微调文本到图像扩散模型新方法DreamBooth,实现主题驱动生成(CVPR 2023)
来源:投稿 作者:橡皮
编辑:学姐

论文链接: https://arxiv.org/pdf/2208.12242
项目主页:https://dreambooth.github.io/

图1. 只需要拍摄某个主题(左)的几张图像(通常为 3-5 张),DreamBooth(我们的人工智能照相亭)就可以使用文本提示的指导,在不同的环境中生成该主题的无数图像(右) 。结果展示了与环境的自然相互作用,以及新颖的清晰度和照明条件的变化,同时保持了对主体的关键视觉特征的高保真度。
摘要:
大型文本到图像模型在人工智能的发展中实现了显着的飞跃,能够根据给定的文本提示合成高质量和多样化的图像。然而,这些模型缺乏在给定参考集中模仿受试者外观并在不同背景下合成它们的新颖表现的能力。
在这项工作中,我们提出了一种文本到图像扩散模型“个性化”的新方法。给定一个主题的几张图像作为输入,我们对预训练的文本到图像模型进行微调,使其学会将唯一标识符与该特定主题绑定。一旦将主体嵌入到模型的输出域中,就可以使用唯一标识符来合成不同场景中主体的新颖的真实感图像。通过利用模型中嵌入的语义先验和新的自生类特定先验保留损失,我们的技术能够合成参考图像中未出现的不同场景、姿势、视图和照明条件中的主题。
我们将我们的技术应用于几个以前无懈可击的任务,包括主题重新上下文化、文本引导视图合成和艺术渲染,同时保留主题的关键特征。我们还为主题驱动生成的新任务提供了新的数据集和评估协议。
1.引言
您能想象您自己的狗环游世界,或者您最喜欢的包在巴黎最独特的陈列室中展示吗?你的鹦鹉成为插图故事书的主角怎么样?渲染此类想象场景是一项具有挑战性的任务,需要在新的上下文中合成特定主题(例如物体、动物)的实例,以便它们自然、无缝地融入场景中。
最近开发的大型文本到图像模型通过基于自然语言编写的文本提示实现高质量和多样化的图像合成,显示出前所未有的功能。此类模型的主要优点之一是从大量图像标题对中学习到的强语义先验。例如,这样的先验学习将“狗”这个词与可以以不同姿势和上下文出现在图像中的各种狗实例绑定在一起。虽然这些模型的综合能力是前所未有的,但它们缺乏在给定参考集中模仿受试者外观的能力,也缺乏在不同背景下合成同一受试者的新颖表现的能力。主要原因是它们的输出域的表达能力有限;即使是对一个对象最详细的文字描述也可能产生具有不同外观的实例。此外,即使模型的文本嵌入位于共享语言视觉空间,也无法准确地重建给定主体的外观,而只能创建图像内容的变化(图 2)。

