Netty源码剖析之HashedWheelTimer时间轮
版本信息:
JDK1.8
Netty-all:4.1.38.Final
时间轮的介绍
我们知道钟表分为很多块,每时钟滴答一次就往前走一个块,而时间轮就是使用这个思想。如下图

上图总共分为8块,每过100ms就往前走一块,然后周而复始。此时,我们能不能在每一块上挂载任务呢,然后每过100ms就执行块上的任务,实现类似于Scheduled延迟调度任务的功能。
下面使用一个案例+画图介绍一下时间轮。
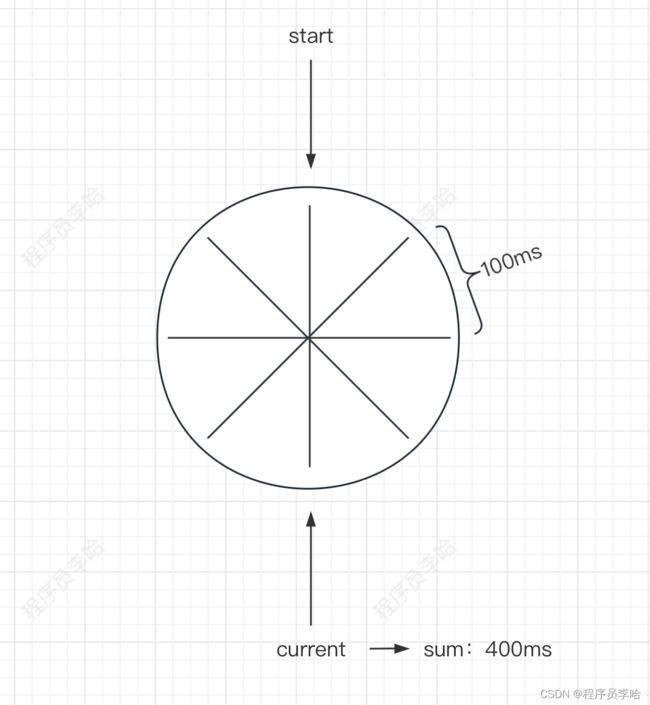
此时,每块的间隔是100ms,时间轮的current指针已经执行了400ms,此时插入一个延迟200ms调度的任务进来。
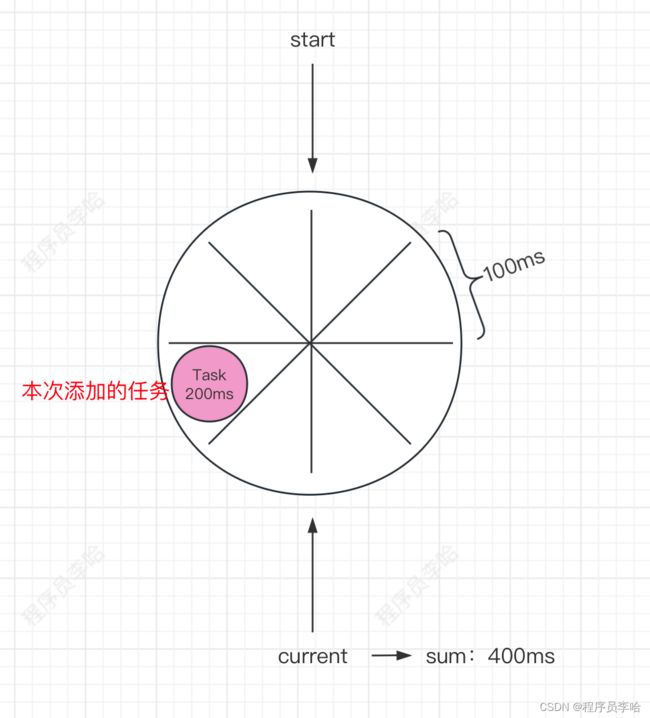
而插入之需要算出时间轮的current指针的时间,然后加上本次调度的时间,就可以直接往哪一块添加任务,所以插入的效率是O1时间复杂度,不过在冲突的情况下需要使用链表链起来。而解决冲突的最好办法就是把块增多减少碰撞(HashMap同样的思想)
如果某个节点发生了碰撞,存在3个任务都在一个块,当current执行到哪一块的时候,就会串行化执行3个任务,如果任务中存在耗时任务,那么其他任务就会延迟执行,超过预期的执行时间,也会影响到整体的current前进,导致整体的时间对不上。所以使用时间轮的任务需要对时延的准确性低,并且尽量保证任务本身精简不携带耗时操作~
时间轮和小顶堆的区别
PriorityQueue优先级队列 https://blog.csdn.net/qq_43799161/article/details/132734047?spm=1001.2014.3001.5502
https://blog.csdn.net/qq_43799161/article/details/132734047?spm=1001.2014.3001.5502
在上篇文章中讲述了PriorityQueue优先级队列,它底层由小顶堆实现(完全二叉树),在插入元素的时候需要向上调整(siftUp),在取出元素的时候需要向下调整(siftDown),调整的过程是非常浪费性能,尤其是数据量过多的时候。
而时间轮通过O1的时间复杂度直接定位在哪一块上,如果有冲突就使用链表把定位在同一块的任务链起来,不需要任何的调整,整体效率比小顶堆高,尤其是数据量大的时候差距就更加的明显~
HashedWheelTimer源码分析
直接从构造方法入手~
/**
* @param threadFactory 线程工厂
* @param tickDuration 间隔时间,默认是100
* @param unit 时间单位,默认是毫秒ms
* @param ticksPerWheel 总块数,默认是512块
* @param leakDetection 是否泄漏检测,默认为true
* @param maxPendingTimeouts 最大任务数,默认为-1,-1代表无限数量。
* */
public HashedWheelTimer(
ThreadFactory threadFactory,
long tickDuration, TimeUnit unit, int ticksPerWheel, boolean leakDetection,
long maxPendingTimeouts) {
// 创建HashedWheelBucket数组。数组大小为ticksPerWheel,默认512快。(会优化成2的指数倍数,因为要hash运算)
wheel = createWheel(ticksPerWheel);
mask = wheel.length - 1; // hash运算掩码
// 把用户传入的间隔单位转换成纳秒。
long duration = unit.toNanos(tickDuration);
// 时间间隔小于默认的最小值(最小值为1毫秒)
if (duration < MILLISECOND_NANOS) {
// 赋值为默认的最小值
this.tickDuration = MILLISECOND_NANOS;
