基于PyTorch的目标检测系统(口罩检测)
一、开发环境
- Windows 10
- Python 3.7.3
- PyTorch 1.7.0
二、准备数据集,作者使用了450张标注好的图片作为训练集,127张作为验证集。
三、编写训练模型的代码
def train(hyp, # path/to/hyp.yaml or hyp dictionary
opt,
device,
callbacks
):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, noval, nosave, workers, freeze, = \
Path(opt.save_dir), opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.noval, opt.nosave, opt.workers, opt.freeze
# Directories
w = save_dir / 'weights' # weights dir
(w.parent if evolve else w).mkdir(parents=True, exist_ok=True) # make dir
last, best = w / 'last.pt', w / 'best.pt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp, errors='ignore') as f:
hyp = yaml.safe_load(f) # load hyps dict
LOGGER.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
data_dict = None
# Loggers
if RANK in [-1, 0]:
loggers = Loggers(save_dir, weights, opt, hyp, LOGGER) # loggers instance
if loggers.wandb:
data_dict = loggers.wandb.data_dict
if resume:
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp
# Register actions
for k in methods(loggers):
callbacks.register_action(k, callback=getattr(loggers, k))
# Config
plots = not evolve # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with torch_distributed_zero_first(LOCAL_RANK):
data_dict = data_dict or check_dataset(data) # check if None
train_path, val_path = data_dict['train'], data_dict['val']
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, f'{len(names)} names found for nc={nc} dataset in {data}' # check
is_coco = isinstance(val_path, str) and val_path.endswith('coco/val2017.txt') # COCO dataset
# Model
check_suffix(weights, '.pt') # check weights
pretrained = weights.endswith('.pt')
if pretrained:
with torch_distributed_zero_first(LOCAL_RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
model = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
csd = ckpt['model'].float().state_dict() # checkpoint state_dict as FP32
csd = intersect_dicts(csd, model.state_dict(), exclude=exclude) # intersect
model.load_state_dict(csd, strict=False) # load
LOGGER.info(f'Transferred {len(csd)}/{len(model.state_dict())} items from {weights}') # report
else:
model = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
# Freeze
freeze = [f'model.{x}.' for x in range(freeze)] # layers to freeze
for k, v in model.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze):
LOGGER.info(f'freezing {k}')
v.requires_grad = False
# Image size
gs = max(int(model.stride.max()), 32) # grid size (max stride)
imgsz = check_img_size(opt.imgsz, gs, floor=gs * 2) # verify imgsz is gs-multiple
# Batch size
if RANK == -1 and batch_size == -1: # single-GPU only, estimate best batch size
batch_size = check_train_batch_size(model, imgsz)
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
LOGGER.info(f"Scaled weight_decay = {hyp['weight_decay']}")
g0, g1, g2 = [], [], [] # optimizer parameter groups
for v in model.modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter): # bias
g2.append(v.bias)
if isinstance(v, nn.BatchNorm2d): # weight (no decay)
g0.append(v.weight)
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter): # weight (with decay)
g1.append(v.weight)
if opt.adam:
optimizer = Adam(g0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
optimizer = SGD(g0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
optimizer.add_param_group({'params': g1, 'weight_decay': hyp['weight_decay']}) # add g1 with weight_decay
optimizer.add_param_group({'params': g2}) # add g2 (biases)
LOGGER.info(f"{colorstr('optimizer:')} {type(optimizer).__name__} with parameter groups "
f"{len(g0)} weight, {len(g1)} weight (no decay), {len(g2)} bias")
del g0, g1, g2
# Scheduler
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=lf) # plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA
ema = ModelEMA(model) if RANK in [-1, 0] else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, f'{weights} training to {epochs} epochs is finished, nothing to resume.'
if epochs < start_epoch:
LOGGER.info(f"{weights} has been trained for {ckpt['epoch']} epochs. Fine-tuning for {epochs} more epochs.")
