【大数据】CDC 技术:变化数据捕获
CDC 技术:变化数据捕获
- 1.什么是 CDC ?
- 2.批处理 vs CDC
- 3.四种 CDC 的实现方法
-
- 3.1 表元信息 Table metadata
- 3.2 表求差 Table differences
- 3.3 数据库触发器 Trigger-based CDC
- 3.4 数据库事务日志 Log-based CDC
- 4.Oracle CDC 详解
-
- 4.1 Oracle CDC 机制
-
- 4.1.1 同步复制 Synchronous Change Data Capture Configuration
- 4.1.2 异步在线日志 Asynchronous HotLog Configuration
- 4.1.3 异步分布式在线日志 Asynchronous Distributed HotLog Configuration
- 4.1.4 异步在线日志复制 Asynchronous Autolog Online Change Data Capture Configuration
- 4.1.5 归档日志 Asynchronous AutoLog Archive Change Data Capture Configuration
- 4.2 Oracle CDC 实现方法
- 5.总结
CDC(Change Data Capture)是一种用以掌控数据变化的软件架构(或者再通俗一点:技术思路)。具体架构 / 思想背后会有不同的工程实现思路,本文我们就来深入理解一下。
1.什么是 CDC ?
CDC 这个名词应该大家都不难理解,直译就是 “变化数据捕获”,实际的含义也是如此:当数据库里的表发生了 增(INSERT) / 改(UPDATE)/ 删(DELETE)的时候,会将这种变化实时 / 非实时地发送给下游的系统进行处理。此时,对大数据有一定了解的小伙伴可能就会问了,下游的系统为什么要拿到这些变化,拿了之后能做什么呢?我用一个具体的场景来说明一下,大家就明白了。
假如我是一个数据工程师,我的任务是将 N 个业务数据库(后面简称 DB)的数据汇总到时下最流行的 数据湖仓(后面简称 LH)中进行统一存储:
- 对于新接入的数据库,我直接把全部数据导入,这个非常简单。
- 对于已导入的数据,如果业务数据库里面某条记录发生了变化,我要如何确保 DB 中的数据和 LH 的数据是一致的呢?
我们用一个更简化的例子,来简单介绍下面对数据变化我们能采用的方法,以及背后的思路。我们用数组 A 来模拟业务数据库 DB,用数组 B 来模拟数据湖仓 LH,具体的内容直接在下面的代码中用注释说明。
// 最开始,数据都在业务数据库里
A := []int{1, 2, 3, 4, 5} // 这里表示初始化了一个数组
// 我们想让数组 B 和数组 A 的数据保持一致,第一步要全量导入
B := []int{} // 先初始化一个 B 数组
for idx, value := range A {
B = append(B, value) // 通过循环,把 A 中的每个元素都添加到 B 中
}
// 此时,A 数组中的第 3 个元素发生了变化
A[2] = 30
// 我们怎么让 B 数组也同步这个变化呢?
// 方法一:再全量导入一次
for idx, value := range A {
B[idx] = A[idx] // 通过循环,把 A 中的每个元素覆盖到 B
}
// 方法二:记录变化,然后对应修改
// 我们先定义一个数据结构,来记录变化
type ChangeLog struct {
Index int, // 表示变化的索引
Action string, // 表示变化的动作
Value int, // 表示变化后的值
}
// 然后我们用这个结构来记录前面 A[2] = 30 这个变化
log := ChangeLog{
Index: 2,
Action: "UPDATE",
Value: 30,
}
// 接着我们直接基于变化的记录来更新 B 数组即可
if log.Action == "UPDATE" {
B[log.Index] = B[log.Value]
}
我们可以看到,上的两种方法,最终都可以做到让数组 B 中的内容与数组 A 一致,但是这两种方法背后的思路可谓大相径庭。方法一的思想是批处理(Batch Processing),一次处理一批任务,在更真实的场景下,这样的操作一般来说会定时进行一次,比如每天,或者每小时。而方法二的想就是 CDC,通过跟踪数据的变化,用较小的代价完成数据同步。
2.批处理 vs CDC
我们如果再仔细想想方法一(即批处理,Batch Processing)在真实场景下的应用,就会发现这其中有不少问题:
- 数据不是实时同步的,如果每个小时进行一次批处理,那么新增加的数据要 1 个小时后,才能从业务数据库同步到数据湖仓(也就是从数组 A 到数组 B)。
- 有的时候不得不进行全量同步,而全量同步在某些场景下是非常低效的,比如前面数组 A 只是改变了 1 个数字,但是却需要做 5 次复制操作。
- 因为是每个小时同步一次,在开始同步到同步结束的过程里,需要大量读取业务数据库,会给业务数据库比较大的压力,有可能会影响到真实的业务。
- 如果说全量同步和增量同步可以很好解决新数据和修改了的老数据,但是在业务数据库删除了某些记录的场景下,想要把这个变化同步到数据湖仓,并不简单(想想看,如果数组 A 我们不是修改值,而是删除了某个元素,使用方法一,很难简单把这个变化同步到数组 B,是不是?)。
- 如果我们想要提升同步的速度,就只能把批处理的时间间隔缩短,就会有非常非常多的批处理任务,如何管理这些任务,就变成了新的问题。
带着上面这些问题,我们来看看方法二(即 CDC,Change Data Capture)的思路,就会发现好像所有的问题都 “理论上” 能够迎刃而解:
- CDC 的机制使得准实时同步成为可能,当业务数据库发生变化时,对应的变更记录可以实时发送给数据湖仓(当然,也可以是反过来,数据湖仓可以实时知道业务数据库发生了变化),考虑到处理数据可能需要一点时间,所以至少能够做到准实时。
- CDC 因为知道具体哪些数据变化,是如何变化的,所以几乎不太需要全量同步,精准带来了高效。
- 很多业务数据库(如
Postgres/MySQL/SQL Server等)都原生支持了 CDC,在数据变更时会保存对应的记录(可能需要配置参数开启)。这就避免了像批处理一样需要大量读取业务数据库,直接使用对应的变更记录即可。退一步说,即使没有原生 CDC 机制,通过记录变更的方式把数据变动打散到每次变更里(而不是像批处理一次读取很多),对实际业务的影响微乎其微。 - CDC 可以很好记录业务数据库中的删除操作,比如我们可以在变更日志中记录
action为DELETE,然后对应在数据湖仓中删除数据即可,这样的方式就比批处理要优雅很多(参考前面第 4 点的说明)。 - CDC 因为天然和流、实时契合,所以如果我们想要提升同步速度,只需要尽量降低网络延迟以及计算性能,不会带来新的问题(参考前面第 5 点中提及的问题)。
3.四种 CDC 的实现方法
前面我们已经了解了 CDC 这种技术思路的先进性,但是具体到工程上,受限于各类计算机的限制,目前并没有一种完美的方法,不同的实现方法在不同的场景下各有优劣,我们下面就具体了解一下。
3.1 表元信息 Table metadata
这种方式会记录表中每一行数据的元信息,比如这一行啥时候被创建以及啥时候被更新,一般来说需要增加额外的列来记录这些信息(比如 created_at 和 updated_at)。这些元信息一般来说在增量批处理中来识别新增和更新的行。具体的用法就很多了,最简单的一种就是看 update_at 是否在上一次已完成同步的时间点之后,这意味着这些数据需要在这一次同步。
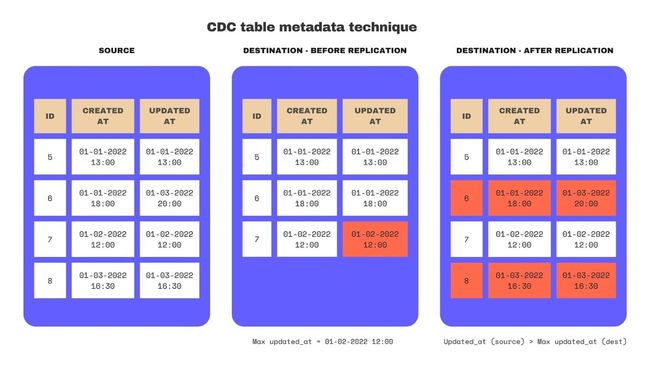
上图是一个具体的例子,我们可以看到在最左边的业务数据库中,有 5、6、7、8 一共四条数据。而在进行数据同步之前我们的数据湖仓里只有 5、6、7 三条数据,并且最后的更新时间为 2022-01-02 12:00。我们在做增量同步的时候,就只需要找业务数据库中 updated_at 字段的时间大于 2022-01-02 12:00 的记录(也就是编号 6 和 8 的数据),然后同步到数据湖仓中即可。
这个方法的好处很明显,并不需要依赖任何外部工具,结合好的应用逻辑设计可以快速实现。
不过,大家可能感觉有哪里不对。为什么这个方法更像前面说的方法一(批处理)而不是想象中的 CDC 呢?你的感觉完全正确,这种方法可以理解为批处理方法借鉴 CDC 思想的加强版,所以前面提到的批处理的五个问题,仍然有两个解决不了:
- 仍然会对业务数据库带来查询上的压力。
- 没有办法去处理业务数据库里删除记录的同步问题。
不仅如此,这种方法很容易出错并导致数据一致性问题,所以这种方法在新系统的同步中用得并不多,但是在部分老系统,或者业务数据库不会出现删除的情况的前提下,因为这种方法实现起来比较简单,所以也可以考虑使用。
3.2 表求差 Table differences
这个方法也非常简单直接,一般来说直接使用数据库提供的函数就可以找到源表和目标表的差别(例如 SQL Server 提供了 tablediff 功能)。这个方法不但可以找到新增和修改的行,也可以找到删除的行。

