Playwright + Python爬虫
Python + Playwright爬虫
之前系统的学习过selenium爬虫的框架,其实对于绝大多数情况下基本上已经足够用了。但是最近发现了又一款爬虫神器Playwright,为什么说是神器,总的来说有以下特点:
- 速度快
- 安装、使用便利
- 可远程调试
- 支持有头和无头
- 支持调用本地浏览器调试
- 很方便监听网络资源请求
- 支持同步和异步
- 支持多种语言、java、python、nodejs、c#等等
- 支持主流内核的浏览器、chromiun、firfox、webkit
- 自动录制生成代码
以上是我亲身体会之后自己总结的,可不是去网上扒拉的。废话不多说,让我们一起感受playwright的强大吧!
一、Playwright的安装
其实就是一个python的一个类库而已,所以使用pip install playwright命令安装即可。
二、安装浏览器及其驱动
安装Playwright后,可以使用playwright install命令,会自动安装chromium、firefox、webkit等三款浏览器以及对应的驱动包。当然这个过程比较漫长,因为安装包比较大,后面会讲如何控制本地浏览器爬虫,所以这一步也可以选择跳过。
另外,如果在公司使用代理的情况下,使用以上命令可能无法安装。这种情况下,可以选择使用脚手架npm install playwright --proxy=xxx.xxx.xxx.xx:xx 这种方式去变相的安装浏览器。亲测~安装完了之后, python也是可以直接使用的。
三、Playwright的使用
首先,贴一下官网API的地址:https://playwright.dev/python/docs/intro。
官网已经讲得特别清楚了,而且有很多的实例,这里我就以我遇到的实际问题跟大家进行一个分享。
调用本地浏览器调试
这种方式的好处在于,你完全可以把浏览器放到你的项目下,这样在其他机器上可以很好的兼容,不用你额外去执行命令安装浏览器,修改代码中的路径。
# 指定缓存目录
user_data_dir = "chromium-1005/chrome-win/user data"
# 指定可执行文件路径
executable_path = "chromium-1005/chrome-win/chrome.exe"
browser = playwright.chromium.launch_persistent_context(
user_data_dir=user_data_dir,
executable_path=executable_path,
accept_downloads=True,
headless=True, # 控制无头或有头
bypass_csp=True,
slow_mo=10,
args=['--disable-blink-features=AutomationControlled'],# 禁用正在自动化控制提示
)
page = browser.new_page()
page.goto("https://www.baidu.com")
page.wait_for_load_state(state="networkidle") # 等待一段时间内再无其它请求,相当于等画面完全加载
控制已打开的浏览器
这种方式主要是因为通过playwright打开的浏览器在执行完任务后会自动关闭,为了减少浏览器的开销,节省时间,可已选择使用命令打开浏览器配合远程调试模式进行处理。
command = "chrome/chrome --remote-debugging-port=9001"
if self.headless:
# 以无头模式启动浏览器
command = "chrome/chrome --remote-debugging-port=9001 --headless"
subprocess.Popen(command)
print("浏览器已启动!等待进程创建...")
proccess_pid = ""
while True:
time.sleep(1)
with os.popen(f"netstat -ano | findstr 9001") as r:
text = r.read()
if len(text) > 0:
pid_info = text.split("\n")[0].split(" ")
# 获取进程ID
proccess_pid = pid_info[len(pid_info) - 1]
break
playwright = sync_playwright().start()
browser = playwright.chromium.connect_over_cdp("http://localhost:9001")
page = browser.new_page()
page.goto("https://www.baidu.com")
page.wait_for_load_state(state="networkidle")
# 关闭进程
os.popen(f"taskkill /im {proccess_pid } /F")
这种方式其实已经很好了,但是存在一个问题,当已经有浏览器被开启时,命令打开浏览器会从缓存加载,不会监听到远程端口, 必须要关掉所有的浏览器之后,才能正常进行控制。 这个问题, 如果有谁有好的方法去解决,就是一个非常完美的方案。欢迎大家探讨!
