CatBoost vs. LightGBM vs. XGBoost,谁才是最强王者!
提升算法是一类机器学习算法,通过迭代地训练一系列弱分类器(通常是决策树)来构建一个强分类器。在每一轮迭代中,新的分类器被设计为修正前一轮分类器的错误,从而逐步提高整体的分类性能。
尽管神经网络兴起并流行起来,但提升算法仍然相当实用。因为它们在训练数据有限、训练时间短、缺乏参数调优专业知识等的情况下,仍然有良好的表现。
提升算法有AdaBoost、CatBoost、LightGBM、XGBoost等。
本文,将重点关注CatBoost、LightGBM、XGBoost。将包括:
-
结构上的区别;
-
每个算法对分类变量的处理方式;
-
理解参数;
-
在数据集上的实践;
-
每个算法的性能。
由于 XGBoost(通常被称为 GBM Killer)在机器学习领域已经存在了很长时间,并且有很多文章专门介绍它,因此本文将更多地关注 CatBoost 和 LGBM。
1. LightGBM和XGBoost的结构差异
LightGBM使用一种新颖的梯度单边采样(Gradient-based One-Side Sampling,GOSS)技术,在查找分裂值时过滤数据实例,而XGBoost使用预排序算法(pre-sorted algorithm)和基于直方图的算法(Histogram-based algorithm)来计算最佳分裂。
上面的实例指的是观测/样本。
首先,让我们了解一下XGBoost的预排序分裂是如何工作的:
-
对于每个节点,枚举所有特征;
-
对于每个特征,按特征值对实例进行排序;
-
使用线性扫描来根据信息增益(information gain)决定该特征上的最佳分裂;
-
选择所有特征中的最佳分裂解决方案。
简单来说,基于直方图的算法将特征的所有数据点分成离散的箱子,并使用这些箱子来找到直方图的分裂值。虽然在训练速度上比预排序算法高效,后者需要枚举预排序的特征值上的所有可能分裂点,但在速度方面仍然落后于GOSS。
那么,是什么使得GOSS方法高效呢?
在AdaBoost中,样本权重可以作为样本重要性的良好指标。然而,在梯度提升决策树(GBDT)中,没有原生的样本权重,因此无法直接应用于AdaBoost提出的采样方法。这就引入了基于梯度的采样方法。
梯度代表损失函数切线的斜率,因此在某种意义上,如果数据点的梯度较大,这些点对于找到最佳分裂点是重要的,因为它们具有更高的误差。
GOSS保留所有具有较大梯度的实例,并对具有较小梯度的实例进行随机采样。例如,假设我有50万行的数据,其中1万行具有较大的梯度。因此,我的算法将选择(10k行具有较大梯度 + 剩余的490k行的x%随机选择)。假设x为10%,则选择的总行数是59k,基于这些行找到了分裂值。
这里的基本假设是,具有较小梯度的训练实例具有较小的训练误差,并且已经训练得很好。为了保持相同的数据分布,在计算信息增益时,GOSS引入了一个常数乘数,用于具有较小梯度的数据实例。因此,GOSS在减少数据实例数量和保持学习决策树的准确性之间取得了良好的平衡。

LGBM在梯度/误差较大的叶子上进一步生长
2. 每个模型如何处理分类变量?
2.1 CatBoost
CatBoost具有灵活性,可以提供分类列的索引,以便可以使用one-hot编码进行编码,使用one_hot_max_size参数(对于具有不同值数量小于或等于给定参数值的所有特征使用one-hot编码)。
如果在cat_features参数中未传递任何内容,则CatBoost将将所有列视为数值变量。
注意:如果一个包含字符串值的列没有在cat_features中提供,CatBoost会抛出错误。另外,默认为int类型的列将默认视为数值型,如果要将其视为分类变量,必须在cat_features中指定。