图 2. 主题驱动的生成。给定一个特定的时钟(左),很难在保持其关键视觉特征的高保真度的同时生成它(第二列和第三列显示 DALL-E 2图像引导生成和 Imagen文本引导生成;使用文本提示对于 Imagen:“复古风格的黄色闹钟,带有白色钟面,丛林中钟面右侧有一个黄色数字 3”)。我们的方法(右)可以在新的上下文中以高保真度合成时钟(文本提示:“丛林中的 [V] 时钟”)。
在这项工作中,我们提出了一种文本到图像扩散模型“个性化”的新方法(使其适应用户特定的图像生成需求)。我们的目标是扩展模型的语言视觉词典,以便将新单词与用户想要生成的特定主题绑定在一起。一旦将新词典嵌入到模型中,它就可以使用这些单词来合成主题的新颖的真实感图像,并将其置于不同的场景中,同时保留其关键的识别特征。其效果类似于“神奇照相亭”,一旦拍摄了几张拍摄对象的图像,照相亭就会根据简单直观的文本提示生成拍摄对象在不同条件和场景下的照片(图 1)。
更正式地说,给定一个主题(约3-5张)的一些图像,我们的目标是将主题植入到模型的输出域中,以便可以用唯一的标识符来合成它。为此,我们提出了一种技术,用罕见的标记标识符来表示给定的主题,并微调预先训练的、基于扩散的文本到图像框架。
我们使用输入图像和文本提示来微调文本到图像模型,其中包含唯一标识符,后跟主题的类名称(例如,“A [V] dog”)。后者使模型能够使用其关于主题类的先验知识,而特定于类的实例与唯一标识符绑定。为了防止语言漂移导致模型将类名(例如“dog”)与特定实例相关联,我们提出了一种自生的、特定于类的先验保留损失,它利用了语义先验嵌入模型中的类,并鼓励它生成与我们的主题相同的类的不同实例。
我们将我们的方法应用于无数基于文本的图像生成应用程序,包括主题的重新上下文化、其属性的修改、原创艺术再现等等,为以前无懈可击的新任务铺平了道路。我们通过消融研究强调了我们方法中每个组成部分的贡献,并与替代基线和相关工作进行比较。我们还进行了一项用户研究,以评估合成图像中的主题和提示保真度,与其他方法进行比较。
据我们所知,我们的技术是第一个解决主题驱动生成这一新的挑战性问题的技术,允许用户从一些随意捕捉的主题图像中合成该主题在不同背景下的新颖再现,同时保持其特色鲜明。
为了评估这个新任务,我们还构建了一个新的数据集,其中包含在不同上下文中捕获的各种主题,并提出了一个新的评估协议来衡量主题保真度和生成结果的提示保真度。我们在项目网页上公开提供我们的数据集和评估协议。
2.方法
只给定一些(通常是 3-5 个)随意捕获的特定主题的图像,没有任何文本描述,我们的目标是生成具有高细节保真度和文本提示引导的变化的主题新图像。示例变化包括改变主体位置、改变主体属性(例如颜色或形状)、修改主体的姿势、视点和其他语义修改。我们不对输入图像捕获设置施加任何限制,并且主题图像可以具有不同的上下文。接下来,我们提供一些关于文本到图像扩散模型的背景(第 2.1 节),然后介绍我们的微调技术,将唯一标识符与一些图像中描述的主题绑定(第 2.2 节),最后提出一个特定于类的先验-保存损失使我们能够克服微调模型中的语言漂移(第 2.3 节)。
2.1 文本到图像的扩散模型

2.2 文本到图像模型的个性化
我们的第一个任务是将主题实例植入到模型的输出域中,以便我们可以在模型中查询主题的各种新颖图像。一种自然的想法是使用主题的少镜头数据集来微调模型。在几次场景中微调 GAN 等生成模型时必须小心谨慎,因为它可能会导致过度拟合和模式崩溃,并且无法很好地捕获目标分布。人们已经对避免这些陷阱的技术进行了研究,尽管与我们的工作相反,这一工作主要是寻求生成类似于目标分布的图像,但不需要保留主题。关于这些陷阱,我们观察到一个特殊的发现:如果使用方程 1 中的扩散损失进行仔细的微调设置,大型文本到图像的扩散模型似乎擅长将新信息集成到其领域中,而不会忘记先前的信息或过度拟合一小组训练图像。
为少样本个性化设计提示。我们的目标是将新的(唯一标识符、主题)对“植入”到扩散模型的“字典”中。为了绕过为给定图像集编写详细图像描述的开销,我们选择一种更简单的方法,并将主题的所有输入图像标记为“a [identifier] [class noun]”,其中 [identifier] 是链接的唯一标识符到主题,[类名词]是主题的粗略类描述符(例如猫,狗,手表等)。类描述符可以由用户提供或使用分类器获得。我们在句子中使用类描述符,以便将类的先验与我们独特的主题联系起来,并发现使用错误的类描述符或没有类描述符会增加训练时间和语言漂移,同时降低性能。本质上,我们寻求利用模型的特定类别的先验,并将其与对象的唯一标识符的嵌入结合起来,这样我们就可以利用视觉先验来生成对象在不同上下文中的新姿势和关节。