} else {
// 正常赋值
this.tickDuration = duration;
}
// 创建时间轮的工作线程
workerThread = threadFactory.newThread(worker);
// 默认为-1,也即为无限大
// 当然这个值用户可以自行传入。
this.maxPendingTimeouts = maxPendingTimeouts;
}对构造方法做一个总结:
- 创建HashedWheelBucket数组,这个数组就是时间轮的块,默认有512块。所以也尽可能的减少碰撞
- 把用户传入的间隔时间,默认为100ms,转换成纳秒,因为纳秒计算保证了精准性
- 创建时间轮的工作线程,此工作线程的指责是每次的100ms滴答,执行每个块的任务
- 赋值总任务量,默认为-1,也即默认无限多。
构造方法把一切初始化好了,创建了线程,所以需要找到线程在那里开启,线程的执行代码~
既然已经初始化好了,那么就看到创建延迟调度任务的方法,此方法中启动了时间轮工作线程
/**
* @param task 任务
* @param delay 延迟时间
* @param unit 时间单位
* @author liha
*
*/
@Override
public Timeout newTimeout(TimerTask task, long delay, TimeUnit unit) {
// 限流。
long pendingTimeoutsCount = pendingTimeouts.incrementAndGet();
if (maxPendingTimeouts > 0 && pendingTimeoutsCount > maxPendingTimeouts) {
pendingTimeouts.decrementAndGet();
throw new RejectedExecutionException("Number of pending timeouts ("
+ pendingTimeoutsCount + ") is greater than or equal to maximum allowed pending "
+ "timeouts (" + maxPendingTimeouts + ")");
}
// 开启线程。
// 内部使用状态机+unsafe保证只会有一个线程启动
start();
// 当前时间 + 本次延迟调度的时间 - 时间轮开始的时间 = 本次调度的绝对时间。
long deadline = System.nanoTime() + unit.toNanos(delay) - startTime;
// 创建任务,往时间轮的工作线程队列投递
HashedWheelTimeout timeout = new HashedWheelTimeout(this, task, deadline);
timeouts.add(timeout);
return timeout;
}对创建延迟调度任务的方法做一个总结:
- 限流操作,是否达到了用户设置的总任务数的阈值
- 启动线程,内部使用状态机+unsafe保证只会有一个线程启动
- 算出本次调度的绝对时间。而绝对时间是从工作线程启动的时候开始算的,为什么要这么算?因为工作线程启动时钟就开始滴答,也即current指针开始移动。所以我们有必要把这些时间算进去 ,再加上本次延迟调度的时间 ,就等于最终调度的绝对时间。
- 创建出HashedWheelTimeout对象,此对象就是延迟调度任务
- 多线程之间的传输任务肯定是使用队列,所以使用队列将HashedWheelTimeout投递到工作线程中
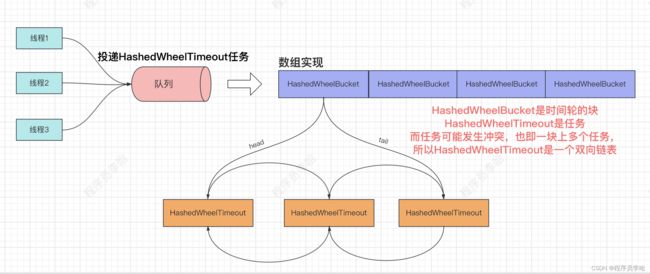
所以,我们接下来看到时间轮工作线程。
// 线程执行点。
@Override
public void run() {
// 当前线程的启动时间
startTime = System.nanoTime();
// 唤醒阻塞在等待此线程启动的线程。
startTimeInitialized.countDown();