上图是一个具体的例子,我们通过一句 SQL 命令,找到了两张表之间的差别,然后再进行同步。但是就像大家来找茬一样,让计算机找到两张表的差别,实际上要花费大量的计算。举个简化一点的例子,我们想要判断两个数组中的元素是否完全一致,需要对两个数组的元素排序后逐一对比。
再多想一层:如果两张表的数据量不断增加,找到差异的过程就会越来越耗时,在分布式系统中,这个问题会变得更加难以处理。你看,为了解决可能出现删除的情况,居然要花费这么大代价,这告诉我们在设计底层数据逻辑的时候,一定要精心设计,不然只能花费更多资源为不好的设计买单。
那么问题来了,为什么会有这样的方法呢,太不经济了吧!但这个方法其实也有对应的使用场景,在数据量不大的情况下,只需要使用 SQL 就可以得到准确的数据变化的记录,实现起来简单。
这个看似简单的技术其实告诉了我们一个道理:存在即合理,不要被自己的知识困住,很多时候只是因为我们没有看到技术背后的场景。
3.3 数据库触发器 Trigger-based CDC
Trigger-based 的原理和前面提到的方法二很相似,在数据库进行 INSERT / UPDATE / DELETE 操作的时候,会触发执行另一段 SQL,就可以在另一张影子表中记录数据的变化。接下来做数据同步就很简单,只需要关注影子表里的记录,然后对应再执行一次即可。