监听网络资源请求
这是一个我认为非常强大的功能,早在学selenium的时候,我曾经探讨过这个问题,使用selenium要实现这个东西,当时各种百度,最终有了处理方案,但始终还不是特别满意。
但是playwright把这一点简化到了极致,让我不禁被为它折服。
def on_response(self, response):
if "https://fanyi.baidu.com/v2transapi" in response.url:
result = response.json()
print(result)
user_data_dir = "chromium-1005/chrome-win/user data"
executable_path = "chromium-1005/chrome-win/chrome.exe"
browser = playwright.chromium.launch_persistent_context(
user_data_dir=user_data_dir,
executable_path=executable_path,
accept_downloads=True,
headless=True,
bypass_csp=True,
slow_mo=10,
args=['--disable-blink-features=AutomationControlled'],
# 设置代理
proxy=ProxySettings(server="http://xxx.xxx.xxx.xxx:xxxx"),
)
page = browser.new_page()
# 监听响应事件
page.on("response", self.on_response)
page.goto("https://fanyi.baidu.com/#zh/jp/你好")
page.wait_for_load_state(state="networkidle")

以上是我通过这玩意儿抓取百度翻译的简单代码。但是需要特别注意一点,在需要代理的情况下,使用无头浏览器必须设置代理,像这样proxy=ProxySettings(server="http://xxx.xxx.xxx.xxx:xxxx"),,否则你会看到以下错误:
chromium浏览器:

webkit浏览器
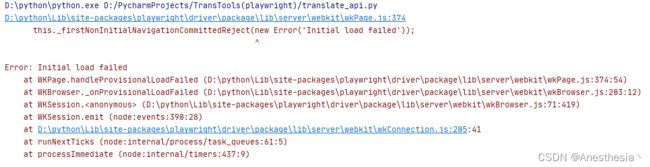
但firefox却没有发现问题,所以你也可以使用火狐浏览器去避免这一问题。
禁止某些资源加载
很多情况下,我们在抓取的时候并不是所有的请求都需要,但是又不得不等待画面加载完成再进行抓取。那么这种时候,我们可以使用router事件过滤我们不需要的请求,比如图片和css样式。
def on_response(self, response):
if "https://fanyi.baidu.com/v2transapi" in response.url:
result = response.json()
print(result)
# 取消请求
def cancel_request(self, route, request):
route.abort()
user_data_dir = "chromium-1005/chrome-win/user data"
executable_path = "chromium-1005/chrome-win/chrome.exe"
browser = playwright.chromium.launch_persistent_context(
user_data_dir=user_data_dir,
executable_path=executable_path,
accept_downloads=True,
headless=True,
bypass_csp=True,
slow_mo=10,
args=['--disable-blink-features=AutomationControlled'],
# 设置代理
proxy=ProxySettings(server="http://xxx.xxx.xxx.xxx:xxxx"),
)
page = browser.new_page()
# 正则匹配监听图片和css的请求
page.route(re.compile(r"(\.png)|(\.jpg)|(\.css)"), self.cancel_request)
# 监听响应事件
page.on("response", self.on_response)
page.goto("https://fanyi.baidu.com/#zh/jp/你好")
page.wait_for_load_state(state="networkidle")
最终去掉js和图片的画面:

加上禁止资源处理前,需要12s左右,加上后缩短都3s左右,极大的提升了抓取的效率。另外,如果某些js明确不会影响我们要抓取的数据,也可以做进一步的优化。
模拟手机端
很多情况下我们需要模拟手机端的访问,playwright也能轻易做到。
# 定义手机型号, 可以通过浏览器的开发者查看
phone_name="iPhone 12 Pro Max"
playwright = sync_playwright().start()
phone_obj = playwright.devices[phone_name]
self.browser = self.playwright.chromium.launch_persistent_context(
**phone_obj,
user_data_dir=user_dir,
executable_path=brows_executable_path,
accept_downloads=True,
headless=headless,
bypass_csp=True,
slow_mo=10,
args=['--disable-blink-features=AutomationControlled']
)
// 支持的手机型号列表
Blackberry PlayBook
Blackberry PlayBook landscape
BlackBerry Z30