do {
// 使用休眠模拟滴答。
final long deadline = waitForNextTick();
if (deadline > 0) {
// 算出本次滴答执行的任务在那个索引位置。
int idx = (int) (tick & mask);
// 处理取消的任务
processCancelledTasks();
// 取出当前滴答索引对应的HashedWheelBucket
HashedWheelBucket bucket =
wheel[idx];
// 从队列中取出其他线程投递的HashedWheelTimeout调度任务。
transferTimeoutsToBuckets();
// 处理当前批次的。
bucket.expireTimeouts(deadline);
// 为下次滴答+1。
tick++;
}
} while (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_STARTED);
// 跳出do while循环代表已经处于stop状态,所以需要做收尾工作。
// 把队列中还没有处理的任务返回给用户自行去处理
for (HashedWheelBucket bucket: wheel) {
bucket.clearTimeouts(unprocessedTimeouts);
}
for (;;) {
HashedWheelTimeout timeout = timeouts.poll();
if (timeout == null) {
break;
}
if (!timeout.isCancelled()) {
unprocessedTimeouts.add(timeout);
}
}
processCancelledTasks();
}- 获取到当前线程启动的时间
- 唤醒等待当前线程启动的线程
- waitForNextTick方法使用休眠模拟时钟滴答
- 算出本次滴答后需要执行的块的索引
- 处理取消的任务
- 通过块的索引拿到HashedWheelBucket
- 从队列中取出其他线程投递的HashedWheelTimeout调度任务。
- 处理当前HashedWheelBucket中的任务
- 为下次滴答+1。
- 当工作线程进入到stop状态后,会把没有执行的任务打包,当用户调用stop方法会拿到这些没处理的任务,交给用户自行处理。
这里我们看到waitForNextTick方法如何使用休眠模拟时钟滴答
private long waitForNextTick() {
// tick是总滴答的次数。
// 滴答间隔 * 总滴答的次数+1 = 本次滴答完后的总滴答时间
long deadline = tickDuration * (tick + 1);
for (;;) {
// 得到工作线程从启动开始总共运行的时间(这是一个相对时间)
final long currentTime = System.nanoTime() - startTime;
/**
* 这里拿本次应该滴答后达到的时间 - 工作线程从启动开始总共运行的时间 = 本次睡眠的时间
* 注意:这里可能已经是负数了,因为执行之前的调度任务需要时间
* + 999999 / 1000000 是为了四舍五入,并且把纳秒转换成毫秒,因为sleep方法需要毫秒
* */
long sleepTimeMs = (deadline - currentTime + 999999) / 1000000;
// 小于0直接返回,代表达到时间了。
if (sleepTimeMs <= 0) {
if (currentTime == Long.MIN_VALUE) {
return -Long.MAX_VALUE;
} else {
return currentTime;
}
}
try {
// 睡眠
Thread.sleep(sleepTimeMs);
} catch (InterruptedException ignored) {
if (WORKER_STATE_UPDATER.get(HashedWheelTimer.this) == WORKER_STATE_SHUTDOWN) {