epochs += ckpt['epoch'] # finetune additional epochs
del ckpt, csd
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
LOGGER.warning('WARNING: DP not recommended, use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model = torch.nn.DataParallel(model)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model).to(device)
LOGGER.info('Using SyncBatchNorm()')
# Trainloader
train_loader, dataset = create_dataloader(train_path, imgsz, batch_size // WORLD_SIZE, gs, single_cls,
hyp=hyp, augment=True, cache=opt.cache, rect=opt.rect, rank=LOCAL_RANK,
workers=workers, image_weights=opt.image_weights, quad=opt.quad,
prefix=colorstr('train: '), shuffle=True)
mlc = int(np.concatenate(dataset.labels, 0)[:, 0].max()) # max label class
nb = len(train_loader) # number of batches
assert mlc < nc, f'Label class {mlc} exceeds nc={nc} in {data}. Possible class labels are 0-{nc - 1}'
# Process 0
if RANK in [-1, 0]:
val_loader = create_dataloader(val_path, imgsz, batch_size // WORLD_SIZE * 2, gs, single_cls,
hyp=hyp, cache=None if noval else opt.cache, rect=True, rank=-1,
workers=workers, pad=0.5,
prefix=colorstr('val: '))[0]
if not resume:
labels = np.concatenate(dataset.labels, 0)
# c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir)
# Anchors
if not opt.noautoanchor:
check_anchors(dataset, model=model, thr=hyp['anchor_t'], imgsz=imgsz)
model.half().float() # pre-reduce anchor precision
callbacks.run('on_pretrain_routine_end')
# DDP mode
if cuda and RANK != -1:
model = DDP(model, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model attributes
nl = de_parallel(model).model[-1].nl # number of detection layers (to scale hyps)
hyp['box'] *= 3 / nl # scale to layers
hyp['cls'] *= nc / 80 * 3 / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3 / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model.nc = nc # attach number of classes to model
model.hyp = hyp # attach hyperparameters to model
model.class_weights = labels_to_class_weights(dataset.labels, nc).to(device) * nc # attach class weights
model.names = names
# Start training
t0 = time.time()
nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
maps = np.zeros(nc) # mAP per class
results = (0, 0, 0, 0, 0, 0, 0) # P, R, [email protected], [email protected], val_loss(box, obj, cls)
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = amp.GradScaler(enabled=cuda)
stopper = EarlyStopping(patience=opt.patience)
compute_loss = ComputeLoss(model) # init loss class
LOGGER.info(f'Image sizes {imgsz} train, {imgsz} val\n'
f'Using {train_loader.num_workers * WORLD_SIZE} dataloader workers\n'
f"Logging results to {colorstr('bold', save_dir)}\n"
f'Starting training for {epochs} epochs...')
for epoch in range(start_epoch, epochs): # epoch ------------------------------------------------------------------
model.train()
# Update image weights (optional, single-GPU only)
if opt.image_weights:
cw = model.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset.labels, nc=nc, class_weights=cw) # image weights
dataset.indices = random.choices(range(dataset.n), weights=iw, k=dataset.n) # rand weighted idx
# Update mosaic border (optional)
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset.mosaic_border = [b - imgsz, -b] # height, width borders
mloss = torch.zeros(3, device=device) # mean losses
if RANK != -1:
train_loader.sampler.set_epoch(epoch)
pbar = enumerate(train_loader)
LOGGER.info(('\n' + '%10s' * 7) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'labels', 'img_size'))
if RANK in [-1, 0]:
pbar = tqdm(pbar, total=nb, ncols=NCOLS, bar_format='{l_bar}{bar:10}{r_bar}{bar:-10b}') # progress bar
optimizer.zero_grad()
for i, (imgs, targets, paths, _) in pbar: # batch -------------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
