【VL tracking】Towards Unified Token Learning for Vision-Language Tracking

不知道什么原因学校认证账号进不去,下载不了最新的PDF

广西师范大学 | 国科大 | 厦大
代码开源
zhihu指路【VL tracking】MMTrack阅读
问题
一方面,传统的VL tracking方法需要昂贵的先验知识。例如,一些tracker是专门用于bounding box的,它们使用区域建议网络(基于锚点的机制)和ROI池化来生成跨模态融合和对齐的建议实例。
另一方面,在多任务学习中,寻找一个有利于vision-language理解的训练目标是困难的。例如,将各种损失函数用于某个特定的模块或任务中,如果一个模型想要有效地学习所有类型任务的特征,调整会是困难的并且泛化能力有限。
为了简化VL tracking建模,本文提出一种概念简单但有效的VL多模态跟踪pipeline,称作MMTrack。
Contributions
- 本文将视觉语言跟踪重新定义为一项token生成任务,并提出了一个新颖的pipeline,从统一建模的角度释放视觉语言多模态学习的潜力。
- 整个方法简单灵活,将语言和边界框统一作为多线索的token输入。它避免了冗余的子任务学习和优化目标,并且只使用交叉熵作为统一的训练目标。
- 本文提出的方法在4个VL基准测试上实现了最先进的跟踪结果,表明该方法可以成为VL Tracking新的baseline。
方法
讨论与基于序列的工作的不同之处
pix2seq采用语言建模的方式解决了目标检测任务,取得了较好的结果。受其理念启发,作者为跟踪社区贡献了一种新颖的VL多模态跟踪模型,工作区别在以下几个方面:
- pix2seq是为目标检测而设计的,而作者创造性地将其扩展到了VL跟踪任务的多模态建模,并为文本视频理解设计了一个多模态编码器。这超出了原方法单模态的限制。
- pix2seq从边界框、类别和噪声数据中创建长序列。相比之下,作者通过仅依赖于边界框和文本信息来简化序列构建策略,避免使用类别和其他噪声策略。因此通过防止长而复杂的序列,本文提出的方法减少了训练负荷,更好地适应了VL跟踪任务。
SeqTrack与本文研究相似,但区别在以下几个方面:
- SeqTrack是专门针对涉及视觉模态的纯视觉跟踪任务而设计的,在处理多模态数据输入方面缺乏灵活性。相比之下,视觉语言跟踪结合了高级语义信息来解决边界框的模糊性,从而在实际应用中实现了更灵活、鲁棒和准确的跟踪。
- 标记序列构建策略不同。尽管SeqTrack和我们的工作都使用了短标记序列的构建策略,但我们减少了量化桶(quantization bins)的数量,并考虑了将语言标记纳入其中。这种增加的措施提高了在复杂场景中目标定位的鲁棒性。
具体方法
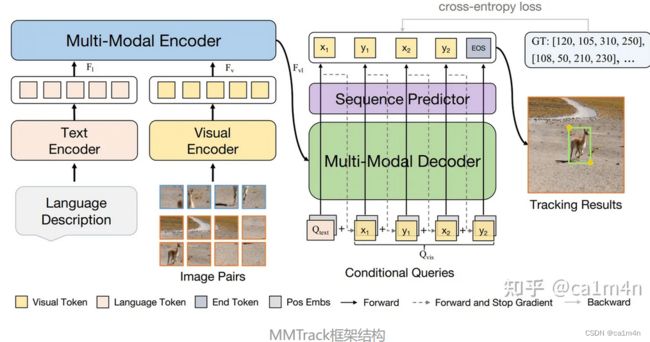
本文提出的MMTrack框架如上图,包含两个输入:图像对和语言描述。首先,通过文本编码器和视觉编码器分别来提取这两种类型输入的特征。为了提高计算效率,作者使用两个线性层,将两类特征的通道维度从C降到d。然后,将语言和视觉特征喂到多模态编码器中进行统一的VL表征学习,因为通过融合操作形成统一表示是实现多模态学习的关键。
为了构建条件查询,作者将文本嵌入和边界框进行分词(tokenize),生成多个一维标记序列,然后将它们连接起来得到条件查询。接下来,将条件查询和VL表示输入到多模态解码器中。按照 自回归
的方式,条件查询学习从VL表示中生成带有边界框信息的目标序列。
最后,作者设计了一个简单的与任务无关(task-agnostic)的序列头部,可以直接预测最终的跟踪结果。
a. 跨模态编码器

b.跨模态解码器
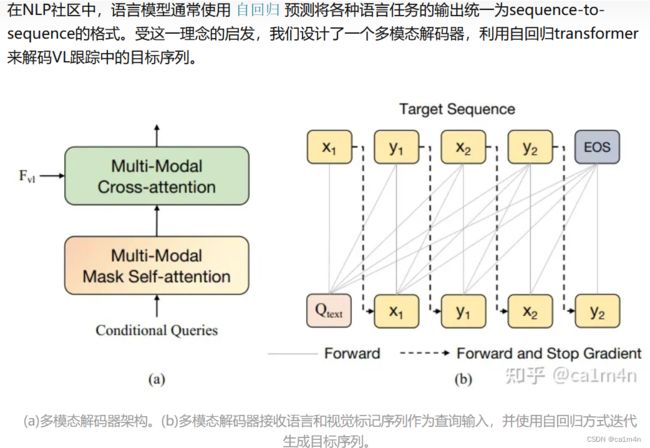
 在这种模式下,不同模态可以通过encoder-decoder架构在MMTrack中传播。多模态编码器负责更新VL表示,而多模态解码器以自回归方式预测离散坐标标记。我们可以看到,整个pipeline简单而灵活。
在这种模式下,不同模态可以通过encoder-decoder架构在MMTrack中传播。多模态编码器负责更新VL表示,而多模态解码器以自回归方式预测离散坐标标记。我们可以看到,整个pipeline简单而灵活。
c. 条件查询

x ~ = r o u n d ( x i s × K ) y ~ = r o u n d ( y i s × K ) \tilde{x}=round(\frac{x_i}{s}\times K) \ \tilde{y}=round(\frac{y_i}{s}\times K) x~=round(sxi×K) y~=round(syi×K)
d.不依赖特定任务的序列预测器

如上图所示,本文提出一个task-agnostic序列预测器,生成一个属性序列来描述目标实例。具体而言,在多模态解码器的顶部添加了三个连续的线性层,以进一步学习坐标token。预测头输出坐标token序列的概率,其中前4个最大分数的索引代表当前帧的目标定位。By doing so, 模型能够摆脱传统分类器的引导,降低预测头的设计复杂度。
效果
 表中数据红色是最优结果,蓝色次优。
表中数据红色是最优结果,蓝色次优。
可视化:复杂场景下的效果

与其他VL trackers的定性比较结果

failure case

无关结论
【多阅读多思考,有想法立刻写】相近领域或方向中,对最新方法的迁移和借鉴,比如单模态->多模态,检测->跟踪。
【绝对充分的实验】