一个模型解决所有类别的异常检测
文章目录
- 一、内容说明
- 二、相关链接
- 三、概述
- 四、摘要
-
- 1、现有方法存在的问题
- 2、方案
- 3、效果
- 五、作者的实验
- 六、如何训练自己的数据
-
- 1、数据准备
- 2、修改配置文件
- 3、代码优化修改
- 4、模型训练与测试
- 七、结束
一、内容说明
- 在我接触的缺陷检测项目中,检测缺陷有两种方法。一种是使用传统方法,采用去噪、二值化、轮廓检测等,但传统方法很受阈值的影响,往往这张图片适用,那张图片就不行,很难调好阈值。另外一种是使用深度学习方法,例如本篇文章的UniAD,也有朋友使用语义分割的方式。
- 在本文章,我将会介绍无监督缺陷检测算法UniAD的创新点、网络以及如何应用在自己的项目中。
- 最后来一句“决定我们自身的不是过去的经历,而是我们自己赋予经历的意义”,来自《被讨厌的勇气》
二、相关链接
论文名称:《A Unified Model for Multi-class Anomaly Detection》
Github:https://github.com/zhiyuanyou/UniAD
Paper:https://arxiv.org/abs/2206.03687.pdf
三、概述
UniAD是由一个邻居掩码编码器(NME) 和一个分层查询解码器(LQD) 组成。
首先,由固定的预训练骨干网络提取的特征token被NME进一步整合,以得出编码器嵌入。然后,在LQD的每一层中,可学习的查询嵌入与编码器嵌入和前一层的输出相继融合(第一层为自我融合)。特征融合是由邻居掩码注意力(NMA)完成的。LQD的最终输出被看作是重构的特征。此外,还提出了一个特征抖动(FJ)策略,向输入特征添加扰动,引导模型从去噪任务中学习正态分布。最后,通过重建差异得到异常定位和检测的结果。
通俗说法:我已经学习了正常图片是什么样子,输入一张缺陷图,我就重构出它的正常图,将正常图和输入图做对比,不就知道哪里有缺陷了
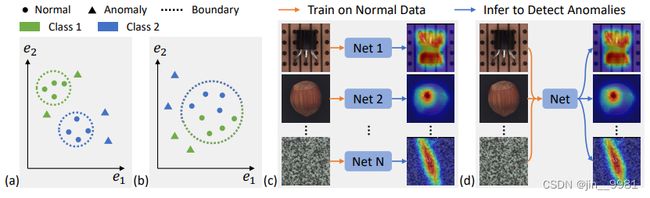
图1说明:
(a)图是已经存在的方法,图片中有两种图片类型,分别是青色和蓝色,需要两个边界,才能区分两种类型图片的缺陷
(b)图是该论文提出的方法,用一个边界就能区分所有类别图片
(c)图说明在以前的方法里,解决多类型图片缺陷的方法,一种缺陷类型使用一个模型,多个类型用多个模型识别, one-class-one-model
(d)图是该论文的重点,用一个统一的模型识别所有缺陷,a unified framework
四、摘要
1、现有方法存在的问题
已有的重构方法存在 “identity shortcut” 的问题,即重构的图片和输入图片差不多,像是对输入图片的复制,图片越复杂,这个问题越严重
2、方案
(1)提出了“layer-wise query decoder”(分层查询解码器)
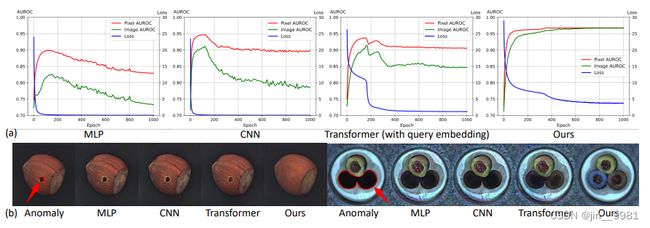
看下文图2的(a)图,MLP和CNN的曲线逐渐上升,突然下降,Transformer也有下降,但下降幅度要小些。曲线下降主要还是上文提到的“identity shortcut”问题。Ours方法就基本不存在曲线下降问题。
(2)采用了“neighbor masked attention”模块(邻居掩码注意力)
特征不跟自己相关,也不跟邻居相关,避免了information leak。
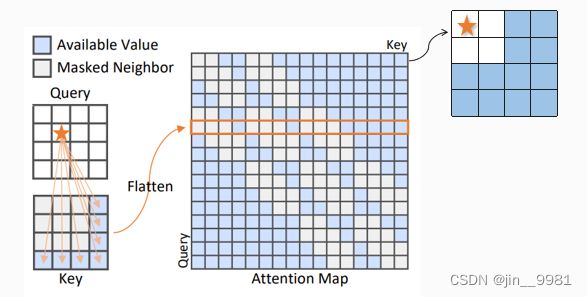
请看图3,Query是4x4,与Key做Attention操作时,相邻的值进行mask,将注意力图Attention Map展开。
话外题:联想常见的Transformer结构,Mask主要有两种作用。第一种是 padding mask ,在encoder和decoder中使用,保证输入长度的一致性;另外一种是 Sequence mask ,在decoder中使用,掩盖当前词后面出现的词。这么一对比就看出作者的mask改动了什么。