BlackBerry Z30 landscape
Galaxy Note 3
Galaxy Note 3 landscape
Galaxy Note II
Galaxy Note II landscape
Galaxy S III
Galaxy S III landscape
Galaxy S5
Galaxy S5 landscape
Galaxy S8
Galaxy S8 landscape
Galaxy S9+
Galaxy S9+ landscape
Galaxy Tab S4
Galaxy Tab S4 landscape
iPad (gen 6)
iPad (gen 6) landscape
iPad (gen 7)
iPad (gen 7) landscape
iPad Mini
iPad Mini landscape
iPad Pro 11
iPad Pro 11 landscape
iPhone 6
iPhone 6 landscape
iPhone 6 Plus
iPhone 6 Plus landscape
iPhone 7
iPhone 7 landscape
iPhone 7 Plus
iPhone 7 Plus landscape
iPhone 8
iPhone 8 landscape
iPhone 8 Plus
iPhone 8 Plus landscape
iPhone SE
iPhone SE landscape
iPhone X
iPhone X landscape
iPhone XR
iPhone XR landscape
iPhone 11
iPhone 11 landscape
iPhone 11 Pro
iPhone 11 Pro landscape
iPhone 11 Pro Max
iPhone 11 Pro Max landscape
iPhone 12
iPhone 12 landscape
iPhone 12 Pro
iPhone 12 Pro landscape
iPhone 12 Pro Max
iPhone 12 Pro Max landscape
iPhone 12 Mini
iPhone 12 Mini landscape
iPhone 13
iPhone 13 landscape
iPhone 13 Pro
iPhone 13 Pro landscape
iPhone 13 Pro Max
iPhone 13 Pro Max landscape
iPhone 13 Mini
iPhone 13 Mini landscape
JioPhone 2
JioPhone 2 landscape
Kindle Fire HDX
Kindle Fire HDX landscape
LG Optimus L70
LG Optimus L70 landscape
Microsoft Lumia 550
Microsoft Lumia 550 landscape
Microsoft Lumia 950
Microsoft Lumia 950 landscape
Nexus 10
Nexus 10 landscape
Nexus 4
Nexus 4 landscape
Nexus 5
Nexus 5 landscape
Nexus 5X
Nexus 5X landscape
Nexus 6
Nexus 6 landscape
Nexus 6P
Nexus 6P landscape
Nexus 7
Nexus 7 landscape
Nokia Lumia 520
Nokia Lumia 520 landscape
Nokia N9
Nokia N9 landscape
Pixel 2
Pixel 2 landscape
Pixel 2 XL
Pixel 2 XL landscape
Pixel 3
Pixel 3 landscape
Pixel 4
Pixel 4 landscape
Pixel 4a (5G)
Pixel 4a (5G) landscape
Pixel 5
Pixel 5 landscape
Moto G4
Moto G4 landscape
Desktop Chrome HiDPI
Desktop Edge HiDPI
Desktop Firefox HiDPI
Desktop Safari
Desktop Chrome
Desktop Edge
Desktop Firefox
等待某个资源请求出现或完成
有时我们只需要等待某一个请求出现或者完成就可以达到我们的目的,这种情况下,没必要等页面完全加载,这时候可以使用以下监听事件:
- page.expect_request(url_or_predicate, **kwargs) // 期待出现某个请求时
- page.expect_request_finished(url_or_predicate, **kwargs) // 期待某个请求完了时使用
- page.expect_response(url_or_predicate, **kwargs) // 期待出现某个响应时使用
这里只举一个例子,更多请参考官方文档,https://playwright.dev/python/docs/api/class-page#page-wait-for-request:
page.goto("https://www.baidu.com")
# 当出现请求地址地址包含www.baidu.com且响应状态为200时等待结束
page.expect_response(lambda response: "www.baidu.com" in response.url and response.status == 200)
以上就是本次探究的一个总结,至于其它的浏览器操作自动化部分,不在这里敖述,网上一搜一大堆。
这里推荐这篇博客:https://blog.csdn.net/zjkpy_5/article/details/122418811。
还有一个自动生成代码,类似于excel的宏录制的功能,这里不做探究,工具只是一个辅助,多动手去发现其中的规律才能巩固你的基础。
好了,愿看到的小伙伴不会迷路。欢迎大家留言探讨!