创建一个触发器也很简单,我们以 PostgreSQL 为例:
CREATE [ OR REPLACE ] [ CONSTRAINT ] TRIGGER name { BEFORE | AFTER | INSTEAD OF } { event [ OR ... ] }
ON table_name
[ FROM referenced_table_name ]
[ NOT DEFERRABLE | [ DEFERRABLE ] [ INITIALLY IMMEDIATE | INITIALLY DEFERRED ] ]
[ REFERENCING { { OLD | NEW } TABLE [ AS ] transition_relation_name } [ ... ] ]
[ FOR [ EACH ] { ROW | STATEMENT } ]
[ WHEN ( condition ) ]
EXECUTE { FUNCTION | PROCEDURE } function_name ( arguments )
where event can be one of:
INSERT
UPDATE [ OF column_name [, ... ] ]
DELETE
TRUNCATE
这种方式看起来还挺不错的,实现简洁明了,只需要用 SQL 语句就可以。但在实际使用中,还是会遇到如下问题:
- 如果原始表中的某个事务(比如
INSERT)失败了,我们需要自己实现具体的逻辑,在影子表中删除对应记录。这里实际上就是把原来的原子操作变得不原子了,所以需要额外解决一致性问题。 - 如果原始表的结构变化了,比如多个一个字段或少了一个字段,那么对应的
trigger也需要修改,因为trigger和原始表是强依赖的。 - 在同一个数据库还好,如果有多种业务数据库,那么对应的
trigger语句是没有办法复用的,因为不同数据库的 SQL 或多或少有差别。 - 其实在 1 点也提到,
trigger的本质就是在执行某条 SQL 的时候再多执行一段 SQL,这会极大增加数据库的负担。
这样看来好像前面的都或多或少有问题,有没有更好的呢?有!
3.4 数据库事务日志 Log-based CDC
Log-based 其实和 Trigger-based 非常相似,我们从下面的图中就能很清楚的看出来,所有数据的变动要么放在日志里,要么放在影子表里,内容上是一致的。但这里的差别在于 Log-based 方法更好利用了数据库本身的核心能力,即大部分关系型数据,在数据发生变化的时候都会产生日志,如果我们直接用这样的日志来进行数据同步,不但可以在不同的系统间保证 ACID 可靠,对数据库的影响几乎可以忽略不计(不需要修改表结构,也不需要新增影子表),并且日志是实时产生的,可以有更好的时效性。

