继承与派生(Part Ⅲ)——多重继承 & 虚基类
虚基类
虚基类的作用
- 如果一个派生类有多个直接基类,而这些直接基类又有一个共同的基类,则在最终的派生类中会保留该间接共同基类数据成员的多份同名成员。在引用这些同名的成员时,必须在派生类对象名后增加直接基类名,以避免产生二义性,使其唯一地标识一个成员,如
c1.A::display()。 - 在一个类中保留间接共同基类的多份同名成员,虽然有时是有必要的,可以在不同的数据成员中分别存放不同的数据,也可以通过构造函数分别对它们进行初始化。但在大多数情况下,这种现象是人们不希望出现的。因为保留多份数据成员的拷贝,不仅占用较多的存储空间,还增加了访问这些成员时的困难,容易出错。而且在实际上,并不需要有多份拷贝。
- C++提供虚基类(virtual base class)的方法,使得在继承间接共同基类时只保留一份成员。
- 假设类D是类B和类C公用派生类,而类B和类C又是类A的派生类。设类A有数据成员data和成员函数fun。派生类B和C分别从类A继承了data和fun,此外类B还增加了自己的数据成员data_b,类C增加了数据成员data_c。如果不用虚基类,在类D中保留了类A成员data的两份拷贝,表示为intB::data和int C::data。同样有两个同名的成员函数,表示为void B::fun()和void C::fun()。类B中增加的成员data_b和类C中增加的成员data_c不同名,不必用类名限定。此外,类D还增加了自己的数据成员data_d和成员函数fun_d。
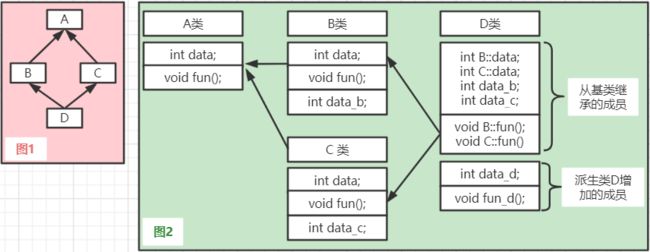
现在,将类A声明为虚基类,方法如下:
class A //声明基类A
{…};
classB:virtual publicA //声明类B是类A的公用派生类,A是B的虚基类
{…};
classC:virtual public A //声明类C是类A的公用派生类,A是C的虚基类
{…};
- 注意:虚基类并不是在声明基类时声明的,而是在声明派生类时,指定继承方式时声明的。因为一个基类可以在生成一个派生类时作为虚基类,而在生成另一个派生类时不作为虚基类。
- 声明虚基类的一般形式为:
class派生类名:virtual 继承方式 基类名
即在声明派生类时,将关键字virtual加到相应的继承方式前面。经过这样的声明后,当基类通过多条派生路径被一个派生类继承时,该派生类只继承该基类一次,也就是说,基类成员只保留一次。 - 在派生类B和C中作了上面的虚基类声明后,派生类D中的成员:
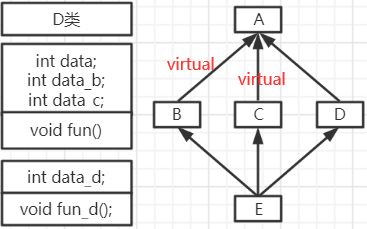
- 需要注意:为了保证虚基类在派生类中只继才一次,应当在该基类的所有直接派生类中声明为虚基类。否则仍然会出现对基类的多次继承。如图(右),如果在派生类B和C中将类A声明为虚基类,而在派生类D中没有将类A声明为虚基类,则在派生类E中,虽然从类B和c路径派生的部分只保留一份基类成员,但从类D路径派生的部分还保留一份基类成员。
虚基类的初始化
- 如果在虚基类中定义了带参数的构造函数,而且没有定义默认构造函数,则在其所有派生类(包括直接派生或间接派生的派生类)中,通过构造函数的初始化表对虚基类进行初始化。
class A //定义基类A
{ A(int i){} //基类构造函数,有一个参数
...};
class B:virtual public A //A作为B的虚基类
{B(int n):A(n){} //B类构造函数,在初始化表中对虚基类初始化
…};
class C:virtual publicA //A作为C的虚基类
{C(int n):A(n)){} //C类构造函数,在初始化表中对虚基类初始化
…};
class D:public B,public C //D类构造函数,在初始化表中对所有基类初始化
{D(int n):A(n),B(n),C(n){}
…};
- 注意:在定义D类构造函数时,与以往使用的方法有所不同。以前,在派生类的构造函数中只须负责对其直接基类初始化,再由其直接基类负责对间接基类初始化。现在,由于虚基类在派生类中只有一份数据成员,所以这份数据成员的初始化必须由派生类直接给出。如果不由最后的派生类(如图的类D)直接对虚基类初始化,而由虚基类的直接派生类(如类B和类C)对虚基类初始化,就有可能由于在类B和类C的构造函数中对虚基类给出不同的初始化参数而产生矛盾。所以规定:在最后的派生类中不仅要负责对其直接基类进行初始化,还要负责对虚基类初始化。
- C++编译系统只执行最后的派生类对虚基类的构造函数的调用,而忽略虚基类的其他派生类(如类B和类C)对虚基类的构造函数的调用,这就保证了虚基类的数据成员不会被多次初始化。
虚基类的简单应用举例
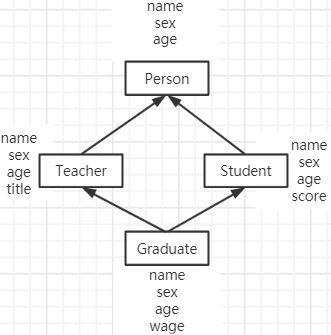