2.3 特定类别的先验保存损失
根据我们的经验,通过微调模型的所有层可以获得最大主题保真度的最佳结果。这包括以文本嵌入为条件的微调层,这会引起语言漂移的问题。语言漂移一直是语言模型中观察到的问题,在大型文本语料库上预先训练并随后针对特定任务进行微调的模型会逐渐丢失语言的句法和语义知识。据我们所知,我们是第一个发现影响扩散模型的类似现象,其中模型慢慢忘记了如何生成与目标主题相同类别的主题。
另一个问题是输出多样性可能减少。文本到图像的扩散模型自然具有大量的输出多样性。当对一小组图像进行微调时,我们希望能够以新颖的视角、姿势和清晰度生成主题。然而,存在减少对象的输出姿势和视图的可变性的风险(例如捕捉到少数镜头视图)。我们观察到这种情况经常发生,尤其是当模型训练时间过长时。

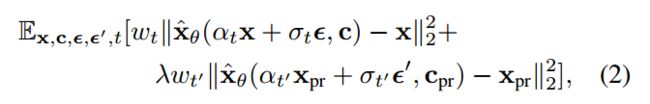
其中第二项是先验保留项,它用自己生成的图像来监督模型,并且 λ 控制该项的相对权重。图 3 说明了使用类生成的样本和先验保留损失进行的模型微调。尽管很简单,但我们发现这种预先保留的损失对于鼓励输出多样性和克服语言漂移是有效的。我们还发现,我们可以训练模型进行更多次迭代,而不会面临过度拟合的风险。我们发现,对于 Imagen 和 5×10−6 的稳定扩散,λ = 1 和学习率 10−5 的 ∼ 1000 次迭代,以及 3-5 个图像的主题数据集大小足以实现良好的效果结果。在此过程中,生成了约 1000 个“a [类名词]”样本 - 但可以使用的样本较少。 Imagen 的训练过程在 TPUv4 上大约需要 5 分钟,稳定扩散在 NVIDIA A100 上大约需要 5 分钟。
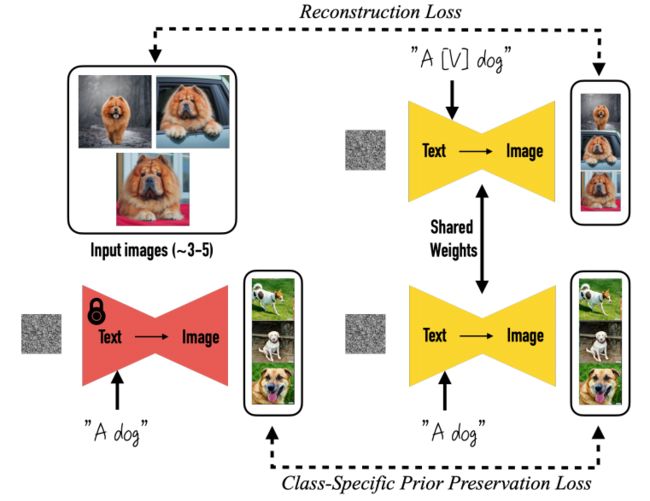
图 3. 微调。给定 ∼ 3−5 个主题的图像,我们对文本到图像的扩散模型进行微调,其中输入图像与包含唯一标识符和主题所属类名称的文本提示配对(例如,“A [V]狗”),同时,我们应用特定于类的先验保留损失,它利用模型在类上的语义先验,并鼓励它使用文本提示中的类名生成属于主题类的不同实例(例如,“一只狗”)。
3.实验
在本节中,我们将展示实验和应用。我们的方法可以对我们的主题实例进行大量文本引导的语义修改,包括重新语境化、主题属性(例如材料和物种)的修改、艺术再现和观点修改。重要的是,在所有这些修改中,我们能够保留赋予主题其身份和本质的独特视觉特征。如果任务是重新情境化,则主题特征不会被修改,但外观(例如姿势)可能会改变。如果任务是更强的语义修改,例如我们的主题和另一个物种/对象之间的交叉,那么修改后主题的关键特征将被保留。在本节中,我们使用 [V] 引用主体的唯一标识符。我们在支持材料中包含了特定的 Imagen 和稳定扩散实现细节。