(3)“feature jittering strategy”(特征抖动策略)
受Bengio的启发,提出了一个“feature jittering strategy”(特征抖动策略),在有噪声的情况下也能恢复源信息
3、效果
用UniAD模型在15个类别的数据集MVTec-AD上做实验,AUROC分别从88.1%提升到 96.5%,从 89.5%提升到96.8%
五、作者的实验
Normal正常图片;Anomaly异常图片;Recon重构图;GT标注的mask图;Pred是Anomaly和Recon差异图,对缺陷进行定位,颜色越深,表示缺陷的概率越大。效果看起来,so nice

六、如何训练自己的数据
图6是我在自己的数据上做的训练,数据特点是:缺陷图片少、缺陷小,效果还是可以的

1、数据准备
- 进入./data/创建新文件夹/ (可参考./data/MVTec-AD/)
- 创建train.json、test.json文件,格式如下:
{"filename": "000_00_00/train/good/bad_02_0419_Image_20230419104815488_0_0_1280_1280.png", "label": 0, "label_name": "good", "clsname": "000_00_00"}{"filename": "000_02_01/train/good/good_06_0421_Image_20230420180152737_922_563_2202_1843.png", "label": 0, "label_name": "good", "clsname": "000_02_01"}...
字段说明:
filename:图片路径
label:标签(0无缺陷、1缺陷)
label_name:标签名称(good无缺陷、bad缺陷)
clsname:图片类型名称
2、修改配置文件
- 进入cd ./experiments/创建新文件夹/ (具体可参考cd ./experiments/MVTec-AD/,将MVTec-AD的文件复制到自己文件夹)
- 修改config.yaml,如图7
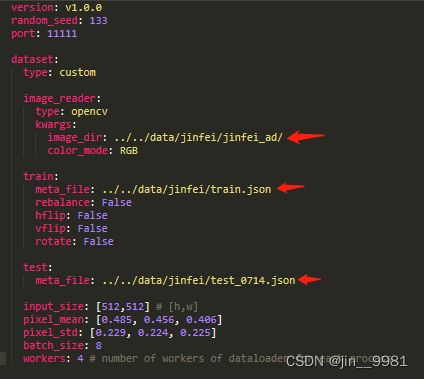
修改说明:
image_dir:训练图片路径
meta_file:训练和测试的json文件
3、代码优化修改
预训练模型提取特征时,卷积采用zero-padding会导致边界引入新信息,造成误检。文献提出使用reflection_padding可降低边界误检,在github代码中还未修改,需要手动修改。
代码路径:./models/efficientnet/utils.py
原代码:
self.static_padding = nn.ZeroPad2d(
(pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2)
)
修改为:
self.static_padding = nn.ReflectionPad2d(
(pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2)
)
4、模型训练与测试
- 模型训练:
1. cd ./experiments/自己的文件夹/
2. sh train_torch.sh #NUM_GPUS #GPU_IDS
例子:sh train_torch.sh 1 0(#NUM_GPUS:gpu个数,#GPU_IDS:gpu编号) - 模型测试 :
sh eval_torch.sh #NUM_GPUS #GPU_IDS
七、结束
如果文章对你有所帮助,请记得点赞收藏哦,手动笔芯❤️❤️❤️