Source Map知多少?Golang手写SourceMap转换过程
文章目录
-
-
- 一、问题背景
- 二、Source Map 简介
-
- 基本格式
- 应用场景
- 三、Source Map 的工作原理
- 四、Source Map 的转换过程
-
- 代码示例
- 总结
-
本文从原理的角度入手对 Source Map 进行了较为深入的分析,并从业务需要的角度出发,手动编写根据 Source Map 映射编码前后代码行数的功能,示例语言为 Golang
一、问题背景
由于线上实际运行的生产代码是经过编译的转换代码,笔者需要对生产代码和源代码的日志行进行映射,帮助开发者更方便快捷地定位问题
在JS中一般通过 Source Map 进行生产代码和源代码的映射,抱着知其所以然的目的,笔者对 Source Map 的前世今生进行了了解,并一步步理解了 Source Map 的转换原理
二、Source Map 简介
随着 JavaScript 代码的日益复杂,越来越多的源码(包括函数库、框架等)需要经过转换/打包才能投入生产,一般而言转换的目的分为以下三种:
(1)压缩代码,降低存储和传输成本
(2)多文件合并,理由同上
(3)其他语言编译为 JavaScript
转换固然解决了以上问题,但由于线上代码是转换后的代码,一旦程序报错时调用栈中的信息也会是转换后的代码,增加了需要 debug 的开发者的负担
为了能够还原经过转换的代码,Source Map 应运而生

基本格式
Source Map 是一个存储代码转换前后位置对应关系的 JSON 格式文件,调试工具可以通过 Map 文件还原出转换后代码在转换前的行列信息,其基本格式如下:
{
version : 3,
file: "output.js",
sourceRoot : "",
sources: ["input_a.js", "input_b.js"],
names: ["src", "maps", "are", "fun"],
mappings: "AAgBC,SAAQ,CAAEA",
sourcesContent: []
}
-
version: Source Map 版本
-
file:输出文件名
-
sourceRoot:输入文件所在目录
-
sources:输入文件名,可以有多个
-
names:转换前的变量&属性名集合
-
mappings:经过 Base64 VLQ 编码的字符串,记录位置映射关系
-
sourcesContent:转换前文件的内容
其中与转换过程比较相关的是 mappings 字段,在第三小节会重点解释
应用场景
一般可以使用前端打包工具如 Webpack 等生成 Source Map 文件,如使用 Webpack 可以通过在 webpack.config.js 中加入如下代码来生成:

编译后除了源码文件外会同时生成 Map 文件:

开发者拿到 Source Map 文件后一般不会手动处理,但浏览器得到 Source Map 文件后就可以对文件进行转换了,以 Chrome 为例,打开如下配置后浏览器会自动下载 Map 文件并对文件进行转换,方便开发者进行排错

即便调试工具帮忙完成了转换工作,但了解 Source Map 的工作原理也可以帮助我们更好的 debug
三、Source Map 的工作原理
Source Map 的目的是对转换前后的代码进行映射,那么流程可以抽象为一次文本转换输出
“feel the force” ⇒ 转换器 ⇒ “the force feel”
Map 文件要保存的核心是输入字符串的 n 行 m 列,对应于输出字符串的 n1 行 m1 列,如首字符 f 的映射关系为 f(0,0)=>(0,10)
通过这种简单的对应关系确实可以还原出源文件,但映射表中要存储的还包括输入文件名(因为不止一个源文件)等信息,会导致 Map 文件占用很大,也会损失传输性能
为节约存储空间,Source Map对于映射关系进行了编码上的优化,包括不以字符而以单词作为最小单位(单词集合存储在 Map 文件的 names 字段里)、以 index 取代源文件名(源文件序列放在 Map 文件的 srouces字段里)、以相对位置记录行数等
因为篇幅原因,更加详细的编码优化流程可以参考这篇文章
下面以一段转换前和一段转换后的代码实例讲解 Source Map 是如何进行映射的
// 转换前
function component() {
const element = document.createElement('div');
var x = 1;
console.log("x: ", x);
return element;
}
document.body.appendChild(component());
// 转换后