这样一看,似乎 Log-based 的方法很完美!但世界上没有完美的东西,我们仍然需要面对以下的问题:
- 部分数据库的操作在事务日志中不会出现,比如
ALTER或TRUNCATE,那么我们需要做些额外的操作来记录这些日志。 - 如果目标数据库短暂挂掉,那么对应的日志应该停止处理(如何保证呢),不然就会丢失数据变化。
- 不同数据库的事务日志的格式都不一样,如何解析是个大问题,并且随着版本更新还可能会变化。
4.Oracle CDC 详解
前面我们已经了解了 CDC 的几种具体的实现方法,接下来就来来看看用什么方法才能搞定最难处理的 Oracle 数据库。为什么说是最难呢?因为难点并不是技术上的,而是在于 Oracle 在闭源的同时,并不提供甚至也并不打算提供 CDC 相关接口。不过办法总比困难多,我们总是有办法可以解决的,在介绍具体的方法之前,我们先来了解下 Oracle CDC 的机制。
4.1 Oracle CDC 机制
Oracle CDC 的具体实现基于发布者 / 订阅者模型,发布者捕捉变化数据并提供给订阅者。和我们前面介绍的方法相比,会有更多工程的考量,也引入了一些新的概念,我们统一总结如下:
- 源表(
Source Table):数据同步的来源,比如一张具体的业务表。 - 变化表(
Change Table):保存从源表捕获的变化数据,可以理解为前面提到的影子表。 - 变化集(
Change Set):保证事务一致性的数据集合。一个变化集对应多个变化表,这部分就是在实际场景中为了确保数据库事务增加的概念。 - 订阅视图(
Subscription View):提供给订阅者读取变化表数据的视图。
4.1.1 同步复制 Synchronous Change Data Capture Configuration

