我们首先引入了VQGAN的离散码本空间来缓解以上 (1)、(2) 两个问题。有限且离散的映射空间大大降低了复原任务映射的不适定性 (1)。通过VQGAN的自重建训练,码本先验保存了丰富的高清人脸纹理信息,帮助复原任务补充真实的人脸纹理细节 (2)。
如下图所示,相比连续先验空间 (d、e),离散码本空间 (f、g) 可以输出更高质量的结果 (没有伪影),保持完好脸庞轮廓的同时,也展现出更真实、细致的纹理。

如何更准确地得到Code序列呢?我们对比分析了两种不同Code序列的查找方式:最近邻特征查找 (f) 和基于Transformer预测 (g),我们发现基于Transformer预测 (g)会得到更准确的Code序列,即生成更高质量的人脸图像且保持更好的身份一致性,如上图所示。
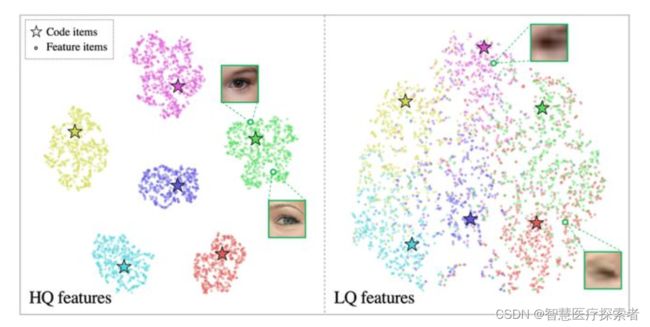
我们进一步发现,基于VQGAN最近邻特征查找的Code序列查询方式并不适用于低清图像。通过对高清 (HQ) 和低清 (LQ) 特征进行聚类可视化,我们分析了原因,如上图所示。
由于VQGAN的码本通过存储HQ的Code来重建高清人脸图,HQ特征分布在准确的Code簇附近,因此HQ特征可以通过最近邻来进行Code查找。然而,LQ特征丢失了大量的纹理信息,导致其分布到错误的Code簇中 (即便Finetune过Encoder)。
由此得出,最近邻Code查找对于LQ特征并不是最优的解决方案,我们通过Transformer进行全局人脸建模,缓解了局部特征最近邻查找带来的不准确性,从而找到更准确的Code序列,使得模型对严重细节损失更为鲁棒,复原的人脸图片也更加自然。
虽然Transformer可以缓解身份不一致的问题 (3),但由于VQGAN的码本空间并不能100%完美地重建出任意人脸,比如个人特有面部特征或首饰,因此引入可调节特征融合模块来控制对输入LQ人脸的依赖。
当输入LQ图像退化轻微时,LQ特征很好地保留了个人的身份信息,因此该模块倾向于融合更多的输入信息,使得模型输出和输入图保持身份一致;当输入LQ图像退化严重时,LQ特征中个人的身份信息已经严重损坏且包含了大量的退化噪声,无法对输出身份一致性提供太大的帮助,因此该模块倾向于融合较少的输入信息,从而降低退化对输出质量的影响。
1.4 模型实现
了解本文动机后,这里简单介绍一下本文方法,实现细节请查看原文和代码。
该方法分为3个训练过程:

Stage I:Codebook Learning
首先通过高清人脸自我重建学习,训练VQGAN,从而得到HQ码本空间作为本文的离散人脸先验。为了降低LQ-HQ映射之间的不确定性,我们设计尽量小的码本空间和尽量短的Code序列作为人脸的离散表达。因此,我们采用了大的压缩比 (32倍),即将原来的人脸图片压缩为的离散Code序列。该设计使得码本中Code具有更丰富的上下文信息,有助于提升网络表达能力以及鲁棒性。
Stage II:Codebook Lookup Transformer Learning
基于得到的码本空间,我们在原来Encoder后又嵌入一个Transformer模块对特征全局建模,以达成更好的Code序列预测。该阶段固定Decoder和Codebook,只需学习Transformer模块并微调Encoder。将原本的复原任务转变为离散Code序列预测任务,改变了复原任务的固有范式,这也是本文的主要贡献之一。
Stage III:Controllable Feature Transformation
尽管Stage II已经实现非常好的人脸复原,我们还希望在人脸复原的质量和保真方面达成更灵活的权衡。因此,该阶段引入可控特征融合模块 (CFT) 来控制Encoder特征和Decode特征 的融合,即:

从而达到:当调小,模型输出质量更高;当调大,模型输出能保持更好的身份一致性。如下图示例,随着 变大,输出人脸身份越来越像输入图,个人特征 (如眉中痔) 也逐渐恢复。

1.5 实验结果
CodeFormer在人脸复原、人脸颜色增强以及人脸补全三个任务上均表现出了优势,此处只展示输出结果,和其他方法的对比和消融实验请查看原文。
- 人脸复原

- 人脸补全

- 人脸颜色增强

- AI生成人脸校正

- 老照片修复



2 CodeFormer部署与运行
2.1 conda环境安装
conda环境准备详见:annoconda
2.2 运行环境构建
git clone https://github.com/sczhou/CodeFormer
cd CodeFormer
conda create -n codeformer python=3.9
conda activate codeformer
pip install -r requirements.txt
python basicsr/setup.py develop2.3 模型下载
python scripts/download_pretrained_models.py facelib
python scripts/download_pretrained_models.py CodeFormerparsing_parsenet 下载模型存储到weights/facelib/目录下
codeformer_colorization下载模型存储到weights/CodeFormer/目录下
codeformer_inpainting下载模型存储到weights/CodeFormer/目录下
RealESRGAN_x2plus下载模型存储到weights/realesrgan/目录下
2.4 运行
2.4.1 人脸复原
python inference_codeformer.py -w 0.5 --has_aligned --input_path inputs/cropped_faces/0143.png

2.4.2 全图片增强
python inference_codeformer.py -w 0.7 --input_path inputs/whole_imgs/03.jpg 
2.4.3 人脸颜色增强
python inference_colorization.py --input_path inputs/cropped_faces/0368.png

2.4.4 人脸补全
python inference_inpainting.py --input_path inputs/masked_faces/00105.png

2.4.5 视频增强
python inference_codeformer.py --bg_upsampler realesrgan --face_upsample -w 1.0 --input_path inputs/test.mp43 安装问题定位与解决
3.1 安装错误描述
安装依赖过程中出现如下错误:
ERROR: HTTP error 404 while getting https://pypi.doubanio.com/packages/66/9a/b6d21ad7d69ce6f78d57bf4cb6382c2121811deeb128c57da22b042fe147/tb_nightly-2.15.0a20230902-py3-none-any.whl#sha256=11ed86269422f5fe48208c732956ac5633b9b76eed5bfed587a0621ce39275b1 (from https://pypi.doubanio.com/simple/tb-nightly/) (requires-python:>=3.9)
ERROR: Could not install requirement tb-nightly from https://pypi.doubanio.com/packages/66/9a/b6d21ad7d69ce6f78d57bf4cb6382c2121811deeb128c57da22b042fe147/tb_nightly-2.15.0a20230902-py3-none-any.whl#sha256=11ed86269422f5fe48208c732956ac5633b9b76eed5bfed587a0621ce39275b1 (from -r requirements.txt (line 11)) because of HTTP error 404 Client Error: Not Found for url: https://mirrors.cloud.tencent.com/pypi/packages/66/9a/b6d21ad7d69ce6f78d57bf4cb6382c2121811deeb128c57da22b042fe147/tb_nightly-2.15.0a20230902-py3-none-any.whl for URL https://pypi.doubanio.com/packages/66/9a/b6d21ad7d69ce6f78d57bf4cb6382c2121811deeb128c57da22b042fe147/tb_nightly-2.15.0a20230902-py3-none-any.whl#sha256=11ed86269422f5fe48208c732956ac5633b9b76eed5bfed587a0621ce39275b1 (from https://pypi.doubanio.com/simple/tb-nightly/) (requires-python:>=3.9)3.2 问题分析
从错误信息可知,doubanio源中没有tb-nightly这个包
3.3 问题解决
指定aliyun镜像安装tb_nightly
pip install tb_nightly==2.15.0a20230902 -i https://mirrors.aliyun.com/pypi/simple