例:在Teacher类和Student类之上增加一个共同的基类Person。作为人员的一些基本数据都放在Person中,在Teacher类和Student类中再增加一些必要的数据。
#include 程序分析:
- Person类是表示一般人员属性的公用类,其中包括人员的基本数据,现在只包含了3个数据成员:name(姓名)、sex(性别)、age(年龄)。Teacher和Student类是Person的公用派生类,在Teacher类中增加title(职称),在Student类中增加score(成绩)。Graduate(研究生)是Teacher类和Student类的派生类,在Graduate类中增加wage(津贴)。为简化程序,除了最后的派生类Graduate外,在其他类中均不包含成员函数。
- 注意各类的构造函数的写法。在Person类中定义了包含3个形参的构造函数,用它对数据成员name、sex和age进行初始化。在Teacher和Student类的构造函数中,按规定要在初始化表中包含对基类的初始化,尽管对虚基类来说,编译系统不会由此调用基类的构造函数,但仍然应当按照派生类构造函数的统一格式书写。在最后派生类Graduate的构造函数中,既包括对虚基类构造函数的调用,也包括对其直接基类的初始化。
- 在Graduate类中,只保留一份基类的成员,因此可以用Graduate类中的show函数引用Graduate类对象中的公共基类Person的数据成员name,sex,age的值,不需要加基类名和域运算符::,不会产生二义性。
运行结果:

- 注意: 使用多重继承时要十分小心,经常会出现二义性问题。如果派生的层次再多一些,多重继承更复杂一些,程序设计人员很容易陷入迷魂阵,给程序的编写、调试和维护都带来许多困难。因此,许多专业人员认为:不提倡在程序中使用多重继承,只有在比较简单和不易出现二义性的情况或实在必要时才使用多重继承,如果能用单一继承解决的问题不要使用多重继承。也是这个原因,有些面向对象的程序设计语言(如Java,Smalltalk)并不支持多重继承。
基类与派生类的转换
- 不同类型数据之间在一定条件下可以进行类型的转换,不同类型数据之间的自动转换和赋值,称为赋值兼容。
- 基类和派生类对象之间也有赋值兼容关系,由于派生类中包含从基类继承的成员,因此可以将派生类的值赋给基类对象,在用到基类对象的时候可以用其子类对象代替。具体表现在以下几个方面:
- 派生类对象可以向基类对象赋值
可以用子类(即公用派生类)对象对其基类对象赋值。如
A a1; //定义基类A对象a1
B b1; //定义类A的公用派生类B的对象b1
a1=b1; //用派生类B对象b1对基类对象a1赋值

在赋值时舍弃派生类自己的成员,也就是"大材小用"。实际上,所谓赋值只是对数据成员赋值,对成员函数不存在赋值问题。
- 请注意:赋值后不能企图通过对象a1去访问派生类对象b1的成员,因为b1的成员与a1的成员是不同的。假设age是派生类B中增加的公用数据成员,分析下面的用法:
a1.age=23; //错误,a1中不包含派生类中增加的成员
b1.age=21; //正确,b1中包含派生类中增加的成员
应当注意,子类型关系是单向的、不可逆的。B是A的子类型,不能说A是B的子类型。只能用子类对象对其基类对象赋值,而不能用基类对象对其子类对象赋值,理由是显然的,因为基类对象不包含派生类的成员,无法对派生类的成员赋值。同理,同一基类的不同派生类对象之间也不能赋值。
- 派生类对象可以替代基类对象向基类对象的引用进行赋值或初始化
如已定义了基类A对象a1,可以定义a1的引用变量:
A a1; //定义基类A对象a1
B b1; //定义公用派生类B对象b1
A& r=a1; //定义基类A对象的引用变量r,并用a1对其初始化
这时,引用变量r是a1的别名,r和a1共享同一段存储单元。也可以用子类对象初始化引用变量r,将上面最后一行改为A& r=b1; //定义基类A对象的引用变量r,并用派生类B对象b1对其初始化或者保留上面第3行A& r=a1;,而对r重新赋值:r=b1; //用派生类B对象b1对a1的引用变量r赋值
- 注意:此时r并不是b1的别名,也不与b1共享同一段存储单元。它只是b1中基类部分的别名,r与b1中基类部分共享同一段存储单元,r与b1具有相同的起始地址。
- 如果函数的参数是基类对象或基类对象的引用,相应的实参可以用子类对象。
如有一函数fun:
void fun(A& r)//形参是A类对象的引用
{
cout << r.num << endl; //输出该引用中的数据成员num
}
函数的形参是类A的对象的引用变量,本来实参应该为A类的对象。由于子类对象与派生类对象赋值兼容,派生类对象能自动转换类型,在调用fun函数时可以用派生类B的对象b1作实参:fun(b1);输出类B的对象b1的基类数据成员num的值。与前相同,在fun函数中只能输出派生类中基类成员的值。