这种方式实际上就是 Trigger-based 方法,实际上只能在同一个 Oracle 数据库中的不同表中进行数据同步,用处嘛,不大。
4.1.2 异步在线日志 Asynchronous HotLog Configuration

LGWR 是 Oracle 的后台进程之一。LGWR 的作用是把日志缓存区的数据从内存写到磁盘的 REDO 文件里,完成数据库对象创建、更新数据等操作过程的记录。
这个方法使用的是 Log-based 方法,但这里用的是在线日志,虽然看起来简单,但是也只能在同一个 Oracle 数据库中的不同表中进行数据同步,用处嘛,也不大。
4.1.3 异步分布式在线日志 Asynchronous Distributed HotLog Configuration

这个方法是上一个方法的拓展,通过 Database Link 机制让数据同步可以跨数据库进行,但本质原理和上一个机制是一样的,用处嘛,有一点用。
4.1.4 异步在线日志复制 Asynchronous Autolog Online Change Data Capture Configuration

在 Oracle 数据库中,RFS(Remote File Server)进程是 Data Guard 的一部分,负责将主库上生成的 Redo 日志传输到备库。
LOG_ARCHIVE_DEST_n 参数可以设置最多 10( n = [ 1...10 ] n=[1...10] n=[1...10])个不同的归档路径,通过设置关键词 location 或 service,该参数指向的路径可以是本地或远程的。
这种方式就复杂很多,使用的是热备数据库的日志(Standby Redo Log),对主数据库的影响较小,但既然都做到这一步了,不如直接用下一个方法。
4.1.5 归档日志 Asynchronous AutoLog Archive Change Data Capture Configuration

ARC 文件是 Oracle 数据库的一种备份文件格式,该格式主要用于备份 Oracle 数据库的数据和日志文件。
这个方法是理论上来说最优的,几乎完全不影响数据库的性能,并且可以借助各类大数据工具来串起来整个 CDC 流程。
不过有一千道一万,还有一个绕不开的问题需要解决,就是如何解析日志呢?尤其在日志不开源且没有任何文档的前提下。
4.2 Oracle CDC 实现方法
Oracle 官方曾经提供过免费几种 CDC 工具,但目前在高版本都弃用了,敏感的朋友们应该能够猜到:因为 Oracle 出了付费 CDC 产品 - GoldenGate,价格嘛,不便宜:

注:这个只是云服务的计费,实际上还需要配套一系列硬件资源才能用起来。
所以现在一般来说,有 3 种方法:
- Logminer:Oracle 官方提供的日志分析工具,目前大部分开源工具集成该工具(如
debezium),但因为这个工具运行在 Oracle 数据库内部,会占用资源,性能提升比较难(但也不是没有办法)。 - XStream:Oracle 内部接口,需要购买授权,而授权非常贵!
- 日志解析
- 官方版:直接根据源代码来开发解析工具,速度比 Logminer 快,但是工程量很大。
- 逆向版:顾名思义,要么通过源码,要么硬来。一旦遇到改规则就不可用,这个工程量和试验量就不用说了,全球就没几家能搞定的。
从这里我们就能看到,一个小小的问题,难倒众多英雄汉呀。
5.总结
目前 Log-based 的方法是现阶段我们可以用到的最佳方法,在大部分情况比原来的方法更高效、更可信,对源数据库(比如业务数据库)的影响更小。如果可以,直接使用 Log-based 方法。如果因为条件所限无法使用 Log-based 方法,那么可以根据实际场景,选择最合适的方法,来完成数据同步的需求。
Log-based 是好方法,但如果想做到尽善尽美,仍然需要数据工程师不懈努力,解决一个又一个实际场景的问题(比如前面 Oracle 就是一个很好的例子)。这里就需要大量的积累了,魔鬼藏在细节中。
现在再回过头来看看前面数组 A 和数组 B 的问题,是不是有了新的视角?再想想开源与闭源,是不是对 Oracle 的商业模式有了新的认识?