【通俗理解】CNN卷积神经网络 - 附带场景举例
一. CNN 算法概述
CNN的全称是Convolutional Neural Networks, ConvNets,称之为卷积神经网络,是深度学习的经典算法之一。

CNN一般用于图片分类、检索、人脸识别、目标定位等。在常规的图像处理的过程中,存在以下两个问题:
- 图像需要处理的数据量太大,导致成本很高,效率很低
- 图像在数字化的过程中很难保留原有的特征,导致图像处理的准确率不高。
而CNN很好的解决了这个问题:
- 能够将大数据量的图片有效的降维成小数据量(并不影响结果)
- 能够保留图片的特征,类似人类的视觉原理
放在实际的例子中,如图中CNN要做的事情是:给定一张图片代表交通工具,但是我不知道他具体是什么交通工具,现在需要模型判断这张图片到底属于哪个分类。结果输出:为车?或者为船?其实通俗的话来说,就是对于物体的分类实别。
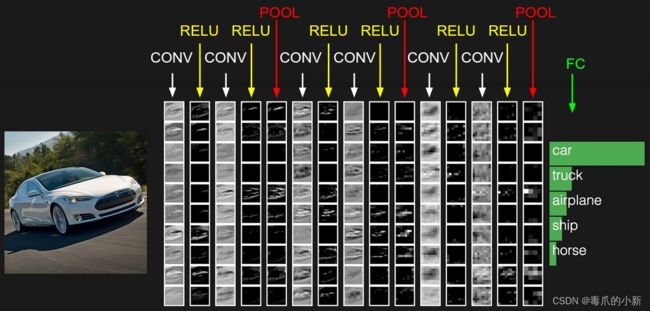
如上图所示,要实别一张图片,要经历上面几个层级结构:CONV层, RELU层, POOL层和FC层。当然了,看到这里你还是一脸懵逼,这些都是什么东西?当然了,不要着急,下面来详细介绍。
二. CNN层级结构
先来一个总结:
-
CONV:卷积计算层,线性乘积求和。 -
RELU:激励层,捕捉复杂模式。 -
POOL:池化层,取区域平均或最大。 -
FC:全连接层
好多人的文章写的太过复杂,下面我们来通过例子来通俗化的讲解
2.1 CONV卷积层
举例说明,当我们给定一个"X"的图案,计算机怎么识别这个图案就是"X"呢?

为了保证图形经过缩放或者变形都能被实别出来,对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征),每一个Feature就像是一个小图(就是一个比较小的有值的二维数组),不同的Feature匹配图像中不同的特征。

那什么东西叫做特征呢?例如下图所示,输入图片是一个人的脑袋,而人的眼睛是我们需要提取的特征,那么我们就将人的眼睛作为Features(特征),通过在人的脑袋的图片上移动来确定哪里是眼睛。
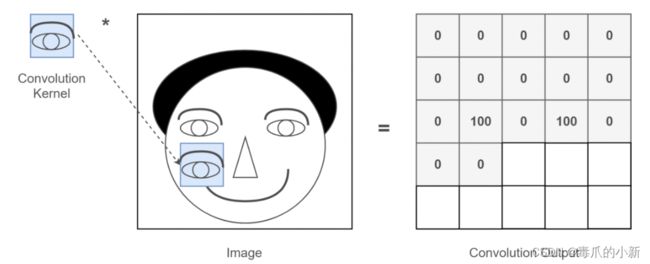
而Features(特征)的比较,CNN算法通常使用矩阵来进行。图形的本质就是一个二维矩阵,那么对矩阵表示的图像,进行内积操作(逐个元素相乘再求和)就是所谓的卷积,其目的是用来提取图像的底层特征。
举例说明:左边是图像输入,中间部分就是滤波器filter,滤波器是带着一组固定权重的神经元,一般表示为二维矩阵,该矩阵要比输入图像的二维矩阵要小或相等,在输入图像的二维矩阵上不停的移动。不同的滤波器会得到不同的输出数据,比如颜色深浅、轮廓。

放在代码中,他可能就是这样:图中左边部分是原始输入数据,图中中间部分是滤波器filter【特征在代码中也称之为滤波器,也可以称之为卷积核】,图中右边是输出的新的二维数据。一般情况下,通过滤波器,图像的尺寸就会变小,由此也可以提取出图像的特征信息。