对于剩余的分类列,其中唯一类别数大于one_hot_max_size的列,CatBoost使用一种类似于均值编码但减少过拟合的高效编码方法。该过程如下:
-
随机以随机顺序对输入观测集进行排列,生成多个随机排列;
-
将标签值从浮点数或类别转换为整数;
-
使用以下公式将所有分类特征值转换为数值:
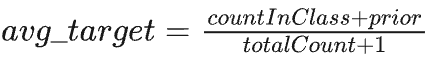
其中,countInClass表示标签值等于“1”的对象中当前分类特征值的出现次数,prior是分子的初步值,由起始参数确定,totalCount是具有与当前分类特征值匹配的当前对象之前的总对象数。
数学上,可以用以下方程表示:
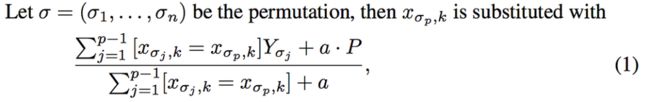
img
2.2 LightGBM
与CatBoost类似,LightGBM也可以通过输入特征名称来处理分类特征。它不会转换为独热编码,而且比独热编码快得多。LGBM使用一种特殊的算法来找到分类特征的分裂值。

img
注意:在构建LGBM数据集之前,您应该将分类特征转换为整数类型。即使通过categorical_feature参数传递了字符串值,它也不接受字符串值。
2.3 XGBoost
与CatBoost或LGBM不同,XGBoost本身不能处理分类特征,它只接受类似于随机森林的数值型数据。因此,在将分类数据提供给XGBoost之前,需要执行各种编码,如标签编码、均值编码或独热编码。
3. 理解参数
所有这些模型都有很多要调整的参数,但我们只讨论其中重要的参数。下面是这些参数的列表,根据它们的功能以及在不同模型中的对应参数。

img
4. 在数据集上的实现
我使用了2015年航班延误的Kaggle数据集,因为它既包含分类特征又包含数值特征。由于大约有500万行数据,这个数据集对于评估每种类型的提升模型在速度和准确性方面的性能是很好的。我将使用这个数据的10%子集,约50万行。
以下是用于建模的特征:
-
MONTH,DAY,DAY_OF_WEEK:数据类型int
-
AIRLINE和FLIGHT_NUMBER:数据类型int
-
ORIGIN_AIRPORT和DESTINATION_AIRPORT:数据类型字符串
-
DEPARTURE_TIME:数据类型float
-
ARRIVAL_DELAY:这将是目标变量,并转换为表示超过10分钟延误的布尔变量
-
DISTANCE和AIR_TIME:数据类型float
import pandas as pd, numpy as np, time
from sklearn.model_selection import train_test_split
data = pd.read_csv("./data/flights.csv")
data = data.sample(frac = 0.1, random_state=10)
data = data[["MONTH","DAY","DAY_OF_WEEK","AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT","AIR_TIME", "DEPARTURE_TIME","DISTANCE","ARRIVAL_DELAY"]]
data.dropna(inplace=True)
data["ARRIVAL_DELAY"] = (data["ARRIVAL_DELAY"]>10)*1
cols = ["AIRLINE","FLIGHT_NUMBER","DESTINATION_AIRPORT","ORIGIN_AIRPORT"]
for item in cols:
data[item] = data[item].astype("category").cat.codes + 1
train, test, y_train, y_test = train_test_split(data.drop(["ARRIVAL_DELAY"], axis=1), data["ARRIVAL_DELAY"],random_state=10, test_size=0.25)
4.1 XGBoost
import xgboost as xgb
from sklearn import metrics
from sklearn.model_selection import GridSearchCV
def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
# Parameter Tuning
model = xgb.XGBClassifier()
param_dist = {"max_depth": [10,30,50],
"min_child_weight" : [1,3,6],
"n_estimators": [200],
"learning_rate": [0.05, 0.1,0.16],}
grid_search = GridSearchCV(model, param_grid=param_dist, cv = 3,
verbose=10, n_jobs=-1)
grid_search.fit(train, y_train)
grid_search.best_estimator_
model = xgb.XGBClassifier(max_depth=50, min_child_weight=1, n_estimators=200,\
n_jobs=-1 , verbose=1,learning_rate=0.16)
model.fit(train,y_train)
auc(model, train, test)
4.2 LightGBM
import lightgbm as lgb
from sklearn import metrics
def auc2(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict(train)),
metrics.roc_auc_score(y_test,m.predict(test)))
lg = lgb.LGBMClassifier(verbose=0)
param_dist = {"max_depth": [25,50, 75],
"learning_rate" : [0.01,0.05,0.1],
"num_leaves": [300,900,1200],
"n_estimators": [200]
}
grid_search = GridSearchCV(lg, n_jobs=-1, param_grid=param_dist, cv = 3, scoring="roc_auc", verbose=5)
grid_search.fit(train,y_train)
grid_search.best_estimator_
d_train = lgb.Dataset(train, label=y_train)
params = {"max_depth": 50, "learning_rate" : 0.1, "num_leaves": 900, "n_estimators": 300}
# Without Categorical Features
model2 = lgb.train(params, d_train)
auc2(model2, train, test)
# With Catgeorical Features
cate_features_name = ["MONTH","DAY","DAY_OF_WEEK","AIRLINE","DESTINATION_AIRPORT",
"ORIGIN_AIRPORT"]
model2 = lgb.train(params, d_train, categorical_feature = cate_features_name)
auc2(model2, train, test)
4.3 CatBoost
在调整CatBoost的参数时,很难传递分类特征的索引。因此,我在没有传递分类特征的情况下调整了参数,并评估了两个模型——一个使用分类特征,另一个不使用分类特征。我单独调整了one_hot_max_size,因为它不会影响其他参数。
import catboost as cb
cat_features_index = [0,1,2,3,4,5,6]
def auc(m, train, test):
return (metrics.roc_auc_score(y_train,m.predict_proba(train)[:,1]),
metrics.roc_auc_score(y_test,m.predict_proba(test)[:,1]))
params = {'depth': [4, 7, 10],
'learning_rate' : [0.03, 0.1, 0.15],
'l2_leaf_reg': [1,4,9],
'iterations': [300]}
cb = cb.CatBoostClassifier()
cb_model = GridSearchCV(cb, params, scoring="roc_auc", cv = 3)
cb_model.fit(train, y_train)
With Categorical features
clf = cb.CatBoostClassifier(eval_metric="AUC", depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)
clf.fit(train,y_train)
auc(clf, train, test)
With Categorical features
clf = cb.CatBoostClassifier(eval_metric="AUC",one_hot_max_size=31, \
depth=10, iterations= 500, l2_leaf_reg= 9, learning_rate= 0.15)
clf.fit(train,y_train, cat_features= cat_features_index)
auc(clf, train, test)
5. 结论

