diskqueue第四篇 - 怎么写入消息,怎么对外发送消息
diskqueue是nsq消息持久化的核心,内容较多,故分为多篇
1. diskqueue第一篇 - 是什么,为什么需要它,整体架构图,对外接口
2. diskqueue第二篇 - 元数据文件,数据文件,启动入口,元数据文件的读写及保存
3. diskqueue第三篇 - 数据定义详解,运转核心ioloop()源码详解
4. diskqueue第四篇 - 怎么写入消息,怎么对外发送消息
5. diskqueue第五篇 - 追尾检测,错误处理,如何正常关闭
6. diskqueue第六篇 - 如何使用diskqueue
第三篇博客中我们讲了diskqueue的定义,核心的ioloop()函数处理,这篇博客我们讲diskqueue对消息的写入,读取,对外发送等流程
1. diskqueue对写入消息时的处理
diskqueue对外提供的写入消息接口为
Put([]byte) error这个接口的实现不复杂,就是利用writeChan通道,把传进来的数据压入写入到当前在写文件,会提前检测,如果发现写入数据后当前文件会超上限,那就不写了,关闭当前的写文件,新开一个写入文件从0位置开始写
源码如下(已添加详细注释)
// 把指定数据压入接收队列
func (d *diskQueue) Put(data []byte) error {
d.RLock()
defer d.RUnlock()
// 如果队列正在退出,返回吧
if d.exitFlag == 1 {
return errors.New("exiting")
}
d.writeChan <- data // 压入接收队列,因为无缓冲,所以会阻塞等待ioloop()循环中取走才会返回
return <-d.writeResponseChan// 阻塞等待结果,ioloop()从writeChan读取执行后会立马出结果
}可以看到Put()函数操作很简单,核心操作就是往d.writeChan中压入数据,由于d.writeChan是无缓冲通道,所以会阻塞等待ioloop()函数中select的取走
ioloop()函数中select对此的处理如下
case dataWrite := <-d.writeChan: // 新接收到消息
count++ // 每收到一个消息,count值+1
d.writeResponseChan <- d.writeOne(dataWrite) // 消息写入到文件缓冲区,结果压入返回通道
select对此的处理也很简单,count值加1后,调用了d.writeOne(dataWrite),然后把writeOne()的结果写入writeResponseChan
我们看下writeOne()函数的处理,源码如下(已添加详细注释)
// 写入一个消息到缓冲区(函数内部会自动创建新文件)
func (d *diskQueue) writeOne(data []byte) error {
var err error
dataLen := int32(len(data)) // 数据长度
totalBytes := int64(4 + dataLen) // 本次写入的总字节数(4字节的数据长度 + 真正数据部分)
// 数据大小检测
if dataLen < d.minMsgSize || dataLen > d.maxMsgSize {
return fmt.Errorf("invalid message write size (%d) minMsgSize=%d maxMsgSize=%d", dataLen, d.minMsgSize, d.maxMsgSize)
}
// 如果加上本次写入量会超过文件最大限制,就关闭当前文件,创建新的
if d.writePos > 0 && d.writePos+totalBytes > d.maxBytesPerFile {
// 如果当前已经在读这个文件
if d.readFileNum == d.writeFileNum {
d.maxBytesPerFileRead = d.writePos // 标识当前文件的最大可读字节数即writePos(因为不再写入这个文件了,下面会往新文件里面写了)
}
d.writeFileNum++ // 新文件编号
d.writePos = 0 // 新文件的写入起始点
// 当前文件的内容刷到磁盘
err = d.sync()
if err != nil {
d.logf(ERROR, "DISKQUEUE(%s) failed to sync - %s", d.name, err)