图 4. 与文本反转的比较 给定 4 个输入图像(顶行),我们比较:DreamBooth Imagen(第二行)、DreamBooth Stable Diffusion(第三行)、文本反转(底行)。使用以下提示创建输出图像(从左到右):“雪中的 [V] 花瓶”、“海滩上的 [V] 花瓶”、“丛林中的 [V] 花瓶”、“[ V] 以埃菲尔铁塔为背景的花瓶”。 DreamBooth 在主题保真度和提示保真度方面都更强。
3.1 数据集和评估
数据集。我们收集了 30 个主题的数据集,包括独特的物体和宠物,如背包、毛绒动物、狗、猫、太阳镜、卡通等。我们将每个主题分为两类:物体和活体主题/宠物。 30 个对象中有 21 个是物体,9 个是活体对象/宠物。
图 5. 数据集。我们提出的数据集中每个主题的示例图像。
我们为图 5 中的每个主题提供了一张示例图像。该数据集的图像由作者收集或源自 Unsplash。我们还收集了25个提示:20个重新上下文化提示和5个对象属性修改提示;针对实时对象/宠物的 10 个重新情境化、10 个配件和 5 个属性修改提示。完整的提示列表可以在补充材料中找到。
对于评估套件,我们为每个主题和每个提示生成四张图像,总共 3,000 张图像。这使我们能够稳健地衡量方法的性能和泛化能力。我们在项目网页上公开提供我们的数据集和评估协议,以便将来用于评估主题驱动的生成。
评估指标。评估的一个重要方面是主题保真度:生成图像中主题细节的保留。为此,我们计算两个指标:CLIP-I 和 DINO。 CLIP-I 是生成图像和真实图像的 CLIP嵌入之间的平均成对余弦相似度。尽管该指标已在其他工作中使用,但它并不是为了区分可能具有高度相似的文本描述的不同主题(例如,两个不同的黄色时钟)。我们提出的 DINO 度量是生成图像和真实图像的 ViTS/16 DINO 嵌入之间的平均成对余弦相似度。这是我们首选的指标,因为通过构建并与监督网络相比,DINO 并未经过训练来忽略同一类别的受试者之间的差异。相反,自我监督的训练目标鼓励区分主题或图像的独特特征。评估的第二个重要方面是提示保真度,以提示嵌入和图像 CLIP 嵌入之间的平均余弦相似度来衡量。我们将其表示为 CLIP-T。
3.2 对比
我们使用他们工作中提供的超参数将我们的结果与 Gal 等人最近同时进行的工作文本反转进行比较。我们发现这部作品是文献中唯一一部主题驱动、文本引导并生成新颖图像的可比作品。我们使用 Imagen 为 DreamBooth、使用稳定扩散的 DreamBooth 和使用稳定扩散的文本反转生成图像。我们计算 DINO 和 CLIP-I 主题保真度指标以及 CLIP-T 提示保真度指标。在表 1 中,我们显示了 DreamBooth 与文本倒置在主题和提示保真度指标方面存在相当大的差距。我们发现 DreamBooth (Imagen) 在主题保真度和提示保真度方面都比 DreamBooth (Stable Diffusion) 获得了更高的分数,接近真实图像主题保真度的上限。我们认为这是由于Imagen具有更大的表达能力和更高的输出质量。
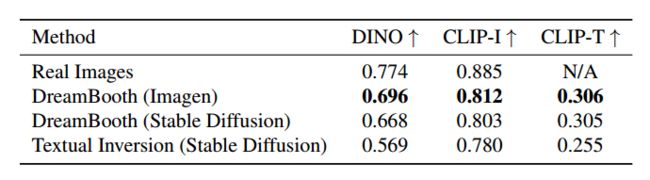
表 1. 受试者保真度(DINO、CLIP-I)和提示保真度(CLIP-T、CLIP-T-L)定量指标比较。