document.body.appendChild(function(){const e=document.createElement("div");return console.log("x: ",1),e}());
//# sourceMappingURL=main.js.map
两者对应的 Map 文件如下
{
"version":3,
"file":"main.js",
"mappings":"AAOEA,SAASC,KAAKC,YAPhB,WACI,MAAMC,EAAUH,SAASI,cAAc,OAGvC,OADAC,QAAQC,IAAI,MADJ,GAEDH,CACT,CAE0BI",
"sources":["webpack://webpack-demo/./src/index.js"],
"sourcesContent":["function component() {\n const element = document.createElement('div');\n var x = 1;\n console.log(\"x: \", x);\n return element;\n }\n \n document.body.appendChild(component());"],
"names":["document","body","appendChild","element","createElement","console","log","component"],
"sourceRoot":""
}
Map 文件中最重要的 mappings 字段,看似是一串无意义的字符,实际上存储了两个文件中的所有映射关系,其含义如下
首先,mappings 字段分为三层
第一层是行对应,以分号(; )表示,每个分号对应转换后源码的一行,第一个分号前的内容对应第一行
第二层是位置对应,以逗号(, )表示,每个逗号对应转换后源码的一个位置
第三层是位置转换,以 Base64 VLQ 编码表示,代表该位置对应的转换前的源码位
按照如上规则,以下字符串里没有出现分号(,是因为转换后的源码只有一行,而逗号(,) 则将转换后源码分割为 n 个位置
AAOEA,SAASC,KAAKC,YAPhB,WACI,MAAMC,EAAUH,SAASI,cAAc,OAGvC,OADAC,QAAQC,IAAI,MADJ,GAEDH,CACT,CAE0BI
接下来的部分比较难理解,在经过逗号分割以后,每个位置都由至多五个字符(五位不一定都有)组成,每个位置字符的含义如下:
第一位,表示这个位置在(转换后的代码的)的第几列
第二位,表示这个位置属于 sources 属性中的哪一个文件
第三位,表示这个位置属于转换前代码的第几行
第四位,表示这个位置属于转换前代码的第几列
第五位,表示这个位置属于 names 属性中的哪一个变量
以第一组字符 “AAOEA” 为例,第一个 A 表示这个位置在转换后代码的第 A 列,这样可以确定是哪一个单词;第二个 A 代表这个位置在 sources 数组中的 index;第三个 O 代表这个位置属于转换前代码的第 O 行;第四个 E 代表这个位置属于转换前代码的第 E 列,第五个 A 代表在 names 数组中的 index
这五个字符实际都代表着一个数字,将字符映射为数字需要再经过一层 Base64 VLQ 编码的转换(编码原理可以参考这篇介绍),下一小节的代码中也会有所涉及
四、Source Map 的转换过程
如果从日常使用的角度出发,了解到工作原理这一层已经可以覆盖大多数场景了,但实际写下这段代码时有诸多在Source Map 的科普文中未曾点明和存在误解的点
代码示例
转换代码可以大致分为两个步骤,其一是处理行列的对应关系,其二是对 Base64 VLQ 编码的转换
第一步,Base64 VLQ 编码规则这篇文章有详细的解释,总结下来从 0-63 的数字分别可以用一个字符编码
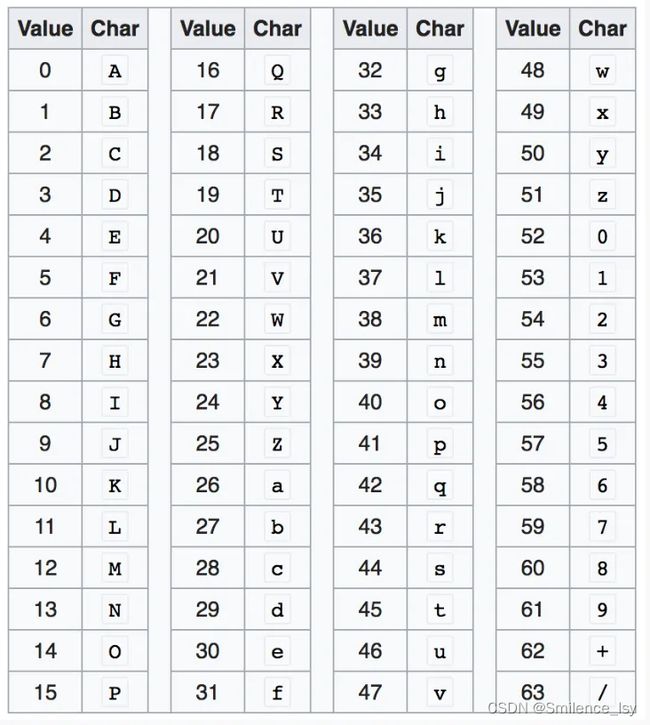
初始化时可以将字符与数字的对应关系存入一个 map,实现方法如下
// 代码仅做逻辑展示用途
func CreateBase64Digit() {
BASE64_DIGITS := []rune{}
charCode := []rune("A")[0]
for i := 0; i < 26; i++ {
BASE64_DIGITS = append(BASE64_DIGITS, rune(int(charCode)+i))
}
charCode = []rune("a")[0]
for i := 0; i < 26; i++ {
BASE64_DIGITS = append(BASE64_DIGITS, rune(int(charCode)+i))
}
charCode = []rune("0")[0]
for i := 0; i < 10; i++ {
BASE64_DIGITS = append(BASE64_DIGITS, rune(int(charCode)+i))