}
// 关闭当前文件
if d.writeFile != nil {
d.writeFile.Close()
d.writeFile = nil
}
}
// 要写的文件还不存在,新建
if d.writeFile == nil {
// 格式化文件名
curFileName := d.fileName(d.writeFileNum)
// 创建文件
d.writeFile, err = os.OpenFile(curFileName, os.O_RDWR|os.O_CREATE, 0600)
if err != nil {
return err
}
d.logf(INFO, "DISKQUEUE(%s): writeOne() opened %s", d.name, curFileName)
// 如果已有写入位置
if d.writePos > 0 {
_, err = d.writeFile.Seek(d.writePos, 0) // 偏移文件游标,0表从文件开头进行偏移
if err != nil {
d.writeFile.Close()
d.writeFile = nil
return err
}
}
}
d.writeBuf.Reset()
// 先把数据长度(4字节)写入buf
err = binary.Write(&d.writeBuf, binary.BigEndian, dataLen)
if err != nil {
return err
}
// 再把数据写入buf
_, err = d.writeBuf.Write(data)
if err != nil {
return err
}
// 把buf写入(注意这里其实是写入到文件的缓冲区,并没有刷到磁盘中,只有调用writeFile.fsync()才是真正刷到磁盘)
_, err = d.writeFile.Write(d.writeBuf.Bytes())
if err != nil {
d.writeFile.Close()
d.writeFile = nil
return err
}
d.writePos += totalBytes // 更新写入位置
d.depth += 1 // 更新消息数
return err
}对上面的writeOne()函数源码解释下
1. 每个消息的前面4字节存放消息大小,每次写入数据 = 4字节 + 消息
2. 每个消息的大小需在当初设置的 minMsgSize 和 maxMsgSize之间
3. 如果加上本次写入量,在写文件会超最大限制,就关闭当前文件,writeFileNum+1后,新开一个文件从0写
4. 如果写入的文件还没打开,就打开文件
5. 写入消息流程:先写入4字节表消息大小,再写入消息
6. 最后更新写入位置,消息总数
2. diskqueue对读取消息时的处理
diskqueue对外提供的读取消息接口为
ReadChan() <-chan []byte具体实现如下
// 返回读消息的通道(外部只读)
func (d *diskQueue) ReadChan() <-chan []byte {
return d.readChan
}也就是返回d.readChan,这是一个只读的通道,元素类型为[]byte
大家回顾下初始化diskqueue时New()函数,d.readChan是一个无缓冲的通道,如下

所以往d.readChan中压入数据后,必须等待外部读取后才能返回
为了避免阻塞,压入方,读取方都是在select中执行
好了,我们看diskqueue对readChan是怎么使用的吧
再回顾下ioloop()循环中对于,读通道,读消息的处理
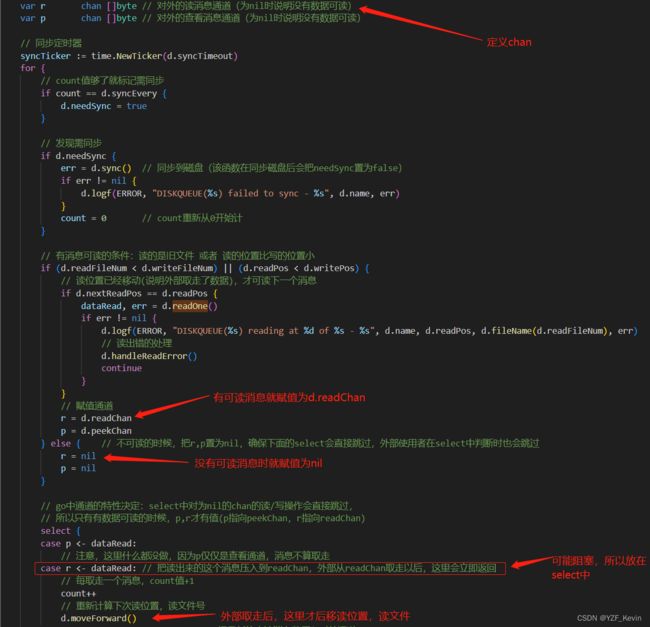
当时也讲了,这里充分利用了golang中通道的特性,select对于为nil的通道会直接跳过
核心点:
1. 有消息可读时,就给r赋值为d.readChan,读取到的数据dataRead就能压入到r
2. 无消息可读时,r就会被赋值为nil,select会直接跳过。外部的读取发现通道为nil也会直接跳过
现在我们看下消息可读条件的判断,两个条件:
1. d.readFileNum < d.writeFileNum 即读的是已写入完成的文件,当然可以放心读
2. d.readPos < d.writePos 即读写的是同一个文件,但读的位置比写的位置小,说明已经有消息写入后未处理,也可以读
好,下面开始看真正的读取消息函数readOne(),源码如下(已加详细注释)
// 读取一个最早的消息,以[]byte格式返回
