卷积神经网络实现好莱坞明星识别 - P6
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:Pytorch实战 | 第P6周:好莱坞明星识别
- 原作者:K同学啊 | 接辅导、项目定制
- 文章来源:K同学的学习圈子
目录
- 环境
- 步骤
-
- 环境设置
-
- 包引用
- 定义一个全局的设备对象
- 数据准备
-
- 定义数据保存的目录
- 遍历出图片列表
- 随机选择几个图片打印一下大小
- 随机选择20个图片展示一下
- 创建数据预处理器
- 提取数据集中的分类
- 划分训练集和验证集
- 分批
- 模型设计
- 模型训练
-
- 编写训练函数
- 编写评估函数
- 创建损失函数和优化器
- 开始训练
- 训练过程曲线
- 模型效果展示
-
- 读取最佳模型
- 预测函数
- 预测
- 总结与心得体会
环境
- 系统: Linux
- 语言: Python3.8.10
- 深度学习框架: Pytorch2.0.0+cu118
- 显卡:A5000 24G(VGG模型对显存的要求有点大,8G无法运行)
步骤
环境设置
包引用
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, random_split
from torchvision import datsets, transforms
import pathlib, random, copy
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
from torchinfo import summary
定义一个全局的设备对象
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
数据准备
定义数据保存的目录
data_path = 'hollywood_celebrity'
遍历出图片列表
data_lib = pathlib.Path(data_path)
image_list = list(data_lib.glob('*/*'))
随机选择几个图片打印一下大小
for _ in range(5):
image_path = random.choice(image_list)
print(np.array(Image.open(image_path)).shape)

474对于模型来说太大了,这说明我们要缩放一下
随机选择20个图片展示一下
plt.figure(figsize=(20,4))
for i in range(20):
plt.subplot(2, 10, i+1)
plt.axis('off')
image_path = random.choice(image_list)
plt.imshow(Image.open(str(image_path)))
plt.title(image_path.parts[-2])

创建数据预处理器
target_with = 224
target_height = 224
transform = transforms.Compose([
transforms.Resize([target_width, target_height]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
) # 归一化非常有用,缩小了输入的数据范围
])
dataset = datasets.ImageFolder(data_path, transform=transform)
提取数据集中的分类
class_names = [k for k in dataset.class_to_idx]
print(class_names)

划分训练集和验证集
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train_dataset, test_dataset = random_split(dataset, [train_size, test_size])
分批
batch_size = 32
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
模型设计
手动创建一个带有BatchNorm的Vgg16网络,将全连接层的规模减少了一下。
class Network(nn.Module):
def __init__(self, num_classes):
super().__init__()
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 64, 3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Conv2d(128, 128, 3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.Conv2d(512, 512, 3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.adaptivepool = nn.AdaptiveAvgPool2d(7)
# 这里原始的VGG-16的全连接层每一个隐藏层的神经元都是4096个
self.classifier = nn.Sequential(
nn.Linear(7*7*512, 1024),
nn.Dropout(0.5),
nn.ReLU(),
nn.Linear(1024, 256),
nn.Dropout(0.5),
nn.ReLU(),
nn.Linear(256, num_classes)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = self.adaptivepool(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model = Network(len(class_names)).to(device)
summary(model, input_size=(32, 3, target_width, target_height))