听起来是不是好像有点复杂,而在实际代码过程中,其实就简单多了,只需要调整参数即可,如下代码。
from torch import nn
# 卷积层
self.c1 = nn.Conv2d(in_channels=4, out_channels=32, kernel_size=3, padding=1)
in_channels=4:这里表示输入通道为4,即输入为图像的通道数,比如RGB就是3通道图像,RGBA就为4通道图像。out_channels=32:表示输出为32通道kernel_size=3:表示我们的滤波器filter为一个3*3的矩阵padding=1:表示在图像周围填充1圈数据大小为0的固定数据
这里好像又出现了一个新名词,填充是啥。其实填充就是为了减少卷积操作导致的,边缘信息丢失,在图像周围填充固定数据,一般就是0。
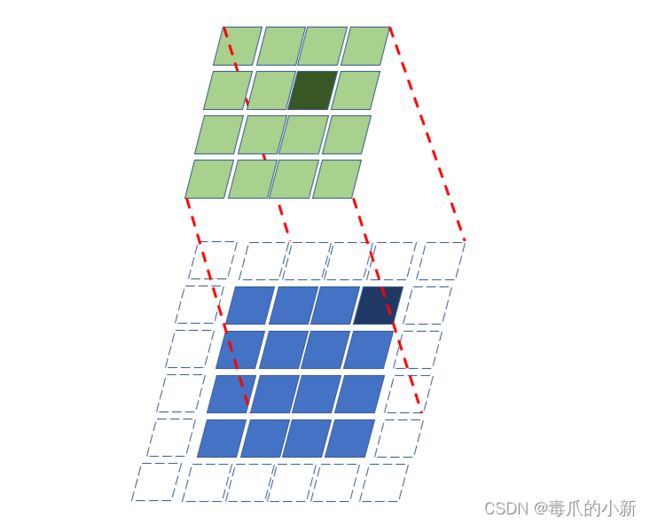
2.2 RELU激励层
用于引入非线性性质到神经网络中,从而使其能够捕捉复杂的模式和特征。
常用的激励函数是ReLU,它将张量的负值设置为零,保持正值不变,这个函数收敛快,求梯度简单。
而把数据压缩到0-1有什么作用,用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
from torch import nn
# 激励层
self.ReLU = nn.ReLU()
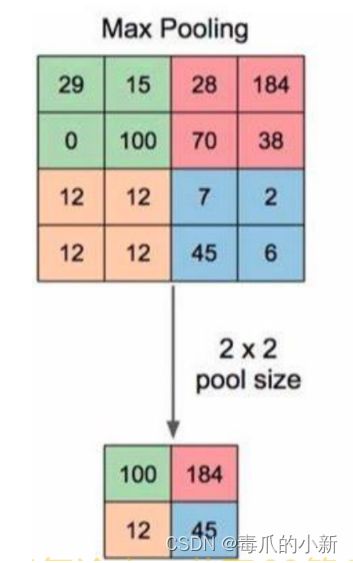
2.3 池化层
对信号进行“收集” 并“总结”,类似于水池收集水资源,其目的是减小卷积层数据的维度。
- 收集:由多变少,图像的尺寸由大变小
- 总结:一般使用区域最大值表示
import torch.nn as nn
# 池化层
self.s1 = nn.MaxPool2d(kernel_size=2, stride=1)
kernel_size=2:表示卷积核为2stride=1:表示卷积核每次移动步长为1
2.4 FC全连接层
全连接层又称为线性层,其每个神经元与上一层所有神经元相连,实现对前一层的线性组合,线性变换。其目的是汇总卷积层和池化层得到的图像的底层特征和信息。
线性层的数学表示为:
o u t p u t = i n p u t × w e i g h t T + b i a s output=input×weight^T+bias output=input×weightT+bias
其中input 是输入数据的张量,weight是权重矩阵,bias 是偏置向量。
但是这个在代码里面表示也很简单,如下所示。
import torch.nn as nn
# 全连接层
self.f3 = nn.Linear(6400,512)
表示输入通道为6400,输出通道为512。此时如果再来一个输出层
self.f4 = nn.Linear(512, 5)
表示输入通道为512,输出为5,此时的5一般就表示分类的数量,例如要区分5种不同的车。
三. 总结
CNN结构类似于一个水流结构,对一张图片拆分再拆分来捕捉其特征,到此为止,整个CNN实别过程结束。
主要参考文献:CNN笔记:通俗理解卷积神经网络