}
BASE64_DIGITS = append(BASE64_DIGITS, rune('+'))
BASE64_DIGITS = append(BASE64_DIGITS, rune('/'))
BASE64_DIGITS_MAP = make(map[rune]int)
for i := 0; i < len(BASE64_DIGITS); i++ {
BASE64_DIGITS_MAP[BASE64_DIGITS[i]] = i
}
}
第二步是处理行数对应关系,代码的输入是转换后的行数,输出是转换前对应的行数
注:这里处理的是一种特殊情况,即输入输出都仅有一个文件,且不考虑列数
const (
VLQ_BASE_SHIFT = 5
VLQ_BASE = 1 << VLQ_BASE_SHIFT
VLQ_BASE_MASK = VLQ_BASE - 1
VLQ_CONTINUATION_BIT = VLQ_BASE
)
result := [][][]int{}
var segmentsInLine [][]int
var numbersInSegment []int
var shift = 0
var continuation int
if patternList := strings.Split(mapping, ";"); len(patternList) >= line { // 分割行
for j := 0; j < len(patternList); j++ {
segmentsInLine = [][]int{}
for _, segment := range strings.Split(patternList[j], ",") { // 分割列
resultValue := 0
numbersInSegment = []int{}
for _, c := range []rune(segment) {
if digit, ok := BASE64_DIGITS_MAP[c]; ok { // 处理Base64-VLQ编码, 转换为数字
continuation = digit & VLQ_CONTINUATION_BIT
digit &= VLQ_BASE_MASK
resultValue += digit << shift
shift += VLQ_BASE_SHIFT
if continuation == 0 {
negate := (resultValue & 1) == 1
resultValue >>= 1
if negate {
numbersInSegment = append(numbersInSegment, -resultValue)
} else {
numbersInSegment = append(numbersInSegment, resultValue)
}
resultValue = 0
shift = 0
}
} else {
return -1
}
}
segmentsInLine = append(segmentsInLine, numbersInSegment)
}
result = append(result, segmentsInLine)
}
// 根据转换结果确定实际代码位置
beforeLine :=
for t := 0; t < line; t++ { // 遍历所有行直到指定行数
if len(result[t]) > 0 {
for l := range result[t] {
if len(result[t][l]) > 2 { // 找到第三个字符(代表行数),并进行累加
beforeLine += result[t][l][2]
}
}
}
}
}
这段代码里需要特殊注意的地方是下面这段:
beforeLine := 0
for t := 0; t < line; t++ { // 遍历所有行直到指定行数
if len(result[t]) > 0 {
for l := range result[t] {
if len(result[t][l]) > 2 { // 找到第三个字符(代表行数),并进行累加
beforeLine += result[t][l][2]
}
}
}
}
result 数组是以行、列、字符的维度存储转后的数字的数组,上述代码的逻辑是,如果想要找到转换后第 n 行代码对应于转换前第几行代码,需要遍历第0行到第n-1行的所有位置,并且累加其行数,才能得到最终的对应行数
这是由于为了缩减表示位数,所有行数都是相对位置,因此需要对前面的行数进行累加,这一点基本没有文章说明,更完整的计算方法可以直接阅读官方的英文文档
总结
Source Map 的作用不仅是方便开发者 debug 代码,在日益复杂的生产环境下,其也可以用来还原原始代码的堆栈信息等,有很广泛的应用场景