func (d *diskQueue) readOne() ([]byte, error) {
var err error
var msgSize int32
// 没有读文件指针,那就新打开文件
if d.readFile == nil {
curFileName := d.fileName(d.readFileNum) // 要读的文件名字
// 以只读的方式打开文件
d.readFile, err = os.OpenFile(curFileName, os.O_RDONLY, 0600)
if err != nil {
return nil, err
}
d.logf(INFO, "DISKQUEUE(%s): readOne() opened %s", d.name, curFileName)
// 跳到读的游标点
if d.readPos > 0 {
_, err = d.readFile.Seek(d.readPos, 0)
if err != nil {
d.readFile.Close()
d.readFile = nil
return nil, err
}
}
// 赋值当前文件的最大可读字节数
d.maxBytesPerFileRead = d.maxBytesPerFile // 默认是文件极限值
// 如果是已写完的文件,必须要用实际文件大小
if d.readFileNum < d.writeFileNum {
stat, err := d.readFile.Stat()
if err == nil {
d.maxBytesPerFileRead = stat.Size()
}
}
// 使用文件对象构建reader
d.reader = bufio.NewReader(d.readFile)
}
// 先读消息大小(大端方式,4字节)
err = binary.Read(d.reader, binary.BigEndian, &msgSize)
if err != nil {
d.readFile.Close()
d.readFile = nil
return nil, err
}
// 如果消息大小错误,报错返回吧
if msgSize < d.minMsgSize || msgSize > d.maxMsgSize {
d.readFile.Close()
d.readFile = nil
return nil, fmt.Errorf("invalid message read size (%d)", msgSize)
}
// 再读消息体
readBuf := make([]byte, msgSize)
_, err = io.ReadFull(d.reader, readBuf)
if err != nil {
d.readFile.Close()
d.readFile = nil
return nil, err
}
totalBytes := int64(4 + msgSize)
d.nextReadPos = d.readPos + totalBytes // 更新下次读取点(不能直接把readPos后移,是因为消息由外部接收了才算处理,那时候readPos才能往后移;外部没接收的话,)
d.nextReadFileNum = d.readFileNum // 更新下次读取文件名(默认还是本文件,是否跳新文件下面判断)
// 如果是之前已写完的文件,并且下次读取点超过本文件可读最大值,说明已经读完了,那下次就读下一个文件
if d.readFileNum < d.writeFileNum && d.nextReadPos >= d.maxBytesPerFileRead {
// 关闭当前文件
if d.readFile != nil {
d.readFile.Close()
d.readFile = nil
}
d.nextReadFileNum++ // 标记下次读新文件
d.nextReadPos = 0 // 新文件肯定从0开始读了
}
return readBuf, nil
}对上面的代码解释下
1. readFile为nil,说明指向的文件还没打开,就执行打开操作,再调用seek()函数跳转到读取位置
2. 取到readFile指向文件的实际大小,如果是已经写完的文件,则需标记只能读这么多
3. 读消息时,先读4字节表消息大小,再读消息体
4. 计算出下次的读取点(但不可直接后移,需等外面取走数据),如果超过了当前文件最大可读值,就读下一个文件
3. 本篇总结
这篇博客,我们详细讲了diskqueue的写入消息,读取消息,对外发送消息的机制