在评估模型时,我们应该从速度和准确性两个方面考虑模型的性能。
考虑到这一点,CatBoost是赢家,测试集上的准确率最高(0.816),过拟合最小(训练集和测试集的准确率接近)且预测时间和调优时间最短。但这仅仅是因为我们考虑了分类变量并调整了one_hot_max_size。如果我们不利用CatBoost的这些特性,它的准确率只有0.752,表现最差。因此,我们得出结论,CatBoost仅在数据中存在分类变量且我们正确调整它们时表现良好。
我们的下一个表现良好的模型是XGBoost。即使忽略了我们在数据中有分类变量并将其转换为数值变量供XGBoost使用的事实,它的准确率仍与CatBoost相当接近。然而,XGBoost唯一的问题是速度太慢。调整其参数真的很令人沮丧,特别是使用GridSearchCV(运行GridSearchCV花费了我6个小时,非常糟糕的主意!)。更好的方法是单独调整参数,而不是使用GridSearchCV。阅读这篇博文,了解如何巧妙地调整参数。
最后,LightGBM排名最后。这里需要注意的一点是,当使用cat_features时,它在速度和准确性方面表现不佳。我认为它表现糟糕的原因是它对分类数据使用了某种修改过的均值编码,导致过拟合(训练准确率非常高——0.999,相比之下测试准确率较低)。然而,如果像XGBoost那样正常使用它,它可以以比XGBoost快得多的速度实现类似(甚至更高)的准确性(LGBM——0.785,XGBoost——0.789)。
最后,我必须说这些观察结果适用于这个特定的数据集,对于其他数据集可能有效也可能无效。然而,一般来说,一个真实的情况是XGBoost比其他两种算法更慢。