模型训练
编写训练函数
def train(train_loader, model, loss_fn, optimizer):
size = len(train_loader.dataset)
num_batches = len(train_loader)
train_loss, train_acc = 0, 0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1)==y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_loss, train_acc
编写评估函数
def test(test_loader, model, loss_fn):
size = len(test_loader.dataset)
num_batches = len(test_loader)
test_loss, test_acc = 0, 0
for x, y in test_loader:
x, y = x.to(device), y.to(device)
pred = model(x)
loss = loss_fn(pred, y)
test_loss += loss.item()
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
test_acc /= size
return test_loss, test_acc
创建损失函数和优化器
optimizer = optim.Adam(model.parameters(), lr=1e-4) # 初始学习率设计为1e-4
loss_fn = nn.CrossEntropyLoss() # 标准的分类任务,使用交叉熵损失
scheduler = optim.lr_scheduler.LambdaLR(optimizer=optimizer, lr_lambda=lambda epoch: 0.92**(epoch//2)) # 应用学习率衰减
epochs = 50 # 训练50个epoch
best_model_path = 'p6_best_model.pth' # 最佳模型权重的保存位置
开始训练
train_loss, train_acc = [], []
test_loss, test_acc = [], []
best_acc = 0
for epoch in range(epochs):
model.train()
epoch_train_loss, epoch_train_acc = train(train_loader, model, loss_fn, optimizer)
scheduler.step()
model.eval()
with torch.no_grad():
epoch_test_loss, epoch_test_acc = test(test_loader, model, loss_fn)
train_loss.append(epoch_train_loss)
train_acc.append(epoch_train_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
if best_acc < epoch_test_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
print(f"Epoch: {epoch+1}, TrainLoss: {epoch_train_loss:.3f}, TrainAcc: {epoch_train_acc*100:.1f}, TestLoss: {epoch_test_loss:.3f}, TestAcc: {epoch_test_acc*100:.1f}, Lr:{lr:.2E}")
print(f'Training Finished, Best Acc: {best_acc*100:.1f}')
print(f'Saving best model to {best_model_path}')
torch.save(best_model.state_dict(), best_model_path)
print('Done')
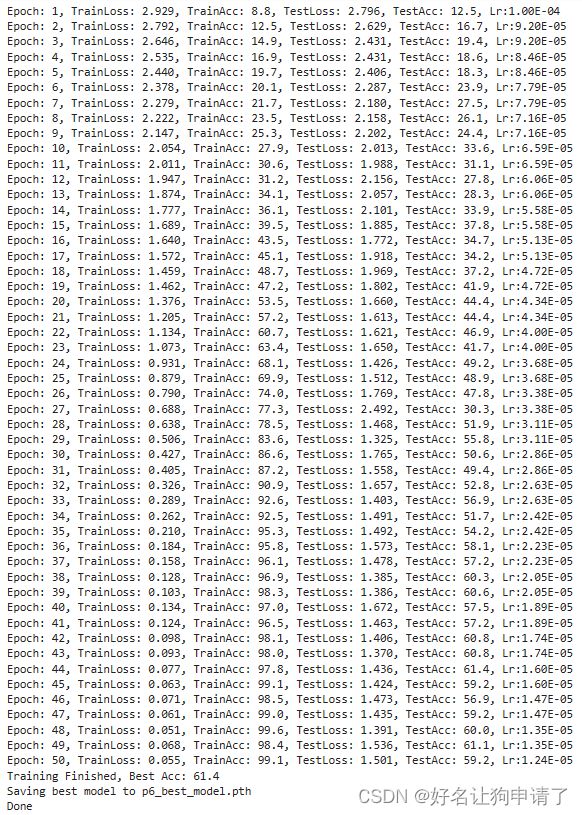
训练完成后,最佳的正确率是61.4%
训练过程曲线
epoch_ranges = range(epochs)
plt.figure(figsize=(16,4))
plt.subplot(1, 2, 1)
plt.plot(epoch_ranges, train_loss, label='train loss')
plt.plot(epoch_ranges, test_loss, label='validation loss')
plt.legend(loc='upper right')
plt.title('Loss')
plt.subplot(1,2,2)
plt.plot(epoch_ranges, train_acc, label='train accuracy')
plt.plot(epoch_ranges, test_acc, label='validation accuracy')
plt.legend(loc='lower right')
plt.title('Accuracy')

通过曲线可以发现,当训练集上的正确率接近100%时,验证集上的正确率也逐渐平缓,因为反向传播已经无法再训练集上改进模型了。这时间要想再提升模型的正确率,只能增大数据集或者添加其它的促进模型泛化的机制。
模型效果展示
读取最佳模型
model.load_state_dict(torch.load(best_model_path))
model.to(device)
预测函数
def predict(model, img_path, label):
image = Image.open(img_path) # 读取图像
image = transform(image) # 应用相同的预处理
image.unsqueeze(0).to(device) # 构造成只有一条数据的批次,并复制到和模型相同的设备上
model.eval()
with torch.no_grad():
pred = model(image) # 执行向前传播
pred_label = class_names[pred.argmax(1)]
# 使用matplot打印一下
plt.figure(figsize=(5,5))
plt.axis('off')
plt.imshow(Image.open(img_path))
plt.title(f"Real Label: {label}, Predict Label: {pred_label}")
预测
由于我没有其它的测试数据,我就在数据集中随机抽取了一张图像,这样做理论上是不能展示模型的泛化能力的。如果抽到训练集中的数据(概率很大),当前的模型基本不会输出错误的结果
random_image = random.choice(image_list)
predict(model, str(random_image), random_image.parts[-2])

这里给出了一个错误的结果,把狼叔识别成了钢铁侠哈哈。不过这张图确实有点像,让我来直接识别我都有可能识别错。
总结与心得体会
- 首先是1:1复刻了一下VGG16网络模型,然后发现在没有预训练的情况下,效果并不是很好。猜测是因为数据量的原因,模型没有很好的学到识别一个人的一些关键特征。
- 其次是在没有增加BatchNorm模块和归一化时,模型完全无法训练。猜测是因为一开始随机初始化的模型权重距离最优解较远,有时间调大一下学习率尝试一下
- 由于当前任务还算一个比较简单的图像分类任务,在模型因为数据量的原因没有很好的泛化时,就考虑能不能通过缩小模型来减少过拟合,于是首先在全连接层应用了这种思想,将全连接层隐藏层神经元减少后,模型的正确率确实有些改善。还没有开始动前面的卷积层,就已经满足了目标。