表 2. 主题保真度和提示保真度用户偏好。
此外,我们通过进行用户研究来比较 Textual Inversion(稳定扩散)和 DreamBooth(稳定扩散)。为了主题保真度,我们要求 72 位用户回答了 25 个比较问题的问卷(每份问卷 3 位用户),总共 1800 个答案。样本是从一个大池中随机选择的。每个问题都会显示一个主题的一组真实图像,以及通过每种方法(带有随机提示)生成的该主题的一个图像。用户被要求回答这个问题:“这两个图像中哪一个最好地再现了参考项目的身份(例如项目类型和详细信息)?”,我们包括一个“无法确定/两者相同”选项。同样,为了保证提示保真度,我们会问“参考文本最好地描述了两个图像中的哪一个?”。我们使用多数投票对结果进行平均,并将其呈现在表 2 中。我们发现,在主题保真度和提示保真度方面,人们对 DreamBooth 有着压倒性的偏好。这揭示了表 1 中的结果,其中 DINO 大约 0:1 的差异和 CLIP-T 0:05 的差异在用户偏好方面是显着的。最后,我们在图 4 中显示了定性比较。我们观察到 DreamBooth 更好地保留了受试者身份,并且更忠实于提示。我们在支持材料中展示了用户研究的样本。
3.3 消融实验
先验保存损失消融。我们在数据集中的 15 个受试者上对 Imagen 进行微调,无论是否有我们提出的先前保存损失 (PPL)。先验保留损失旨在对抗语言漂移并保留先验。我们通过计算先验类别的随机受试者的生成图像和特定受试者的真实图像之间的平均成对 DINO 嵌入来计算先验保留度量(PRES)。该指标越高,该类的随机主题与我们的特定主题越相似,表明先验的崩溃。我们在表 3 中报告了结果,并观察到 PPL 大大抵消了语言漂移,并有助于保留生成前一类的不同图像的能力。此外,我们使用相同提示下同一主题生成的图像之间的平均 LPIPS余弦相似度来计算多样性度量(DIV)。我们观察到,使用 PPL 训练的模型实现了更高的多样性(主题保真度略有下降),这也可以在图 6 中定性地观察到,其中使用 PPL 训练的模型对参考图像的环境的过度拟合程度较低,并且可以在更加多样化的姿势和关节。

图 6.通过预先保存损失来鼓励多样性。单纯的微调可能会导致对输入图像上下文和主体外观(例如姿势)的过度拟合。 PPL 充当正则化器,可以缓解过度拟合并鼓励多样性,从而允许更多的姿势可变性和外观多样性。
类别先验消融。我们在没有类名词、随机采样的不正确类名词和正确类名词的数据集主题子集(5 个主题)上对 Imagen 进行微调。有了适合我们主题的正确类名词,我们就能够忠实地适应该主题,利用先验类,使我们能够在各种上下文中生成我们的主题。当使用不正确的类名词(例如背包的“can”)时,我们会在我们的主语和前一类之间发生争论 - 有时会获得圆柱形背包,或其他畸形的主语。如果我们在没有类名词的情况下进行训练,则模型不会利用类先验,难以学习主题和收敛,并且可能会生成错误的样本。主题保真度结果如表 4 所示,我们提出的方法的主题保真度要高得多。