return Long.MIN_VALUE;
}
}
}
}这里比较简单,就是算出本次滴答后的绝对时间 - 当前工作线程总共执行的时间 = 本次应该休眠的时间,然后去Thread.sleep 睡眠模拟时钟滴答。
我们继续看到transferTimeoutsToBuckets方法是如何接受队列的HashedWheelTimeout调度任务
private void transferTimeoutsToBuckets() {
// 尝试10000次,如果10000次还没有队列来就下一轮再处理,因为我们不能在这里浪费过多的时间影响到精准度
for (int i = 0; i < 100000; i++) {
// 从队列中尝试取出。
HashedWheelTimeout timeout = timeouts.poll();
// timeout.deadline是拿到用户传入的调度时间
// tickDuration 这个是一次滴答的时间。
// 所以这里算出调度需要多少次滴答
long calculated = timeout.deadline / tickDuration;
// 计算出多少轮可以调度。
timeout.remainingRounds = (calculated - tick) / wheel.length;
final long ticks = Math.max(calculated, tick);
// hash运算,得到HashedWheelBucket数组的索引。
int stopIndex = (int) (ticks & mask);
HashedWheelBucket bucket = wheel[stopIndex];
// 添加到HashedWheelBucket,其中使用双向链表,等待被调度。
bucket.addTimeout(timeout);
}
}这里for循环尝试10w次,因为不能尝试太多次,不然会影响到调度的精准度。
每次尝试从队列中获取到调度任务,计算出当前任务需要多少个滴答,最后hash运算添加到对应的HashedWheelBucket中,等待被调度。
在本文的最后看一下,如何调用任务,看到HashedWheelBucket的expireTimeouts方法
public void expireTimeouts(long deadline) {
HashedWheelTimeout timeout = head;
while (timeout != null) {
HashedWheelTimeout next = timeout.next;
// 小于等于0 代表可以被调度了,要不然就-1
if (timeout.remainingRounds <= 0) {
// 要被调度的任务就从链表中移除。
next = remove(timeout);
if (timeout.deadline <= deadline) {
// 执行任务。
timeout.expire();
} else {
// The timeout was placed into a wrong slot. This should never happen.
throw new IllegalStateException(String.format(
"timeout.deadline (%d) > deadline (%d)", timeout.deadline, deadline));
}
} else if (timeout.isCancelled()) {
// 被取消了,所以从队列中移除
next = remove(timeout);
} else {
// 整整大了N个周期,所以-1,等到remainingRounds为0的时候就是需要被调度
timeout.remainingRounds --;
}
timeout = next;
}
}这里就非常的容易了,直接遍历双向链表,串行化的执行HashedWheelTimeout的expire方法,在expire方法中会调用用户传入的业务逻辑