imgs = imgs.to(device, non_blocking=True).float() / 255 # uint8 to float32, 0-255 to 0.0-1.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# compute_loss.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = nn.functional.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
# Forward
with amp.autocast(enabled=cuda):
pred = model(imgs) # forward
loss, loss_items = compute_loss(pred, targets.to(device)) # loss scaled by batch_size
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
# Backward
scaler.scale(loss).backward()
# Optimize
if ni - last_opt_step >= accumulate:
scaler.step(optimizer) # optimizer.step
scaler.update()
optimizer.zero_grad()
if ema:
ema.update(model)
last_opt_step = ni
# Log
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = f'{torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0:.3g}G' # (GB)
pbar.set_description(('%10s' * 2 + '%10.4g' * 5) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets.shape[0], imgs.shape[-1]))
callbacks.run('on_train_batch_end', ni, model, imgs, targets, paths, plots, opt.sync_bn)
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in optimizer.param_groups] # for loggers
scheduler.step()
if RANK in [-1, 0]:
# mAP
callbacks.run('on_train_epoch_end', epoch=epoch)
ema.update_attr(model, include=['yaml', 'nc', 'hyp', 'names', 'stride', 'class_weights'])
final_epoch = (epoch + 1 == epochs) or stopper.possible_stop
if not noval or final_epoch: # Calculate mAP
results, maps, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=ema.ema,
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
plots=False,
callbacks=callbacks,
compute_loss=compute_loss)
# Update best mAP
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, [email protected], [email protected]]
if fi > best_fitness:
best_fitness = fi
log_vals = list(mloss) + list(results) + lr
callbacks.run('on_fit_epoch_end', log_vals, epoch, best_fitness, fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt = {'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': optimizer.state_dict(),
'wandb_id': loggers.wandb.wandb_run.id if loggers.wandb else None,
'date': datetime.now().isoformat()}
# Save last, best and delete
torch.save(ckpt, last)
if best_fitness == fi:
torch.save(ckpt, best)
if (epoch > 0) and (opt.save_period > 0) and (epoch % opt.save_period == 0):
torch.save(ckpt, w / f'epoch{epoch}.pt')
del ckpt
callbacks.run('on_model_save', last, epoch, final_epoch, best_fitness, fi)
# Stop Single-GPU
if RANK == -1 and stopper(epoch=epoch, fitness=fi):
break
# Stop DDP TODO: known issues shttps://github.com/ultralytics/yolov5/pull/4576
# stop = stopper(epoch=epoch, fitness=fi)
# if RANK == 0:
# dist.broadcast_object_list([stop], 0) # broadcast 'stop' to all ranks
# Stop DPP
# with torch_distributed_zero_first(RANK):
# if stop:
# break # must break all DDP ranks
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in [-1, 0]:
LOGGER.info(f'\n{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.')
for f in last, best:
if f.exists():
strip_optimizer(f) # strip optimizers
if f is best:
LOGGER.info(f'\nValidating {f}...')
results, _, _ = val.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz,
model=attempt_load(f, device).half(),
iou_thres=0.65 if is_coco else 0.60, # best pycocotools results at 0.65
single_cls=single_cls,
dataloader=val_loader,
save_dir=save_dir,
save_json=is_coco,
verbose=True,
plots=True,
callbacks=callbacks,
compute_loss=compute_loss) # val best model with plots
if is_coco:
callbacks.run('on_fit_epoch_end', list(mloss) + list(results) + lr, epoch, best_fitness, fi)
callbacks.run('on_train_end', last, best, plots, epoch, results)
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
torch.cuda.empty_cache()
return results
四、开始训练,作者的电脑显卡只有2G内存,大约训练了3小时左右。
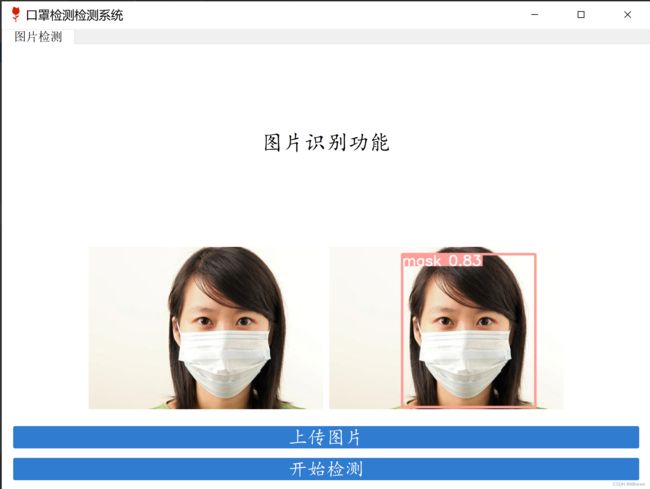
五、训练结束后,进行测试,效果还是不错的。
六、完整源码和数据集下载:
链接:https://pan.baidu.com/s/11C95VxMk3Z54vocs2hNF4A?pwd=8ld6
提取码:8ld6