表 3. 先前保留损失 (PPL) 消融显示先前保留 (PRES) 指标、多样性指标 (DIV) 以及主题和提示保真度指标。

表 4. 使用主题保真度指标进行类名消融。
3.4 应用
重新语境化: 我们可以通过描述性提示(“a [V] [类名词] [语境描述]”)在不同语境中为特定主题生成新颖的图像(图 7)。重要的是,我们能够以新的姿势和关节生成主题,具有以前未见过的场景结构和主题在场景中的真实集成(例如接触、阴影、反射)。
图 7.重新语境化。我们生成不同环境中主体的图像,高度保留主体细节和真实的场景与主体交互。我们在每个图像下方显示提示。
艺术再现: 给出提示“[著名画家]风格的[V][类名词]的绘画”或“[著名雕塑家]风格的[V][类名词]的雕像”,我们能够对我们的主题进行艺术演绎。与保留源结构而仅转移风格的风格转移不同,我们能够根据艺术风格生成有意义的、新颖的变化,同时保留主题身份。例如,如图 8“米开朗基罗”所示,我们生成了一个新颖且在输入图像中未见的姿势。
新视角合成: 我们能够在新颖的观点下呈现主题。在图 8 中,我们在新的视点下生成输入猫的新图像(具有一致的复杂毛皮图案)。我们强调,该模型没有从后面、下面或上面看到这只特定的猫 - 但它能够在仅给出该主题的 4 个正面图像的情况下,从类中推断出知识,从而生成这些新颖的视图。
属性修改: 我们可以修改主体属性。例如,我们在图 8 的底行中显示了特定松狮犬与不同动物物种之间的杂交。我们用以下结构的句子提示模型:“[V] 狗与 [目标物种] 的杂交” ”。特别是,我们可以在这个例子中看到,即使物种发生变化,狗的身份也得到了很好的保留——狗的面部具有某些独特的特征,这些特征得到了很好的保存并与目标物种融合在一起。其他属性修改也是可能的,例如材料修改(例如图 7 中的“透明 [V] 茶壶”)。有些比其他更难,并且取决于基础生成模型的先验。

图 8.新颖的视图合成、艺术表现和属性修改。我们能够生成新颖且有意义的图像,同时忠实地保留主题身份和本质。
3.5 局限性
我们在图 9 中说明了我们的方法的一些失败模型。第一个与无法准确生成提示上下文有关。可能的原因是这些上下文的先验较弱,或者由于训练集中共现的概率较低而难以同时生成主题和指定概念。第二种是上下文-外观纠缠,即主体的外观因提示上下文而发生变化,如图 9 中背包的颜色变化所示。第三,我们还观察到当提示与看到主题的原始设置相似时,会发生与真实图像的过度拟合。其他限制是某些科目比其他科目更容易学习(例如狗和猫)。有时,对于较罕见的主题,该模型无法支持尽可能多的主题变体。最后,对象的保真度也存在变化,并且一些生成的图像可能包含幻觉的对象特征,具体取决于模型先验的强度以及语义修改的复杂性。

图 9. 故障模式。给定一个罕见的提示上下文,模型可能无法生成正确的环境 (a)。上下文和主题外观可能会纠缠在一起(b)。最后,模型可能会过度拟合并生成与训练集相似的图像,特别是如果提示反映了训练集的原始环境(c)。
4.总结
我们提出了一种使用主题的一些图像和文本提示的指导来合成主题的新颖再现的方法。我们的关键思想是通过将主题绑定到唯一标识符来将给定的主题实例嵌入到文本到图像扩散模型的输出域中。值得注意的是,这种微调过程只需 3-5 个主题图像即可发挥作用,使得该技术特别容易使用。我们在生成的逼真场景中演示了动物和物体的各种应用,在大多数情况下与真实图像无法区分。
关注下方《学姐带你玩AI》
回复“CVPR”免费领取500+篇顶会论文合集
码字不易,欢迎大家点赞评论收藏!