- 派生类对象的地址可以赋给指向基类对象的指针变量,也就是说,指向基类对象的指针变量也可以指向派生类对象。
例:定义一个基类Student(学生),再定义Student类的公用派生类Graduate(研究生), 用指向基类对象的指针输出数据。
#include 程序分析:
- 程序的输出结果中并没有输出wage的值,问题在于pt是指向Student类对象的指针变量,即使让它指向了grad1,但实际上pt指向的是grad1中从基类继承的部分。
- 通过指向基类对象的指针,只能访问派生类中的基类成员,而不能访问派生类增加的成员。所以pt->display()调用的不是派生类Graduate对象所增加的display函数,而是基类的display函数,所以只输出研究生grad1的num,name,score3个数据。如果想通过指针输出研究生grad1的wage,可以另设一个指向派生类对象的指针变量ptr,使它指向grad1,然后用ptr->display()调用派生类对象的display函数。
运行结果:

继承与组合
- 在一个类中可以用对象作为数据成员,即子对象。实际上,对象成员的类型可以是本派生类的基类,也可以是另一个已定义的类。在一个类中以另一个类的对象作为数据成员的,称为类的组合(composition)。
例:声明Professor(教授)类是Teacher(教师)类的派生类,另有一个类BirthDate(生日),包含year,month,day等数据成员。可以将教授生日的信息加入到Professor类的声明中。
class Teacher //教师类
{
public:
...
private:
int num;
string name;
char sex;
};
class BirthDate //生日类
{
public :
...
private:
int year;
int month;
int day;
};
class Professor:public Teacher //教授类
{
public:
...
private:
BirthDate birthday; //BirthDate类的对象作为数据成员
};
- 类的组合和继承一样,是软件重用的重要方式。组合和继承都是有效地利用已有类的资源。但二者的概念和用法不同。
- 通过继承建立了派生类与基类的关系,它是一种"是"的关系;通过组合建立了成员类与组合类(或称符合类)的关系,它们之间是"有"的关系。继承是纵向的,组合是横向的。
如果定义了Professor对象prof1,显然prof1包含了生日的信息。通过这种方法有效地组织和利用现有的类,大大减少了工作量。如果有以下两个函数:
void fun1(Teacher &);
void fun2(BirthDate &);
在main函数中调用这两个函数:
fun1(prof1); //正确,形参为Teacher类对象的引用,实参为Teacher类的子类对象,与之赋值兼容。
fun2(prof1.birthday); //正确,实参与形参类型相同,都是BirthDate类对象
fun2(prof1); //错误,形参要求是BirthDate类对象,而prof1是Professor类型,不匹配。
如果修改了成员类的部分内容,只要成员类的公用接口(如头文件名)不变,如无必要,组合类可以不修改。但组合类需要重新编译。
继承在软件开发中的重要意义
人们为什么这么看重继承,要求在软件开发中使用继承机制,尽可能地通过继承建立一批新的类。为什么不是将已有的类加以修改,使之满足自己应用的要求呢?归纳起来,有以下几个原因:
-
有许多基类是被程序的其他部分或其他程序使用的,这些程序要求保留原有的基类不受破坏。使用继承是建立新的数据类型,它继承了基类的所有特征,但不改变基类本身。基类的名称、构成和访问属性丝毫没有改变,不会影响其他程序的使用。
-
用户往往得不到基类的源代码。如果想修改已有的类,必须掌握类的声明和类的实现(成员函数的定义)的源代码。但是,如果使用类库,用户是无法知道成员函数的代码的,因此也就无法对基类进行修改。
-
在类库中,一个基类可能已被指定与用户所需的多种组件建立了某种关系,因此 在类库中的基类是不容许修改的(即使用户知道了源代码,也决不允许修改)。
-
实际上,许多基类并不是从已有的其他程序中选取来的,而是专门作为基类设计的。有些基类可能并没有什么独立的功能,只是一个框架,或者说是抽象类。人们根据需要设计了一批能适用于不同用途的通用类,目的是建立通用的数据结构,以便用户在此基础上添加各种功能建立各种功能的派生类。
-
在面向对象程序设计中,需要设计类的层次结构,从最初的抽象类出发,每一层派生类的建立都逐步地向着目标的具体实现前进,换句话说,是不断地从抽象到具体的过程。每一层的派生和继承都需要站在整个系统的角度统一规划,精心组织。